引言
特征缩放是机器学习预处理数据中最重要的步骤之一,它有时能决定学习模型的好坏。
特征缩放的作用如下:
- 加快梯度下降
- 提升模型精度(消除不同量纲)
- 防止梯度爆炸(消除过大值的影响)
为什么要特征缩放
在机器学习算法处理数据时通常是忽略数据的单位信息的,或者说不知道这些数据代表什么。比如50kg和50公里代表着两个不同的度量,人类是很容易区分它们的。但是对于机器来说,这两个数据是一样的。
import pandas as pd
import numpy as np
data = np.array([[1,172,30000],[2,160,60000],[3,175,50000],[4,180,5000]])
df = pd.DataFrame(data,columns=['staff','height','salary'])
df
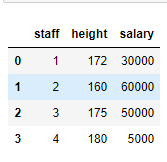
我们来看下上面的表格,上面是员工身高与薪水的表格。我们人类看到数字172(cm)知道就是身高,看到5000知道肯定是薪水。但是机器就不知道。
假设用神经网络来学习这份数据,那么就会导致取值范围更大的薪水会主导模型的训练,也就是模型会偏向于薪水,但通常我们不希望我们的算法一开始就偏向于某个特征。
假设我们尝试计算两个员工的欧氏距离,在特征缩放之前的结果是:
员工1和员工2的距离:
员工2和员工3的距离:
从上面的结果可以看到它们的距离基本上就是薪水的差值。
而在经过最大最小值归一化后(下文会讲到)的结果是:
员工1和员工2的距离:
员工2和员工3的距离:
显然经过特征缩放后的结果更具有可比性。
这个问题不仅会出现在神经网络里面,还会出现在任何基于距离计算的算法中。特征缩放就可以解决这个问题。
特征缩放有哪些方法
有很多种特征缩放的方法,我们一一来分析。
均值归一化(Mean Normalization)
将数值范围缩放到 区间里,数据的均值变为
以上面的例子说明,假设我们要均值归一化员工1的薪水。那么
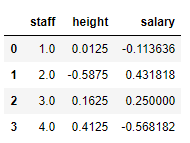
下面是对薪水和身高进行均值归一化的结果:
data_mean = data[:,1:]
data_mean = (data_mean - data_mean.mean(axis=0)) / (data_mean.max(axis=0) - data_mean.min(axis=0))
pd.DataFrame(np.c_[np.arange(1,5),data_mean],columns=['staff','height','salary'])
最大最小值归一化(Min-Max Normalization)
最大最小值归一化简称为归一化,将数值范围缩放到 区间里
以上面的例子说明,假设我们要最大最小值归一化员工1的薪水。那么
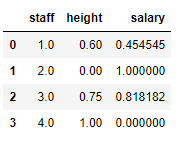
下面是对薪水和身高进行均最大最小值归一化的结果:
data_min_max = data[:,1:]
data_min_max = (data_min_max - data_min_max.min(axis=0)) / (data_min_max.max(axis=0) - data_min_max.min(axis=0))
pd.DataFrame(np.c_[np.arange(1,5),data_min_max],columns=['staff','height','salary'])
标准化/z值归一化(Standardization/Z-Score Normalization)
标准化又叫z值归一化,将数值缩放到0附近,且数据的分布变为均值为0,标准差为1的标准正态分布。
是
的标准差,计算公式为:
以上面的例子说明,假设我们要标准化员工1的薪水。那么
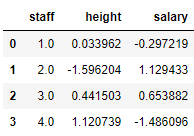
下面是对薪水和身高进行标准化的结果:
data_std = data[:,1:]
data_std = (data_std - data_std.mean(axis=0)) / (data_std.std(axis=0))
pd.DataFrame(np.c_[np.arange(1,5),data_std],columns=['staff','height','salary'])
常见问题&注意事项
哪些算法需要特征缩放
特征缩放对基于距离的算法特别重要。因此像KNN、线性回归、逻辑回归、SVM等都需要特征缩放。
不基于距离的算法像朴素贝叶斯以及基于树结构的算法(决策树、随机森林)等不需要特征缩放。
另外,0/1取值的特征不需要归一化。
归一化还是标准化
- 如果你知道数据分布不是正态分布,那么使用归一化。像用在KNN和NN这种不假设数据分布的算法就很合适。 最大最小值归一化容易受异常值影响,常用于归一化图像的灰度值。
- 当数据是正态分布时进行标准化是很有帮助的,不像归一化,标准化的数据没有限定范围,对异常值不敏感。
- 然后,具体的选择还是依赖于你的数据或算法,通常最好归一化和标准化都尝试一下,看哪种方法好。
注意事项
需要先把数据拆分成训练集与验证集,在训练集上计算出需要的数值(如均值和标准值),对训练集数据做标准化/归一化处理(不要在整个数据集上做标准化/归一化处理,因为这样会将验证集的信息带入到训练集中,这是一个非常容易犯的错误),然后再用之前计算出的数据(如均值和标准值)对验证集数据做相同的标准化/归一化处理。
参考
- https://www.cnblogs.com/HuZihu/p/9761161.html
- https://www.analyticsvidhya.com/blog/2020/04/feature-scaling-machine-learning-normalization-standardization
- https://machinelearningknowledge.ai/feature-scaling-machine-learning/