什么是特征缩放:
就是将所有数据映射到同一尺度。如:
某训练集 x_train 为:

(x_trian)
将其进行某种特征缩放之后,得到新的值:
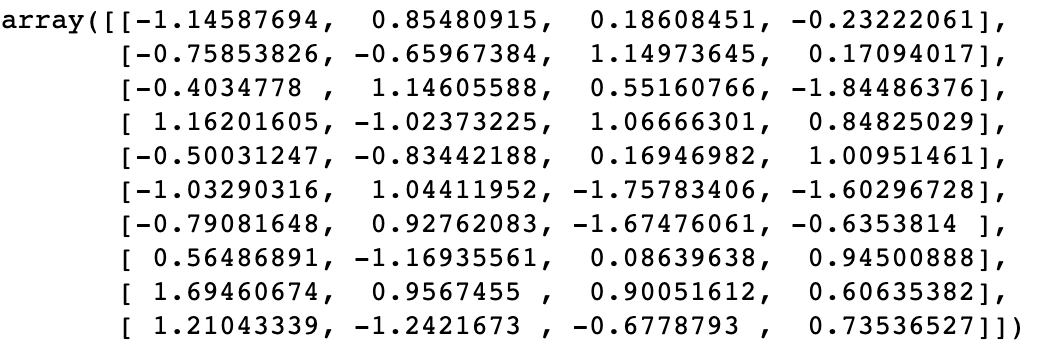
显然经过特征缩放之后,特征值变小了
为什么要进行特征缩放呢?
有些特征的值是有区间界限的,如年龄,体重。而有些特征的值是可以无限制增加,如计数值。
所以特征与特征之间数值的差距会对模型产生不良影响。如:

在该样本集中,由于量纲不同,模型受 '次数'特征所主导。因此如果没有对数据进行预处理的话
有可能带来偏差,难以较好的反应特征之间的重要程度。其实还有利于优化的其他原因
特征缩放的分类:
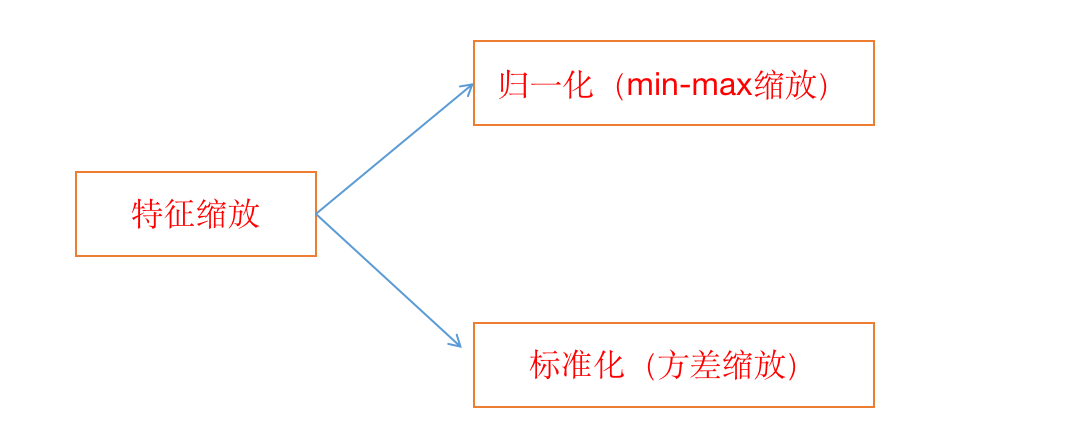
(不止这两种,但常用的为标准化)
1.先看一下 归一化(min-max 缩放)
通过归一化处理,将值映射到0-1之间的某个数值。
公式:
![]()
X(i)为某个特征值、X(min)为这个特征的所有特征值的最小值、X(max)为这个特征
的所有特征值的最大值
也就是将 (某个特征值减去特征最小值的差)除以 (特征最大值减去特征最小值的差)
从而得到这个特征值归一化之后的数值。

Python简单实现:
import numpy as np def min_max_scaler(X): '''归一化''' assert X.ndim == 2,'必须为二维数组' X = np.array(X,dtype=float) n_feature = X.shape[1] for n in range(n_feature): min_feature = np.min(X[:,n]) max_feature = np.max(X[:,n]) X[:, n] = (X[:,n] - min_feature) / (max_feature - min_feature) return X x = np.random.randint(0,100,(25,4)) print(min_max_scaler(x))
'''
[[0.89247312 0.11494253 0.17857143 0.29347826]
[0.09677419 0.74712644 0.10714286 0.63043478]
[0. 0.87356322 0.95238095 0.67391304]
.......
[0.2688172 0.4137931 0.33333333 0.89130435]
[0.11827957 0.7816092 0.55952381 0.15217391]
[1. 0.57471264 0.70238095 0.45652174]
[0.16129032 1. 0.75 0.23913043]]
'''
sklearn中对应API: from sklearn.preprocessing import MinMaxScaler
