本人大一,今年2017最后一天,准备做点这学期学的算法一点总结,当做复习吧。
一周前看见了贪吃蛇AI算法,受到震撼于是就把以前的win32贪吃蛇加了个AI实现,让我这个渣渣写了好几天才完工 ,终于能吃完全屏了,虽然离自己看的那个贪吃蛇AI的gif还有些距离emmmm,贪吃蛇AI不可避免的用到了寻路算法,所以今天当做复习总结提一提,
,终于能吃完全屏了,虽然离自己看的那个贪吃蛇AI的gif还有些距离emmmm,贪吃蛇AI不可避免的用到了寻路算法,所以今天当做复习总结提一提,
何为盲目?何为启发?。举个例子,加入你在学校操场,老师叫你去国旗那集合,你会怎么走?
假设你是瞎子,你看不到周围,那如果你运气差,那你可能需要把整个操场走完才能找到国旗。这便是盲目式搜索,即使知道目标地点,你可能也要走完整个地图。
假设你眼睛没问题,你看得到国旗,那我们只需要向着国旗的方向走就行了,我们不会傻到往国旗相反反向走,那没有意义。
这种有目的的走法,便被称为启发式的。
而今天要提到的深度优先跟广度优先,便是盲目式搜索,而A*跟IDA*,便是启发式搜索。
盲目式搜索
DFS
深度优先(DFS)正如他的名字,每次先往深度走,如果此路走到底都没找到,退回到原点,换另一条路找,如果走到底还是没找到,继续换一条路,直到全部路走完。
DFS由于每次向深处搜索然后返回,很容易就让人想到用栈实现,而系统本来就有提供栈,即用递归实现。DFS函数里,一般都是在一个循环调用自己完成递归过程,如果用迷宫比喻的话,每次递归返回便是走完一条路,而这个循环便是有多少条路,这样每个路口都会实现同样的操作,便能把整个迷宫搜索完。因其每次会返回的特点DFS在枚举算法里也称为回溯法,DFS走的路径被称为解答树。下面的图中,只有(1,3,0,2)跟(2,0,3,1)是到达了目标,其他都是死路

BFS
广度优先(BFS)是,每次先搜索周围,先把原点方圆1m找完,如果找不到,就找再向外扩展1m,如果找不到,就再向外扩展1m,每次扩大自己的圈子,直到整个地图走完。很像传染病,从开始一个点慢慢传染到整个地区
BFS则是用队列实现跟循环实现,每次把当前节点周围的节点加入队列,然后pop出队列,不断循环,直到队列为空。一种用递归一种用循环,很明显,在时间上,深度优先搜索一般要比广度优先搜索慢,但广度优先搜索需要大量的空间。所以说这两种算法各有优缺点。
在说启发式搜索之前,先说说寻路算法
寻路算法
一般要到终点,我们会关注两件事,要走多远以及这条路要怎么走。然后为了不重复走过的路,我们还需要标记这条路已经走过,即判重。
走多远,即是最少步数。如果用DFS来说,即是深度,用BFS来说,便是向外扩展了多少米(其实也是深度)。
那怎么记录路径呢?办法是每个节点加个指向前一个节点的指针,每一步记录前一步,便能记录整条路径。DFS不用说,就是解答树的一个分支,而BFS则是会形成一颗BFS树
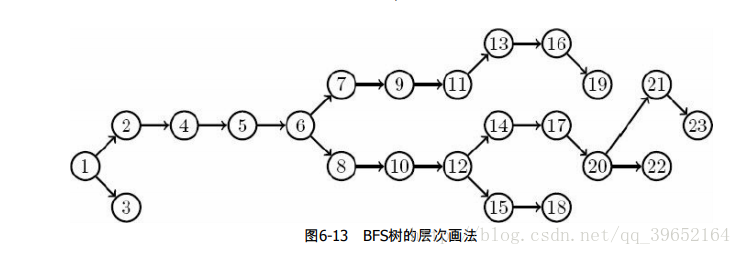
但是这样得出来的路径是从终点到起点的路径,这里便需要从终点开始用递归打印出来,便能打印起点到终点的路径。
DFS以解答树遍历,不会重复,无需判重,但如果是用DFS进行回溯法枚举,则可能需要判重
BFS判重的方法可以用bool数组,然后true表示走过节点,false表示没走过的节点,如果是比较复杂的状态等,则可能需要hash了(当《算法导论》中DFS跟BFS用的都是OPEN跟CLOSE表)
启发式搜索
启发式搜索的好坏基本都取决于评估函数。
IDA*算法
要说IDA*算法,就先说迭代加深搜索吧。本来不打算说的,先说一个DFS的一个问题,如果现在的路的深度没有上限,即没有底,那么直接DFS就回不来了。。。所以就有了迭代加深搜索,即每次给DFS加个记录深度的(或者说解答树的层数)参数d,每次走到相应的深度就返回。由于深度d是慢慢递增的,这样的得出了的答案毫无疑问是最小深度(即少步数),但是缺点很明显,重复遍历解答树上层多次,造成巨大浪费。而IDA*则多了评估函数(或者说剪枝),每次预估如果这条路如果继续下去也无法到达终点,则放弃这条路(剪枝的一种,即最优性剪枝)。IDA*原理实现起来简单,非常方便,但难的地方是评估函数的编写,足够好的评估函数可以避免走更多的不归路,如果评估函数太差或者没有评估函数,那会退化到迭代加深搜索那种浪费程度。如果想要学IDA*算法,我推荐算法竞赛入门经典中的暴力枚举法—迭代加深搜索一章。
A*算法
A*算法我想很多人都听说过,这是AI算法应用最广泛的算法之一,经常用到游戏里寻找最短路的算法里。如果说IDA*算法是改进DFS算法来的,A*算法便是BFS算法的升级版。A*算法跟BFS一样,扩展周围的几个点,但是A*会评估这几个点哪个到终点比较近,然后选择近的走,然后继续评估,又选择近的走,直到走到终点。
如何每次保证选择到的是最近的呢,这里就需要用到堆了。建立一个最小堆,每次取最上面的一个。而比较大小的标准是通过评估值F的大小,以最短路径来说,每次会选F值最小的。对于节点n有这样的定义,f(n) = g(n) + h(n), 其中g(n)是到节点n已经花费的代价,h是到g(n)的估计代价,也可以认为是最少代价。在最短路径中h函数可以用欧几里得距离,或者曼哈顿距离来判断,欧几里得距离通俗点说即两点间长度。曼哈顿距离就是x轴距离+y轴距离。至于g(n),可以设置走一步代价为1(当然你想设置成8,9,10之类的随便,只是一个度量),g值跟Dijkstra的松弛一样,需要更新,每次找到一个节点可以让它更新为更小的,就更新g值跟f值(h值不用更新,因为对于每个点的h值都是确定的)。
A*算法跟BFS一样,需要用father来记录上一个节点,从而实现遍历最短路径。至于判重操作,A*的判重是通过两个表(或许该说是两个堆)判重的,一般叫做open表跟close表(当然BFS也可以通过open跟close队列实现判重),close表存放已经走过的点,open表中是还没走的节点,每次从open取出f值最小的作为当前节,然后扩展当前节点周围的点push进open表,然后pop并把当前点放到close表中,然后继续重复以上操作,每次从open取出f值最小的作为当前节.......如果此条最近的路不通,如遇到墙之类的,A*便选择第二短的路(当然第一第二可能一样短),(这里最近的路是如操场无障碍那种,那我们走直线距离肯定最近,但是如果我们走近发现前面有一堵墙,此路不通,我们就得退回去试试其他路,A*会马上跳转到刚才第二近的路进行下一步扩展),如果还不通,就选择第三短的路。。。直到open表中出现了目标节点,则表示已经找到最短路,退出循环,如果open表为空,则表示不存在到达目标的路径。总结起来A*算法就是BFS的扩展方式+预估函数的+Dijkstra的松弛方式+堆的使用+open跟close表的判重+father记录路径。
关于A*算法,这是我看过的一个写的不错的文章http://blog.csdn.net/u012234115/article/details/47152137,可以当做参考。
总结,DFS在搜索中使用栈返回,IDA*是DFS的延伸还是用到栈,BFS使用队列扩展,A*使用堆来取出评估最好的值,理解这三个数据结构,才能较好理解这三种算法,无非就是,如果这点符合条件的就扩展,然后用不同的数据结构扩展,前两者不管数据如何,看到就放入,后者用堆,实现大小排序,可以选择更好的路径。 几种搜索不同的条件下返回,DFS是走到底,A*跟BFS是队列为空,IDA*是到达目标深度或者剪枝
几种搜索算法就说到这,暂时想到这么多,由于本人知识有限,如果有什么错误,望各位大佬纠正