近期因为要准备暑期实习以及后期的秋招环节,再一次温习了《新一代高效视频编码H.265/HEVC原理、标准与实现》经典书籍,现在记录下有关阅读心得以及可能面试的问题(所有的答案都是我自己思考的或者网络/书上摘抄的,因为本人水平有限,如果有错误或者需要补充可以私聊我)。
第九章. 网络适配层
1. 为什么要设计NAL+VCL两层结构?
- VCL注重编码部分,重点在于去除时间/空间/视觉等冗余的编码算法部分,即负责高效的视频内容表达。
- NAL负责用恰当的方式对数据进行打包和传送。NAL可以为复杂的视频数据增加友好的网络应用接口,以适应更好的网络环境。
- NAL可以根据压缩比特流的内容特性把他们划分成若干个数据段,对每个数据段封装+标识其内容特性(放在NALU header信息中)即生成了NALU。
- 比如说,在发生网络拥塞时,要选择性丢弃某些包,就可以选择重要性最低的分组进行丢弃(如不作为参考帧的编码帧)。由于NALU header中有相关的特性信息,所以无需再进行解码、分析码流等操作,这可以体现网络亲和性强的特性。
2. 阐述IRAP Intra Random Access Point
可以参考殷汶杰大神的blog:
http://blog.sina.com.cn/s/blog_520811730101jlsa.html
- IRAP都是I帧,把视频流分成多个相对独立的区域CVS。包含有三种类型:IDR, CRA, BLA。
- 其中,IDR和264里一样,引领封闭GOP。IDR会导致DPB(Decoded Picture Buffer 参考帧列表)清空,所以对于IDR帧来说,在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容。
- CRA是265新增的类型,引领开放GOP。不同于IDR,CRA后的帧可以跨过CRA参考前一个CVS的帧,独立性较差,但是某种程度上可以提高编码效率(参考帧数量和选择增多)。
- BLA书上的叙述我没太看懂。这里引用一下网络上的解答:
BLA图像可以用于拼接码率的应用中。当解码器遇到BLA图像时,会丢弃其RASL图像,而遇到CRA图像时则不会丢弃RASL。而RADL在两种情况下都需要被解码。
3. NALU Header
- HEVC NALU Header长度固定为2字节,反映了该NALU的内容特性。

- 只要根据NALU Header内的nuh_temporal_id_plus1就可以获取该NALU的重要性,配合nal_unit_type可以实现时域分级。id小的图像不会参考大的图像。
- 264的NAL header只有1个字节,包含1bit禁止位 + 2 bits nal_ref_idc(越大说明该NAL越重要,最高优先级11,最低优先级00)+ 5bits nal_type。
4. 接入单元AU的概念
- 多个按照解码顺序排列的NALU,解码后正好组成一幅图像。
- AU可看成压缩视频比特流的基本单元,压缩视频流由多个按顺序排列的AU组成。
5. 分组流应用
- 网络视频传输时,常采用分组流应用。分组流应用是把NALU作为网络分组的有效载荷,比如基于RTP/UDP/IP的实时视频通信。
- RTP分组由RTP header + RTP 载荷组成。
- 有三大类:单NALU分组(1v1),聚合分组AP(1分组 vs 多NALU),分片分组FP(多分组 vs 1NALU)。
- RTP载荷的前两字节结构与NALU header结构相同。单NALU分组时,对NALU header进行复制。AP和FP时,载荷头的nal_unit_type分别为48、49。
第十章. 编解码并行处理
1. 并行处理的类型
① 功能并行。
- 将应用程序划为相互独立的功能模块来并行执行,也称为流水线并行。比如把预测、熵编码等按功能分开并行执行。
- 优点:
充分利用时间上的并行性
适用于硬件实现 - 缺点:
容易载荷失衡,效率下降。
运算单元之间的数据通信在数据量大的情况下需要额外资源来存储。
扩展性差。
② 数据并行。
- 将数据信息划为相互独立的部分,每部分用不同的运算单元执行,并行处理。比如Tile,Slice,波前并行处理WPP。
- 优点:
容易实现负载均衡。
扩展性强。
相互独立的数据信息(如Tile、Slice)可以不用运算单元之间的通信。
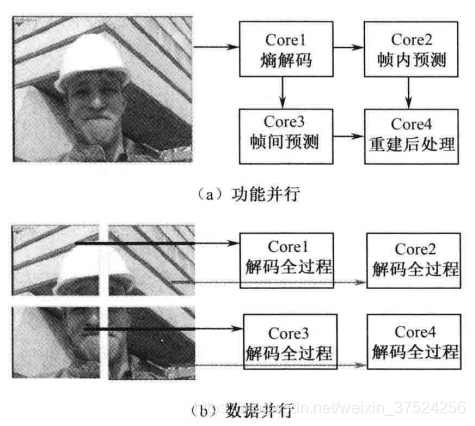
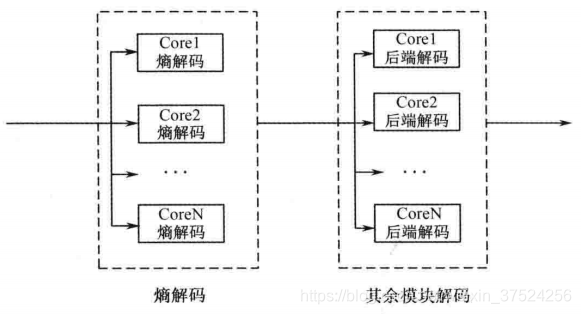
2. HEVC中的编解码并行处理方式
- 混合了功能并行和数据并行。
- 熵解码模块和其他模块组成一级流水线。两个模块内部进行数据并行。
- 其中,数据并行可采用基于Tile或者WPP的方式。
3. 为什么Tile级并行比Slice级并行编码效率更高?
- Tile和Slice之间都是相互独立的,但是形状不同。Slice一般为条带状,横向跨度大,不一定规则,相关性低;而Tile成矩形状,更规则,相关性更强。
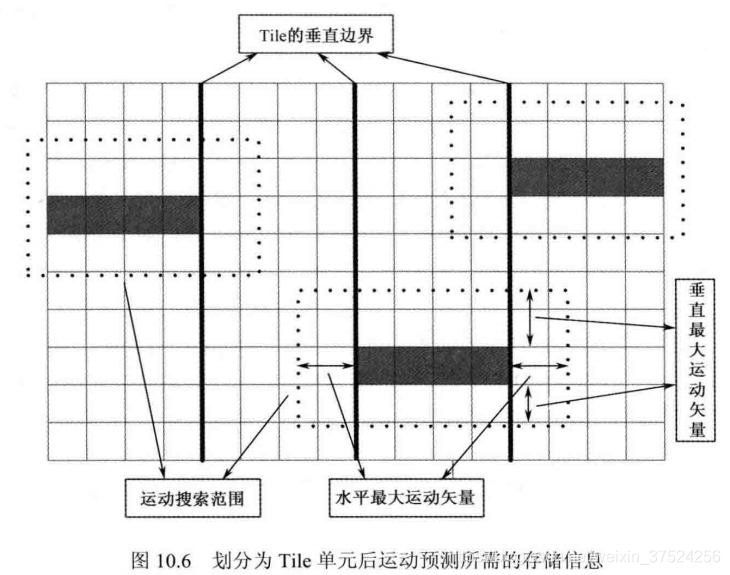
4.基于Tile的数据并行
- 由于Tile之间互相独立(不考虑跨Tile的去块滤波 SAO),所以无需进行运算单元之间的通信。
- Tile可以减少运动预测需要的缓冲数量。
解释:Inter prediction时,需要为ME存储相应的参考信息。由于Tile改变了图像CTB的扫描顺序(整幅图像的光栅扫描变为Tile+CTB的两级光栅扫描),所以为了获取参考块像素信息,需要存储的像素点数可以有效减少。之前需要横跨整幅图像的宽度,现在只用跨过对应Tile的宽度即可。 - 但是,Tile的引入也会有代价,其破坏了Tile边界附近的相关性。此外,CABAC会在Tile边界进行概率模型更新,所以降低了编码效率。
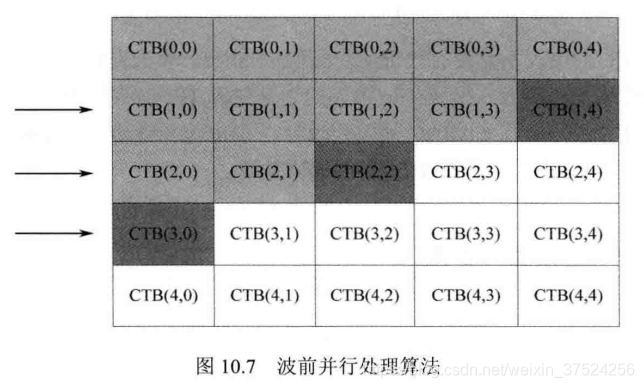
5. 波前并行处理WPP
- WPP是基于CTB级的数据并行方式,多行CTB同时处理,后一行处理比前一行滞后两个CTB来保证依赖关系不受到破坏。
- 扩展性好,分辨率增加,CTB级并行的线程数目可以方便增加。分配给每个运算单元的数据信息量少,所以容易负载均衡。
- 熵解码的上下文模型更新会带来一些问题,比如输出码率不稳定(开始和结束时候的运算单元数量变化),可以通过重叠波前并行处理方法解决。