近期因为要准备暑期实习以及后期的秋招环节,再一次温习了《新一代高效视频编码H.265/HEVC原理、标准与实现》经典书籍,现在记录下有关阅读心得以及可能面试的问题(所有的答案都是我自己思考的或者网络/书上摘抄的,因为本人水平有限,如果有错误或者需要补充可以私聊我)。
第四章. 预测
1. 预测编码消除了什么冗余?
- 帧内预测模式和IBC模式消除了空间冗余,利用当前图像已编码像素生成预测值。
- 帧间预测模式消除了时间冗余,利用已编码图像的重建像素值生成预测值。
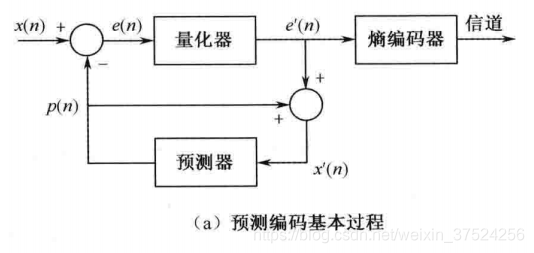
2. 绘制预测编解码的基本过程。
- 当前输入像素值为x(n),p(n)是x(n)的预测值(利用已编码像素的重建值x’(n)预测得到),二者之差就是残差e(n)。
- 残差e(n)经过量化(有损,不可逆),变成e’(n)(其他无损的过程可以忽略不计)。再经过熵编码等步骤,就变成码流在信道上传输了。
- e’(n) 和 p(n) 相加就得到重建值x’(n)(不考虑环路滤波等处理)。x’(n)经过预测器就得到了预测值p(n),即第一步。
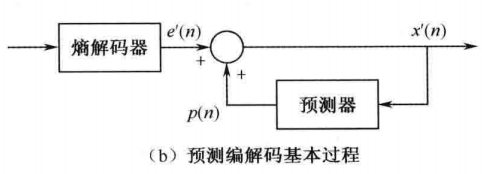
解码过程是编码一部分的逆过程。对码流熵解码得到e’(n),和 p(n) 相加就得到重建值x’(n)。
3. 为什么不采用基于像素的运动估计和运动补偿?(师姐毕设答辩被问过)
- 要给每个像素指定一个MV,需要估计大量的未知量,其解通常并不能反映场景中物体真实的运动情况,而且复杂度过高。
- 要给每个像素指定一个MV,会引入太多bits来signal这些MV,其实是不划算的。
4. 为什么不采用基于区域的运动表示法?
- 基于区域的运动表示法,把一幅图像分成多个区域,每个区域恰好表征一个完整的运动物体。
- 准确的划分方式需要大量的计算才能确定,复杂度过高。
- 由于运动物体形状通常不规则,区域的划分需要大量的信息来表征,可能是不划算的。
5. 常见的运动估计准则

其中,SAD不含乘除法,复杂度低,便于硬件实现,使用最广泛。
6. HEVC帧内预测
HEVC中35种IPM是在PU的基础上定义的,但是具体实现是以TU为单位的。
帧内预测时,因为PU之间存在依赖关系,PU必须包含一个或者多个完整TU。PU可以以四叉树形式划分TU,PU内所有TU共享一种IPM。
帧内预测的步骤主要有3个:
① 判断当前TU相邻参考像素是否可用。
- 如果TU处于图像、Slice、Tile边界,相邻像素可能不存在或者不可用,此时用最邻近像素进行填充。所有都不可用,用pow(2,bitDepth-1)填充(8:128,10:512)。
② 参考像素滤波。
- DC模式和4 * 4 大小的TU不进行滤波。
- TU越大,进行参考像素滤波的模式越多,具体可查阅标准。
- 针对 32 *32大小的TU,在SPS中开启强滤波选项,且满足一定条件时(通过公式判断出上行或者左列参考像素变化缓慢),可以进行强滤波。
- 常规滤波使用一个3抽头滤波器,滤波系数是[0.25, 0.5, 0.25]。
- 强滤波在水平和垂直两个方向进行,每个像素滤波后的值和距离左上角像素点的距离有关。
③ 根据滤波后的参考像素值计算TU的预测像素值。
- Planar模式:相当于水平、垂直两个方向预测值的平均值。
- DC模式:首先计算当前TU左侧和上方参考像素的平均值dcValue,再根据像素位置,对dcValue进行调整得到预测值。
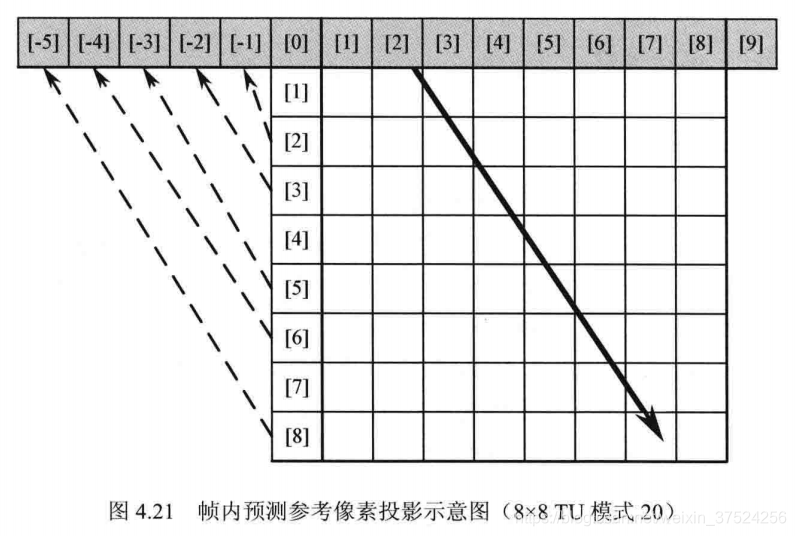
- 角度模式:
(1) 首先根据模式编号,查表得到在水平和垂直方向上的偏移值。
(2) 再用“投影像素法”将某方向的像素投影到另外的方向,便于计算。
(3) 最后根据相关公式利用参考像素计算出预测值。
7. TZSearch快速搜索算法
- 确定搜索起点(AMVP确定若干MVP,RDcheck找出最优的MVP作为搜索的起点)
- 以1为步长,按照下图所示的菱形或者正方形模板在搜索范围内进行搜索,步长以2的整数次幂递增,以RD cost最小的点作为该步骤的搜索结果。
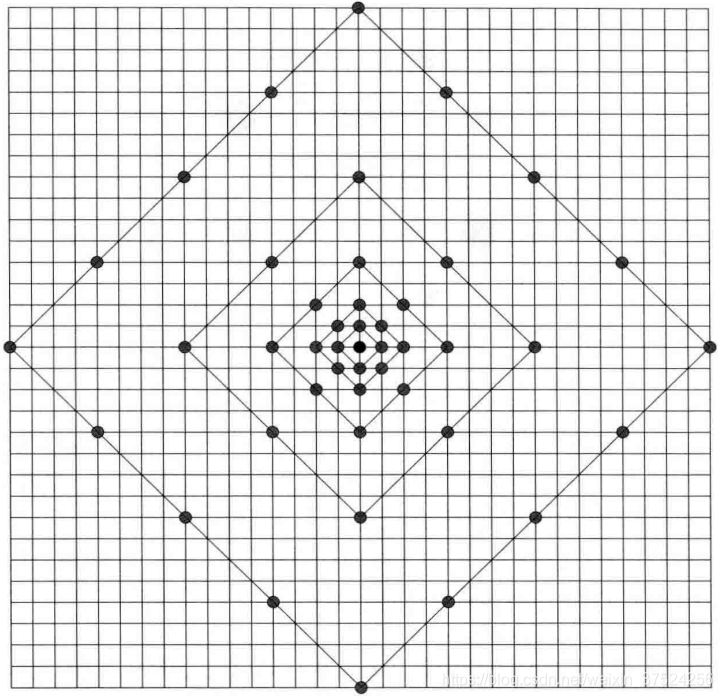
- 若上一步最优点对应的步长是1,在最优点附近做两点搜索。
- 若上上步最优点对应的步长大于某阈值,以该点为中心,在一定范围内做全搜索,选择RD cost最小的点为最优点。然后重复菱形或者正方形模板在搜索范围内进行搜索,直到临近两次细化搜索得到的最优点一致时,停止搜索,得到最优MV。
8. Merge和AMVP技术的联系与区别
- 联系:都使用了空域和时域MV预测的思想,通过建立候选MV列表,选取最优MV作为当前PU的预测MV。
- 区别:
① Merge是一种编码模式。该模式下,MV = MVP,不用编码MVD。AMVP只是用于MVP的预测,用作构建MVPcand以及找到ME的起始点。
② 二者MVPcand的构建方式和长度不同。
Merge:4个空域 + 1个时域 = 5个MVP
AMVP:2个空域 + 1个时域 ===> 合并保留前两个MVP
第五章. 变换
1. 变换编码消除了什么冗余?
频域冗余。
变换编码把残差从空间域转换到变换域,以变换系数的形式加以表示。预测后残差大多为0或者很小,能量可以从空间域的分散分布转换为变换域的相对集中分布。
2. HEVC使用的DCT和DST变换
- 使用整数变换,既避免了舍入误差导致的编解码失配问题,也提高了运行速度。
- DCT使用Ⅱ类DCT,逆变换对应于Ⅲ类DCT。支持的尺寸除了AVC支持的 4 * 4 、8 * 8,还有大尺寸的 16 * 16 和 32 * 32。
- DST使用Ⅶ类DST,逆变换对应于Ⅵ类DST。仅支持帧内的4 * 4模式使用 4 * 4 的整数DST,原因在于帧内预测残差有如下特征:距离预测像素越远,预测残差幅度越大,更适合使用DST。
- DCT和DST变换通过一系列操作,如二维分解为一维,再分解成矩阵相乘,部分标量因子放在后续的量化部分进行操作。
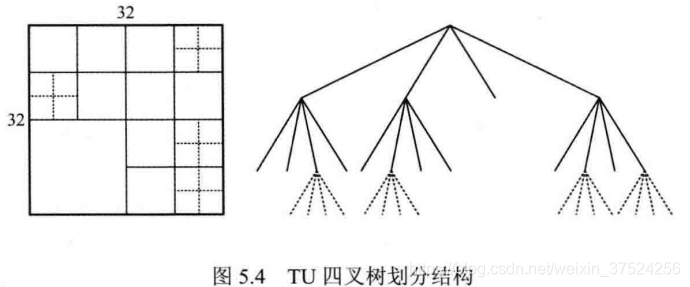
3. TU, 变换单元
-
TU是HEVC中变换、量化与熵编码的基本单位,支持4 * 4 、8 * 8、16 * 16 和 32 * 32的大小。
-
CU可以以四叉树划分TU。
-
PU和TU都是由CU划分得到,二者无确定关系。一个PU可以含多个TU,一个TU也可以跨越多个PU。
-
但是,在intra块中,PU可以包含1个或者多个TU,但是一个TU最多只能对应一个PU,这是因为相邻PU存在依赖关系,已编码的PU须用于预测与之相邻的PU。
4. 哈达玛变换 -
哈达玛矩阵元素都是±1,是正交对称矩阵。
-
哈达玛变换仅含有加减法运算,运算复杂度低,容易实现。
-
AVC中,用于intra 16 * 16块DC系数的变换,进一步去除相关性。HEVC中因为使用大TU同样可以很好地去除相关性,所以取消了该步骤。
-
哈达玛变换用于计算残差信号SATD。SATD一定程度上可以反应残差在频域中的大小,性能接近DCT且复杂度低,所以可以用于快速模式选择。
-
HEVC的帧内预测RMD过程就是用SATD先筛选出若干个候选IPM,来节省时间。
-
HEVC的帧间预测亚像素精度ME也使用了SATD。这是因为与整像素ME相比,亚像素ME匹配误差不会太大,需要考虑残差在变换域的特征,所以用SATD做预测误差衡量准则可以提高编码性能。
第六章. 量化
1. 视频编码中什么步骤导致了有损?
量化。
量化是指将信号的连续取值(或者大量可能的离散值)映射为有限多个离散幅值的过程,实现信号取值多对一的映射。这是视频编码产生失真的根本原因。
2. 量化为何可以取得一定的压缩效果?
视频编码中,残差进行DCT和DST后,变换系数一般具有较大的动态范围。对变化系数进行量化可以有效减小信号取值空间,从而取得更好的压缩效果。
3. HEVC中的传统标量量化

对于I图像,f取1/3。对于P/B图像,f取1/6。
关于这个f的取值问题,我曾经分享过一篇博客,也和大佬讨论过这个取值问题:
https://www.cnblogs.com/TaigaCon/p/4266686.html?from=timeline
大佬:“我的理解就是控制舍入的操作,可以作为一个参数来调节。但是调节的力度是比较微弱的。在一帧内都采用定QP 编码时调节这个参数应该会有一定的细微差别。但实际编码中会使用块级的码控,他的作用就不明显了,甚至可以忽略了。而且文中也介绍了要和纹理强度联系起来调更好,就是自适应的调节,又增加了难度。文中没有回答的一个问题是为什么帧内帧间使用的f不一样?”
我:我浅显的理解是,f的取值可能和帧内、帧间预测的编码效率、残差分布特性有关。帧间预测的编码效率相比帧内高,残差的DCT系数相比更集中在0值附近,f取小值保证了压缩效率。而I帧帧内预测的去相关能力没有那么强,增大f,减小量化死区,作为后续帧的参考帧一定程度上保证了细节和图像质量。我之前没怎么研究过这些,是今天看书临时看到的,也不知道是不是想的有问题。
4. HEVC中的RDOQ
传统的标量量化器是以失真最小为目的进行设计的。RDOQ将率失真优化与量化过程相结合。对于一个变化系数,给定多个可选量化值,利用RDO准则从中选出一个最优的量化值。
HM软件内的RDOQ步骤:
-
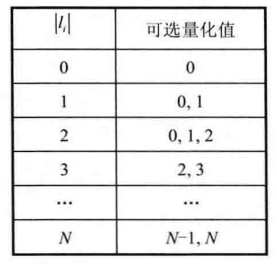
确定当前TU每个系数的可选量化值,进行预量化。根据|Li|大小确定可选量化值
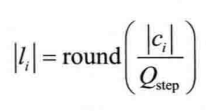
-
利用RDO准则确定当前TU所有系数最优量化值。
-
此外,利用RDO准则确定当前TU每一个系数块组(CG)是否量化为全零组。(若整个CG量化为全零,CABAC时只需要1个bit就可以signal整个CG,对于当前CG仅含极少个数幅值较小的非零系数,可能有一定的率失真性能提升。)
-
利用RDO准则确定当前TU“最后一个非零系数”的位置。
5. HEVC中的量化组QG
- HEVC中新引入了QG的概念,规定一个CTB可以包含一个或者固定大小的QG,同一个QG内所有含有非零系数的CU共享一个QP,不同QG可以用不同的QP。
- QG是固定的正方形像素块,大小N由PPS指定,必须处于最大CU和最小CU之间(包含)。CU和QG没有固定的大小关系,可以互相完整的包含彼此。
- 当QG包含多个CU时,所有CU公用当前QG预测QP;当CU包含多个QG时,CU的QP等于第一个QG的预测QP。
6. 量化矩阵
- 量化矩阵的原理是对不同位置的系数使用不同的量化步长。利用人眼对视频中高频细节不敏感的特征,对高频系数使用较大的量化步长,低频系数使用较小的量化步长。
- 量化矩阵作用于比例缩放过程中,变换后的DCT / DST系数将与相同大小的量化矩阵中对应位置的系数相除,所得的结果作为量化模块的输入。

