Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
paper:https://arxiv.org/abs/2004.10955
本文是
Boston & PixelShift.AI & Google Research写的一篇关于实时风格迁移的爽文。作者包含大名鼎鼎的Jiawen Chen。看标题也很明显就知道,它是HDRNet的传承者,是HDRNet类方法在风格迁移领域的成功应用(手机端4K实时风格迁移)。
Abstract
风格迁移指的是将图像A的艺术风格迁移到图像B的内容中,从而媲美相加拍摄的效果。近年来基于深度学习的方法取得了令人惊讶的效果,但存在速度过慢问题或伪影问题,这就导致了相应技术难以实际产品化落地。作者提出一种的快速的端到端的风格迁移架构,它不但速度够快,而且生成结果更为逼真。该方法的核心:一个可以学习局部边缘敏感仿射变换(edge-aware affine transforms)的前向神经网络。该方法一经训练完成,它可以在任意对图像上实施鲁棒风格迁移。相比其他SOTA方法,所提方法可以生成更好的视觉效果,同时更快,在手机端可达实时@4K。
Our model is a feed-forward deep neural network that once trained on a suitable dataset, runs in real time on a mobile phone at full camera resolution (i.e. 12 megapixels or “4K”) significantly faster than the state of the art. ---- from the paper.
作者设计了一种“双边空间(bilateral space)”深度学习算法,它通过一个紧致网络在低分辨率学习局部放射变换,然后在原始分辨率进行风格映射。是不是很有HDRNet的风格!。该文贡献包含以下三点:
-
提出一个实时而逼真风格迁移网络;
-
所提网络可以在手机端达到实时@4K(注:这是最赞的);
-
提出一种双边空间拉普拉斯正则消除空间网络伪影
Method
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nU8Wupd7-1587872567519)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/20200426114623513.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
上图给出了所提方法与其他SOTA方法在生成结果的视觉效果对比,毋庸置疑,所提方法取得了完胜。所提方法基于单个前向神经网络而设计,它以两个图像作为输入,内容图像与风格图像,输出具有前者内容后者风格的逼真结果。
所提方法具有极好的通用性:一经训练完毕,它可以轻易扩展到其他输入组合。所提方法的关键核心在于:学习局部放射变换,它“天生”可以迫使“逼真约束”(photorealistic constraint)。
Background
Content and Style: 早期的神经风格迁移基于优化输入图像的内容与风格,相应损失定义如下:
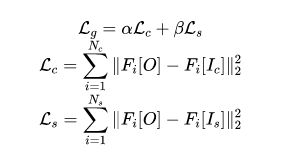
注:分别表示从预训练VGG19中选择的中间层数,在风格迁移中往往采用VGG19提取风格与内容信息。内容相似性可以通过特征层面的MSE损失评价,风格相似性可以通过特征封面的Gram matrices 评价。
AdaIN: 除了直接上述计算内容与风格损失的方法,还有另一种比较好的方法:特征统计匹配。其中有代表性的当属AdaIN,其公式描述如下:
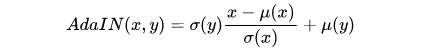
其中x与y分别表示内容与风格特征通道。在该文中,作者选用了AdaIN及其对应的风格损失:
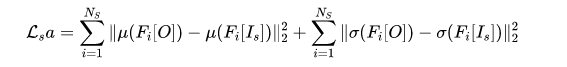
Bilateral Space: 双边空间最早被用于对边缘敏感图像降噪进行加速,后被拓展进行图像间的变换(BGU),再后来因其可微性被拓展到深度学习领域得到了知名的HDRNet被用于tone mapping与细节增强。
Network Architecture
作者所设计的网络结构包含两个分支:(1)系数预测分支:它以低分辨率的内容与风格作为输入,学习他们在低维(low-level)特征层面的联合分布并预测放射双边网络;(2)渲染分支:与HDRNet类似,无改进,直接在全分辨率图像上进行操作。对于每个像素,它采用学习到的查找表计算luma值, 切片输出,通常采用三次线性插值得到最终的输出。网络结构信息见下图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k2FeOBSr-1587872567520)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/20200426114905692.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
Style-based Splatting: 首先需要采用多尺度模型学习内容与风格特征的联合分布,基于该联合分布预测仿射双边网络。作者采用预训练VGG19提取四个尺度(conv1_1, conv2_1, conv3_1, conv4_1)特征,受StyleGAN架构启发,作者采用splatting blocks处理这些多尺度特征。从最精细(finest)的特征开始,对内容与风格特征执行权值共享stride=2的卷积同时通道数倍增,该权值共享卷积可以使得后续的AdaIN层学习内容与风格的联合分布而无需相应的监督。与此同时,将所得内容特征加入到AdaIN对齐的特征中,然后再采用stride=1的卷积进行降维选择有意义(relevant)的特征。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SaiDOkOB-1587872567521)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/20200426114922973.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
Joint Bilateral Learning: 基于双边空间中的对齐内容-风格特征,作者寻求学习仿射双边网络(它编码了语义级的局部变换)。类似于HDRNet,作者将整个网络划分为非对称的两个分支:(1)用于学习局部颜色变换的全卷积局部分支;(2)包含卷积与全连接层的全局分支,它有助于进行变换的空域正则。
由于所提方法的目标在于:执行通用的风格迁移而且无需任何明确的语义表示,作者采用了一个小网络学习场景类别的全局表示。该全局分支包含两个stride=2的卷积,后接四个全连接层输出一个64维的向量summary。与此同时,将该全局表示添加到每个位置的局部表示后并通过降维到96。该96维信息可以reshape到8个luma bins,每个bin包含的放射变换。
Losses
由于所设计的网络结构是可微的,故而可以在最终的输出上直接定义损失函数。在内容损失、风格损失之外,作者还添加了一种新颖的双边空间拉普拉斯正则:
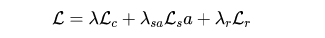
其中 的定义见前文公式,其他参数取值为,的定义如下:
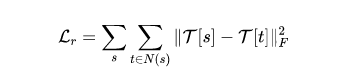
其中,表示所估计的双边网格,表示其近邻。拉普拉斯正则用于惩罚相邻网格cells之间的不相似性,以迫使所学习的局部放射变换的局部平滑性。作者通过实验验证了所提拉普拉斯正则的必要性。
Training
作者从500px.com网站上手机了一个包含10W高质量专业图像的数据集,采用Tensorflow进行训练。优化器选用Adam,BatchSize为12(内容与风格分别12张)。在每个epoch,作者随机将上述数据划分为5W内容-5W风格。训练图像的分辨率为,共计训练25epoch,在单个TeslaV100GPU上花费两天时间。训练完成后,推理阶段可以在任意分辨率执行。
Experiments
在验证阶段,作者从splash.com网络收集一个包含400高质量图像的测试集。
首先,直接上定性评价结果。作者将所提方法与PhotoWCT, LST, WCT等方法进行了对比,对比结果见下图。由于unpooling与后处理的依赖型,PhotoWCT几乎在所有场景上都存在不可忽视的伪影问题;而LST主要是进行风格迁移,内容生成方面采用了耗时的空域传播网络作为后处理步骤降低畸变伪影,尽管如此及,其所生成结果仍存在不可忽视的额伪影;在内容与风格图像具有相似语义时,WCT表现非常好,但是当两者存在较大差异时,其性能急剧变差。而所提方法在上述具有挑战的图像上均表现优异。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Siyx0z5-1587872567524)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/20200426115036751.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
然后,补上定量评价结果,见下图。从中可以看出:无论是在推理速度、还是生成质量方面,所提方法均处于全面优势地位。Note:表中结果的测试的硬件平台为:Tesla-V100 GPU。而在手机GPU平台下,当模型量化到FP16后,其推理速度可达到30Hz@3000x4000(12megapixel)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g3EKhdaV-1587872567525)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/20200426115054287.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
其次,补上在视频中的应用。既然所提方法具有这么快的速度,那么在视频中的应用如何?是否会存在时序抖动呢?作者发现:尽管所提方法采用图像进行训练,但其可以很好的泛化到视频内容。相关结果见下图,从中可以看出:所生成的视频具有一致的风格特性、时序相关性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5dKALzlh-1587872567526)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]](https://img-blog.csdnimg.cn/2020042611535187.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0V4dHJlbWV2aXNpb24=,size_16,color_FFFFFF,t_70)
最后,补上消融实验结果。消融实验部分建议各位小伙伴仔细研读原文,故而这里忽略翻译部分。




Conclusion
作者提出了一种通用而逼真的风格迁移前馈网络。所提方法的关键核心在于:采用深度学习方法预测仿射双边网络。所提方法不仅具有较好生成质量,还具有极快的推理速度(手机端实时@4K,非常的令人惊讶)。很明显,该方法将引领一段视频风格迁移的产品化落地。
在 **极市平台 **后台回复 **PST **即可获得论文下载链接。
-END**-**
推荐阅读:

