睿智的目标检测25—Keras搭建M2Det目标检测平台
学习前言
一起来看看M2det的keras实现吧,顺便训练一下自己的数据。

什么是M2det目标检测算法
常见的特征提取方法如图所示有SSD形,FPN形,STDN形:
SSD型:使用了主干网络的最后两层,再加上4个使用stride=2卷积的下采样层构成;
FPN型:也称为U型网络,经过上采样操作,然后对应融合相同的scale;
STDN型:基于DenseNet的最后一个dense block,通过池化和scale-transfer操作来构建;
这三者有一定的缺点:
一是均基于分类网络作为主干提取,对目标检测任务而言特征表示可能不够;二是每个feature map仅由主干网络的single level给出,不够全面
M2det论文新提出MLFPN型,整体思想是Multi-level&Multi-scale。是一种更加有效的适合于检测的特征金字塔结构。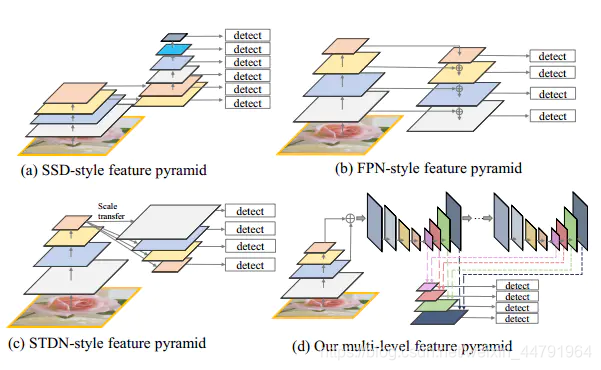
源码下载
https://github.com/bubbliiiing/M2det-Keras
喜欢的可以点个star噢。
M2det实现思路
一、预测部分
1、主干网络介绍
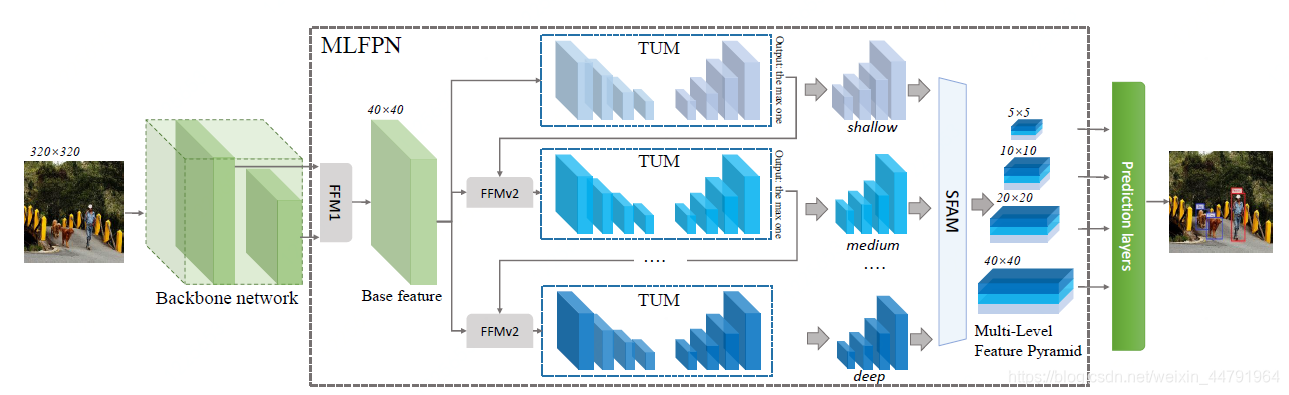
M2det采用可以采用VGG和ResNet101作为主干特征提取网络,上图的backbone network指的就是VGG和Resnet101,本文以VGG为例介绍。
M2DET采用的主干网络是VGG网络,关于VGG的介绍大家可以看我的另外一篇博客https://blog.csdn.net/weixin_44791964/article/details/102779878。
在m2det中,我们去掉了全部的全连接层,只保留了卷积层和最大池化层,即Conv1到Conv5。
1、一张原始图片被resize到(320,320,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(320,320,64),再2X2最大池化,输出net为(160,160,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(160,160,128),再2X2最大池化,输出net为(80,80,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(80,80,256),再2X2最大池化,输出net为(40,40,256)。
5、conv4三次[3,3]卷积网络,输出的特征层为512,输出net为(40,40,512),再2X2最大池化,此时不进行池化,输出net为(40,40,512)。conv4-3的结果会进入FFM1进行特征的融合。
6、conv5三次[3,3]卷积网络,输出的特征层为1024,输出net为(40,40,1024),再2X2最大池化,输出net为(20,20,1024)。池化后的结果会进入FFM1进行特征的融合。
def VGG16(inputs):
net = {}
image_input = inputs
net['input'] = image_input
# 第一个卷积部分
net['conv1_1'] = Conv2D(64, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv1_1')(net['input'])
net['conv1_2'] = Conv2D(64, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv1_2')(net['conv1_1'])
net['pool1'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same',
name='pool1')(net['conv1_2'])
# 第二个卷积部分
net['conv2_1'] = Conv2D(128, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv2_1')(net['pool1'])
net['conv2_2'] = Conv2D(128, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv2_2')(net['conv2_1'])
net['pool2'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same',
name='pool2')(net['conv2_2'])
y0 = net['pool2']
# 第三个卷积部分
net['conv3_1'] = Conv2D(256, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv3_1')(net['pool2'])
net['conv3_2'] = Conv2D(256, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv3_2')(net['conv3_1'])
net['conv3_3'] = Conv2D(256, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv3_3')(net['conv3_2'])
net['pool3'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same',
name='pool3')(net['conv3_3'])
y1 = net['pool3']
# 第四个卷积部分
net['conv4_1'] = Conv2D(512, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv4_1')(net['pool3'])
net['conv4_2'] = Conv2D(512, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv4_2')(net['conv4_1'])
net['conv4_3'] = Conv2D(512, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv4_3')(net['conv4_2'])
# net['pool4'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same',
# name='pool4')(net['conv4_3'])
y2 = net['conv4_3']
# 第五个卷积部分
net['conv5_1'] = Conv2D(1024, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv5_1')(net['conv4_3'])
net['conv5_2'] = Conv2D(1024, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv5_2')(net['conv5_1'])
net['conv5_3'] = Conv2D(1024, kernel_size=(3,3),
activation='relu',
padding='same',
name='conv5_3')(net['conv5_2'])
net['pool5'] = MaxPooling2D((3, 3), strides=(2, 2), padding='same',
name='pool5')(net['conv5_3'])
y3 = net['pool5']
model = Model(inputs, [y0,y1,y2,y3], name='resnet50')
return model
2、FFM1特征初步融合
FFM1具体的结构如下:

FFM1会对VGG提取到的特征进行初步融合。
在利用VGG进行特征提取的时候,我们会取出shape为(40,40,512)、(20,20,1024)的特征层进行下一步的操作。
在FFM1中,其会对(20,20,1024)的特征层进行进行一个通道数为512、卷积核大小为3x3、步长为1x1的卷积,然后再进行上采样,使其Shape变为(40,40,512);
同时会对(40,40,512)的特征层进行进行一个通道数为256、卷积核大小为1x1,步长为1x1的卷积,使其Shape变为(40,40,256);
然后将两个卷积后的结果进行堆叠,变成一个(40,40,768)的初步融合特征层
实现代码为:
def FFMv1(C4, C5, feature_size_1=256, feature_size_2=512,
name='FFMv1'):
# 40,40,256
F4 = conv2d(C4, filters=feature_size_1, kernel_size=(3, 3), strides=(1, 1), padding='same', name='F4')
# 20,20,512
F5 = conv2d(C5, filters=feature_size_2, kernel_size=(1, 1), strides=(1, 1), padding='same', name='F5')
# 40,40,512
F5 = keras.layers.UpSampling2D(size=(2, 2), name='F5_Up')(F5)
outputs = keras.layers.Concatenate(name=name)([F4, F5])
# 40,40,768
return outputs
3、细化U型模块TUM
Tum的结构具体如下:
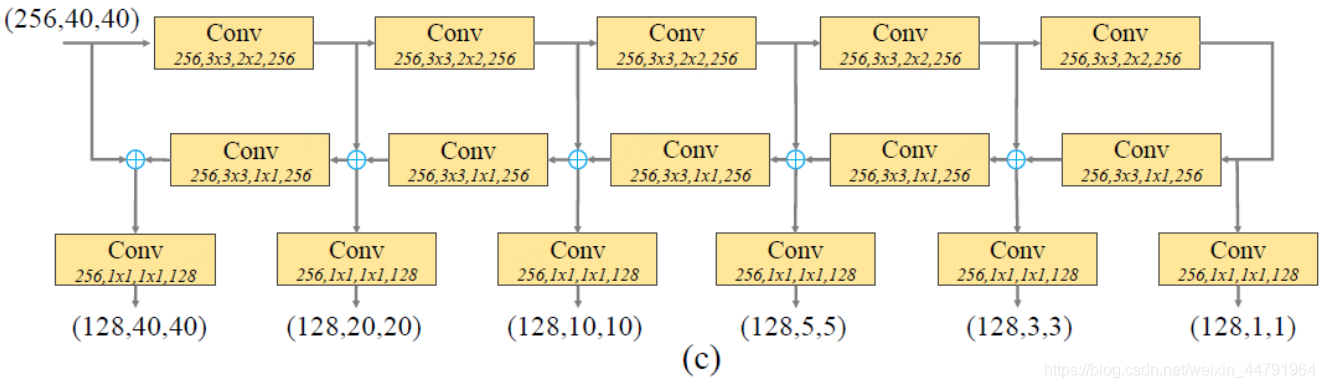
当我们给Tum输入一个(40,40,256)的有效特征层之后,Tum会对输入进来的特征层进行U型的特征提取,这里的结构比较类似特征金字塔的结构,先对特征层进行不断的特征压缩,然后再不断的上采样进行特征融合,利用Tum我们可以获得6个有效特征层,大小分别是(40,40,128)、(20,20,128)、(10,10,128)、(5,5,128)、(3,3,128)、(1,1,128)。
def TUM(stage, inputs, feature_size=256, name="TUM"):
# 128
output_features = feature_size // 2
size_buffer = []
# 40,40,256
f1 = inputs
# 20,20,256
f2 = conv2d(f1, filters=feature_size, kernel_size=(3, 3), strides=(2, 2), padding='same',name=name + "_" + str(stage) + '_f2')
# 10,10,256
f3 = conv2d(f2, filters=feature_size, kernel_size=(3, 3), strides=(2, 2), padding='same',name=name + "_" + str(stage) + '_f3')
# 5,5,256
f4 = conv2d(f3, filters=feature_size, kernel_size=(3, 3), strides=(2, 2), padding='same',name=name + "_" + str(stage) + '_f4')
# 3,3,256
f5 = conv2d(f4, filters=feature_size, kernel_size=(3, 3), strides=(2, 2), padding='same',name=name + "_" + str(stage) + '_f5')
# 1,1,256
f6 = conv2d(f5, filters=feature_size, kernel_size=(3, 3), strides=(2, 2), padding='valid',name=name + "_" + str(stage) + '_f6')
# 40,40
size_buffer.append([int(f1.shape[2])] * 2)
# 20,20
size_buffer.append([int(f2.shape[2])] * 2)
# 10,10
size_buffer.append([int(f3.shape[2])] * 2)
# 5,5
size_buffer.append([int(f4.shape[2])] * 2)
# 3,3
size_buffer.append([int(f5.shape[2])] * 2)
# print(size_buffer)
level = 2
c6 = f6
# 1,1,256
c5 = conv2d(c6, filters=feature_size, kernel_size=(3, 3), strides=(1, 1), padding='same',name=name + "_" + str(stage) + '_c5')
# 3,3,256
c5 = keras.layers.Lambda(lambda x: tf.image.resize_bilinear(x, size=size_buffer[4]), name=name + "_" + str(stage) + '_upsample_add5')(c5)
c5 = keras.layers.Add()([c5, f5])
# 3,3,256
c4 = conv2d(c5, filters=feature_size, kernel_size=(3, 3), strides=(1, 1), padding='same', name=name + "_" + str(stage) + '_c4')
# 5,5,256
c4 = keras.layers.Lambda(lambda x: tf.image.resize_bilinear(x, size=size_buffer[3]), name=name + "_" + str(stage) + '_upsample_add4')(c4)
c4 = keras.layers.Add()([c4, f4])
# 5,5,256
c3 = conv2d(c4, filters=feature_size, kernel_size=(3, 3), strides=(1, 1), padding='same', name=name + "_" + str(stage) + '_c3')
# 10,10,256
c3 = keras.layers.Lambda(lambda x: tf.image.resize_bilinear(x, size=size_buffer[2]), name=name + "_" + str(stage) + '_upsample_add3')(c3)
c3 = keras.layers.Add()([c3, f3])
# 10,10,256
c2 = conv2d(c3, filters=feature_size, kernel_size=(3, 3), strides=(1, 1), padding='same', name=name + "_" + str(stage) + '_c2')
# 20,20,256
c2 = keras.layers.Lambda(lambda x: tf.image.resize_bilinear(x, size=size_buffer[1]), name=name + "_" + str(stage) + '_upsample_add2')(c2)
c2 = keras.layers.Add()([c2, f2])
# 20,20,256
c1 = conv2d(c2, filters=feature_size, kernel_size=(3, 3), strides=(1, 1), padding='same', name=name + "_" + str(stage) + '_c1')
# 40,40,256
c1 = keras.layers.Lambda(lambda x: tf.image.resize_bilinear(x, size=size_buffer[0]), name=name + "_" + str(stage) + '_upsample_add1')(c1)
c1 = keras.layers.Add()([c1, f1])
level = 3
# 40,40,128
o1 = conv2d(c1, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o1')
# 20,20,128
o2 = conv2d(c2, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o2')
# 10,10,128
o3 = conv2d(c3, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o3')
# 5,5,128
o4 = conv2d(c4, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o4')
# 3,3,128
o5 = conv2d(c5, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o5')
# 1,1,128
o6 = conv2d(c6, filters=output_features, kernel_size=(1, 1), strides=(1, 1), padding='valid',name=name + "_" + str(stage) + '_o6')
outputs = [o1, o2, o3, o4, o5, o6]
return outputs
4、FFM2特征加强融合
通过TUM,我们可以获得六个有效特征层,为了进一步加强网络的特征提取能力,M2det将6个有效特征层中的(40,40,128)特征层取出,和FFM1提取出来的初步融合特征层进行加强融合,再次输出一个(40,40,256)的加强融合的特征层。

此时FFM2输出的加强融合特征层可以再一次传入到TUM中进行U形特征提取。
如上图所示,我们可以进一步利用多个TUM模块进行特征提取,利用多个TUM模块我们可以获得多次有效特征层。
TUM模块的数量我们可以根据自身需要进行修改,本文使用4次TUM模块,可以分别获得四次(40,40,128)、(20,20,128)、(10,10,128)、(5,5,128)、(3,3,128)、(1,1,128)的有效特征层。(论文中做了实验,用8次TUM模块会有比较好的效果)。
我们可以将获得的有效特征层,按照shape进行堆叠,最终获得(40,40,512)、(20,20,512)、(10,10,512)、(5,5,512)、(3,3,512)、(1,1,512)六个有效特征层。
def FFMv2(stage, base, tum, base_size=(40,40,768), tum_size=(40,40,128), feature_size=128, name='FFMv2'):
# 40,40,128
outputs = conv2d(base, filters=feature_size, kernel_size=(1, 1), strides=(1, 1), padding='same', name=name+"_"+str(stage) + '_base_feature')
outputs = keras.layers.Concatenate(name=name+"_"+str(stage))([outputs, tum])
# 40,40,256
return outputs
def _create_feature_pyramid(base_feature, stage=8):
features = [[],[],[],[],[],[]]
# 将输入进来的
inputs = keras.layers.Conv2D(filters=256, kernel_size=1, strides=1, padding='same')(base_feature)
# 第一个TUM模块
outputs = TUM(1,inputs)
max_output = outputs[0]
for j in range(len(features)):
features[j].append(outputs[j])
# 第2,3,4个TUM模块,需要将上一个Tum模块输出的40x40x128的内容,传入到下一个Tum模块中
for i in range(2, stage+1):
# 将Tum模块的输出和基础特征层传入到FFmv2层当中
# 输入为base_feature 40x40x768,max_output 40x40x128
# 输出为40x40x256
inputs = FFMv2(i - 1,base_feature, max_output)
# 输出为40x40x128、20x20x128、10x10x128、5x5x128、3x3x128、1x1x128
outputs = TUM(i,inputs)
max_output = outputs[0]
for j in range(len(features)):
features[j].append(outputs[j])
# 进行了4次TUM
# 将获得的同样大小的特征层堆叠到一起
concatenate_features = []
for feature in features:
concat = keras.layers.Concatenate()([f for f in feature])
concatenate_features.append(concat)
return concatenate_features
5、注意力机制模块SFAM
注意力机制模块如下:
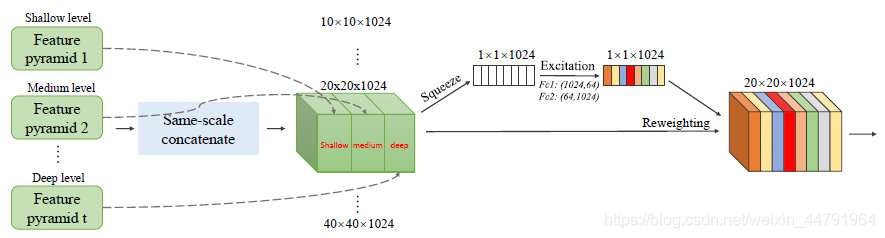
其会对上一步获得的(40,40,512)、(20,20,512)、(10,10,512)、(5,5,512)、(3,3,512)、(1,1,512)六个有效特征层。进行各个通道的注意力机制调整,判断每一个通道数应该有的权重。
# 注意力机制
def SE_block(inputs, input_size, compress_ratio=16, name='SE_block'):
pool = keras.layers.GlobalAveragePooling2D()(inputs)
reshape = keras.layers.Reshape((1, 1, input_size[2]))(pool)
fc1 = keras.layers.Conv2D(filters=input_size[2] // compress_ratio, kernel_size=1, strides=1, padding='valid',
activation='relu', name=name+'_fc1')(reshape)
fc2 = keras.layers.Conv2D(filters=input_size[2], kernel_size=1, strides=1, padding='valid', activation='sigmoid',
name=name+'_fc2')(fc1)
reweight = keras.layers.Multiply(name=name+'_reweight')([inputs, fc2])
return reweight
def SFAM(feature_pyramid,input_sizes, compress_ratio=16, name='SFAM'):
outputs = []
for i in range(len(input_sizes)):
input_size = input_sizes[i]
_input = feature_pyramid[i]
_output = SE_block(_input, input_size, compress_ratio=compress_ratio, name='SE_block_' + str(i))
outputs.append(_output)
return outputs
6、从特征获取预测结果
通过第五步,我们获取了6个融合了注意力机制的有效特征层。
对获取到的每一个有效特征层,我们分别对其进行一次num_priors x 4的卷积、一次num_priors x num_classes的卷积、并需要计算每一个有效特征层对应的先验框。而num_priors指的是该特征层所拥有的先验框数量。
其中:
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为M2DET的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的六个框。
所有的特征层对应的预测结果的shape如下:

实现代码为:
def m2det(num_classes,inputs, num_anchors=6, name='m2det',backbone='mobilenet'):
if inputs==None:
inputs = keras.layers.Input(shape=(320, 320, 3))
else:
inputs = inputs
if backbone=='mobilenet':
C3, C4, C5 = MobileNet(inputs).outputs[1:]
elif backbone=='resnet':
C3, C4, C5 = ResNet50(inputs).outputs[1:]
elif backbone=="vgg":
C3, C4, C5 = VGG16(inputs).outputs[1:]
# 40,40,768
base_feature = FFMv1(C4, C5, feature_size_1=256, feature_size_2=512)
if backbone=='mobilenet':
feature_pyramid = _create_feature_pyramid(base_feature, stage=4)
elif backbone=='resnet':
feature_pyramid = _create_feature_pyramid(base_feature, stage=4)
elif backbone=="vgg":
feature_pyramid = _create_feature_pyramid(base_feature, stage=4)
feature_pyramid_sizes = _calculate_input_sizes(feature_pyramid)
outputs = SFAM(feature_pyramid,feature_pyramid_sizes)
regressions = []
classifications = []
for feature in outputs:
classification = keras.layers.Conv2D(filters=num_classes * num_anchors,kernel_size=3,strides=1,padding='same')(feature)
classification = keras.layers.Reshape((-1, num_classes))(classification)
classification = keras.layers.Activation('softmax')(classification)
regression = keras.layers.Conv2D(filters=num_anchors * 4,kernel_size=3,strides=1,padding='same')(feature)
regression = keras.layers.Reshape((-1, 4))(regression)
regressions.append(regression)
classifications.append(classification)
regressions = keras.layers.Concatenate(axis=1, name="regression")(regressions)
classifications = keras.layers.Concatenate(axis=1, name="classification")(classifications)
pyramids = [regressions,classifications]
return keras.models.Model(inputs=inputs, outputs=pyramids, name=name)
7、预测结果的解码
我们通过对每一个特征层的处理,可以获得两个内容,分别是:
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的六个框。
我们利用 num_priors x 4的卷积 与 每一个有效特征层对应的先验框 获得框的真实位置。
每一个有效特征层对应的先验框就是,如图所示的作用:
每一个有效特征层将整个图片分成与其长宽对应的网格,如conv4-3和fl7组合成的特征层就是将整个图像分成38x38个网格;然后从每个网格中心建立多个先验框,如conv4-3和fl7组合成的有效特征层就是建立了6个先验框;对于conv4-3和fl7组合成的特征层来讲,整个图片被分成38x38个网格,每个网格中心对应6个先验框,一共包含了,38x38x6个,8664个先验框。
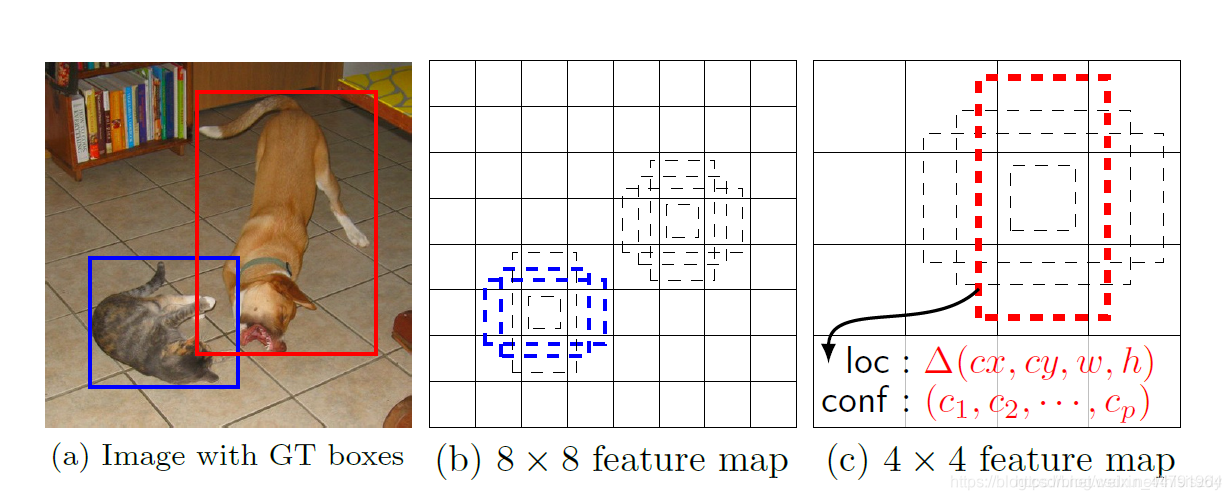
先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,RFBnet利用num_priors x 4的卷积的结果对先验框进行调整。
num_priors x 4中的num_priors表示了这个网格点所包含的先验框数量,其中的4表示了x_offset、y_offset、h和w的调整情况。
x_offset与y_offset代表了真实框距离先验框中心的xy轴偏移情况。
h和w代表了真实框的宽与高相对于先验框的变化情况。
RFBnet解码过程就是将每个网格的中心点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选这一部分基本上是所有目标检测通用的部分。
1、取出每一类得分大于self.obj_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
实现代码如下:
def decode_boxes(self, mbox_loc, mbox_priorbox):
# 获得先验框的宽与高
prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
# 获得先验框的中心点
prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
# 真实框距离先验框中心的xy轴偏移情况
decode_bbox_center_x = mbox_loc[:, 0] * prior_width * 0.1
decode_bbox_center_x += prior_center_x
decode_bbox_center_y = mbox_loc[:, 1] * prior_height * 0.1
decode_bbox_center_y += prior_center_y
# 真实框的宽与高的求取
decode_bbox_width = np.exp(mbox_loc[:, 2] * 0.2)
decode_bbox_width *= prior_width
decode_bbox_height = np.exp(mbox_loc[:, 3] * 0.2)
decode_bbox_height *= prior_height
# 获取真实框的左上角与右下角
decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
# 真实框的左上角与右下角进行堆叠
decode_bbox = np.concatenate((decode_bbox_xmin[:, None],
decode_bbox_ymin[:, None],
decode_bbox_xmax[:, None],
decode_bbox_ymax[:, None]), axis=-1)
# 防止超出0与1
decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)
return decode_bbox
def detection_out(self, predictions, mbox_priorbox, background_label_id=0, keep_top_k=200,
confidence_threshold=0.4):
# 网络预测的结果
mbox_loc = predictions[0]
# 先验框
mbox_priorbox = mbox_priorbox
# 置信度
mbox_conf = predictions[1]
results = []
# 对每一个图片进行处理
for i in range(len(mbox_loc)):
results.append([])
decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox)
for c in range(self.num_classes):
if c == background_label_id:
continue
c_confs = mbox_conf[i, :, c]
c_confs_m = c_confs > confidence_threshold
if len(c_confs[c_confs_m]) > 0:
# 取出得分高于confidence_threshold的框
boxes_to_process = decode_bbox[c_confs_m]
confs_to_process = c_confs[c_confs_m]
# 进行iou的非极大抑制
feed_dict = {self.boxes: boxes_to_process,
self.scores: confs_to_process}
idx = self.sess.run(self.nms, feed_dict=feed_dict)
# 取出在非极大抑制中效果较好的内容
good_boxes = boxes_to_process[idx]
confs = confs_to_process[idx][:, None]
# 将label、置信度、框的位置进行堆叠。
labels = c * np.ones((len(idx), 1))
c_pred = np.concatenate((labels, confs, good_boxes),
axis=1)
# 添加进result里
results[-1].extend(c_pred)
if len(results[-1]) > 0:
# 按照置信度进行排序
results[-1] = np.array(results[-1])
argsort = np.argsort(results[-1][:, 1])[::-1]
results[-1] = results[-1][argsort]
# 选出置信度最大的keep_top_k个
results[-1] = results[-1][:keep_top_k]
# 获得,在所有预测结果里面,置信度比较高的框
# 还有,利用先验框和m2det的预测结果,处理获得了真实框(预测框)的位置
return results
8、在原图上进行绘制
通过第三步,我们可以获得预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
二、训练部分
1、真实框的处理
从预测部分我们知道,每个特征层的预测结果,num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
也就是说,我们直接利用M2DET网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于M2DET网络的预测结果的。我们需要把图片输入到当前的M2DET网络中,得到预测结果;同时还需要把真实框的信息,进行编码,这个编码是把真实框的位置信息格式转化为M2DET预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的预测结果应该是怎么样的。
从预测结果获得真实框的过程被称作解码,而从真实框获得预测结果的过程就是编码的过程。
因此我们只需要将解码过程逆过来就是编码过程了。
实现代码如下:
def iou(self, box):
# 计算出每个真实框与所有的先验框的iou
# 判断真实框与先验框的重合情况
inter_upleft = np.maximum(self.priors[:, :2], box[:2])
inter_botright = np.minimum(self.priors[:, 2:4], box[2:])
inter_wh = inter_botright - inter_upleft
inter_wh = np.maximum(inter_wh, 0)
inter = inter_wh[:, 0] * inter_wh[:, 1]
# 真实框的面积
area_true = (box[2] - box[0]) * (box[3] - box[1])
# 先验框的面积
area_gt = (self.priors[:, 2] - self.priors[:, 0])*(self.priors[:, 3] - self.priors[:, 1])
# 计算iou
union = area_true + area_gt - inter
iou = inter / union
return iou
def encode_box(self, box, return_iou=True):
iou = self.iou(box)
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
# 找到对应的先验框
assigned_priors = self.priors[assign_mask]
# 先计算真实框的中心与长宽
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
# 再计算重合度较高的先验框的中心与长宽
assigned_priors_center = 0.5 * (assigned_priors[:, :2] +
assigned_priors[:, 2:4])
assigned_priors_wh = (assigned_priors[:, 2:4] -
assigned_priors[:, :2])
# 逆向求取RFB应该有的预测结果
encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center
encoded_box[:, :2][assign_mask] /= assigned_priors_wh
# 除以0.1
encoded_box[:, :2][assign_mask] /= 0.1
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh)
# 除以0.2
encoded_box[:, 2:4][assign_mask] /= 0.2
return encoded_box.ravel()
利用上述代码我们可以获得,真实框对应的所有的iou较大先验框,并计算了真实框对应的所有iou较大的先验框应该有的预测结果。
在训练的时候我们只需要选择iou最大的先验框就行了,这个iou最大的先验框就是我们用来预测这个真实框所用的先验框。
因此我们还要经过一次筛选,将上述代码获得的真实框对应的所有的iou较大先验框的预测结果中,iou最大的那个筛选出来。
通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的。
实现代码如下:
def assign_boxes(self, boxes):
assignment = np.zeros((self.num_priors, 4 + 1 + 1 + self.num_classes + 1))
assignment[:, 4] = 0.0
assignment[:, 5] = 1
assignment[:, -1] = 0.0
if len(boxes) == 0:
return assignment
# (n, num_priors, 5)
encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4])
# 每一个真实框的编码后的值,和iou
# (n, num_priors)
encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5)
# 取重合程度最大的先验框,并且获取这个先验框的index
# (num_priors)
best_iou = encoded_boxes[:, :, -1].max(axis=0)
# (num_priors)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
# (num_priors)
best_iou_mask = best_iou > 0
# 某个先验框它属于哪个真实框
best_iou_idx = best_iou_idx[best_iou_mask]
assign_num = len(best_iou_idx)
# 保留重合程度最大的先验框的应该有的预测结果
# 哪些先验框存在真实框
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]
# 4代表为背景的概率,为0
assignment[:, 4][best_iou_mask] = 1
assignment[:, 5][best_iou_mask] = 0
assignment[:, 6:-1][best_iou_mask] = boxes[best_iou_idx, 4:]
assignment[:, -1][best_iou_mask] = 1
# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的
return assignment
2、利用处理完的真实框与对应图片的预测结果计算loss
loss的计算分为三个部分:
1、获取所有正标签的框的预测结果的回归loss。
2、获取所有正标签的种类的预测结果的交叉熵loss。
3、获取一定负标签的种类的预测结果的交叉熵loss。
由于在M2DET的训练过程中,正负样本极其不平衡,即 存在对应真实框的先验框可能只有十来个,但是不存在对应真实框的负样本却有几千个,这就会导致负样本的loss值极大,因此我们可以考虑减少负样本的选取,对于M2DET的训练来讲,常见的情况是取三倍正样本数量的负样本用于训练。这个三倍呢,也可以修改,调整成自己喜欢的数字。
实现代码如下:
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
def softmax_loss(y_true, y_pred):
y_pred = tf.maximum(y_pred, 1e-7)
softmax_loss = -tf.reduce_sum(y_true * tf.log(y_pred),
axis=-1)
return softmax_loss
def conf_loss(neg_pos_ratio = 3,negatives_for_hard = 100):
def _conf_loss(y_true, y_pred):
batch_size = tf.shape(y_true)[0]
num_boxes = tf.to_float(tf.shape(y_true)[1])
labels = y_true[:, :, :-1]
classification = y_pred
cls_loss = softmax_loss(labels, classification)
num_pos = tf.reduce_sum(y_true[:, :, -1], axis=-1)
pos_conf_loss = tf.reduce_sum(cls_loss * y_true[:, :, -1],
axis=1)
# 获取一定的负样本
num_neg = tf.minimum(neg_pos_ratio * num_pos,
num_boxes - num_pos)
# 找到了哪些值是大于0的
pos_num_neg_mask = tf.greater(num_neg, 0)
# 获得一个1.0
has_min = tf.to_float(tf.reduce_any(pos_num_neg_mask))
num_neg = tf.concat( axis=0,values=[num_neg,
[(1 - has_min) * negatives_for_hard]])
# 求平均每个图片要取多少个负样本
num_neg_batch = tf.reduce_mean(tf.boolean_mask(num_neg,
tf.greater(num_neg, 0)))
num_neg_batch = tf.to_int32(num_neg_batch)
max_confs = tf.reduce_max(y_pred[:, :, 1:-1],
axis=2)
# 取top_k个置信度,作为负样本
x, indices = tf.nn.top_k(max_confs * (1 - y_true[:, :, -1]),
k=num_neg_batch)
# 找到其在1维上的索引
batch_idx = tf.expand_dims(tf.range(0, batch_size), 1)
batch_idx = tf.tile(batch_idx, (1, num_neg_batch))
full_indices = (tf.reshape(batch_idx, [-1]) * tf.to_int32(num_boxes) +
tf.reshape(indices, [-1]))
neg_conf_loss = tf.gather(tf.reshape(cls_loss, [-1]),
full_indices)
neg_conf_loss = tf.reshape(neg_conf_loss,
[batch_size, num_neg_batch])
neg_conf_loss = tf.reduce_sum(neg_conf_loss, axis=1)
num_pos = tf.where(tf.not_equal(num_pos, 0), num_pos,
tf.ones_like(num_pos))
total_loss = tf.reduce_sum(pos_conf_loss) + tf.reduce_sum(neg_conf_loss)
total_loss /= tf.reduce_sum(num_pos)
# total_loss = tf.Print(total_loss,[labels,full_indices,tf.reduce_sum(pos_conf_loss)/tf.reduce_sum(num_pos),tf.reduce_sum(neg_conf_loss)/tf.reduce_sum(num_pos),tf.reduce_sum(num_pos)])
return total_loss
return _conf_loss
def smooth_l1(sigma=1.0):
sigma_squared = sigma ** 2
def _smooth_l1(y_true, y_pred):
# y_true [batch_size, num_anchor, 4+1]
# y_pred [batch_size, num_anchor, 4]
regression = y_pred
regression_target = y_true[:, :, :-1]
anchor_state = y_true[:, :, -1]
# 找到正样本
indices = tf.where(keras.backend.equal(anchor_state, 1))
regression = tf.gather_nd(regression, indices)
regression_target = tf.gather_nd(regression_target, indices)
# 计算 smooth L1 loss
# f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma
# |x| - 0.5 / sigma / sigma otherwise
regression_diff = regression - regression_target
regression_diff = keras.backend.abs(regression_diff)
regression_loss = backend.where(
keras.backend.less(regression_diff, 1.0 / sigma_squared),
0.5 * sigma_squared * keras.backend.pow(regression_diff, 2),
regression_diff - 0.5 / sigma_squared
)
normalizer = keras.backend.maximum(1, keras.backend.shape(indices)[0])
normalizer = keras.backend.cast(normalizer, dtype=keras.backend.floatx())
loss = keras.backend.sum(regression_loss) / normalizer
return loss
return _smooth_l1
训练自己的M2det模型
M2det整体的文件夹构架如下:

本文使用VOC格式进行训练。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。

在训练前利用voc2M2det.py文件生成对应的txt。

再运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]

就会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。

在训练前需要修改model_data里面的voc_classes.txt文件,需要将classes改成你自己的classes。

运行train.py即可开始训练。

