storm drpc JavaAPI调用报错 conf初始化错误解决如下
Map config = Utils.readDefaultConfig();
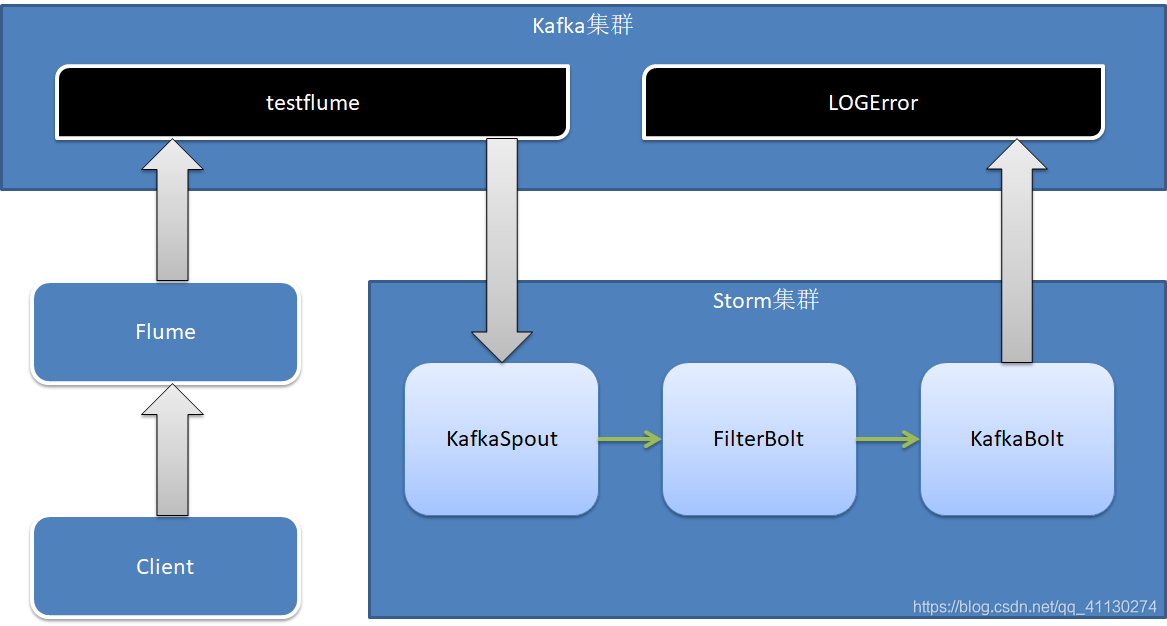
Kafka、Flume、Storm 结合学习案例
flume 写入 kafka, storm作为kafka消费者处理消息, 处理完再作为生产者给kafka写入消息
flume 配置部分
使用远程调用flume 即avro source
传入kafka中 即kafka sink
具体可以在flume官网中查看kafka配置
#定义三大组件的名称
ag2.sources = source2
ag2.sinks = sink2
ag2.channels = channel2
# 配置source组件
ag2.sources.source2.type = avro
ag2.sources.source2.bind = centos01
ag2.sources.source2.port= 4141
# 配置sink组件
ag2.sinks.sink2.type = org.apache.flume.sink.kafka.KafkaSink
ag2.sinks.sink2.kafka.bootstrap.servers = centos01:9092,centos02:9092,centos03:9092
ag2.sinks.sink2.kafka.topic = testflume
ag2.sinks.sink2.kafka.producer.acks = 1
ag2.sinks.sink2.kafka.batchSize= 100
# channel组件配置
ag2.channels.channel2.type = memory
ag2.channels.channel2.capacity = 100000
## event条数
ag2.channels.channel2.transactionCapacity = 600
##flume事务控制所需要的缓存容量600条event
# 绑定source、channel和sink之间的连接
ag2.sources.source2.channels = channel2
ag2.sinks.sink2.channel = channel2
flume客户端调用
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
/**
* Flume官网案例
* http://flume.apache.org/FlumeDeveloperGuide.html
* @author root
*/
public class RpcClientDemo {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("centos01", 4141); 调用的host和端口,在flumesource中配置
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
for (int i = 100; i < 2000; i++) {
String sampleData = "Hello Flume!ERROR" + i;
client.sendDataToFlume(sampleData);
System.out.println("发送数据:" + sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the
// above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of
// the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
这里会自己创建topic,不用事先创建
此时可以打开该topic的消费者,查看到数据则表示正常
再使用storm处理kafka消息
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.bolt.KafkaBolt;
import org.apache.storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import org.apache.storm.kafka.bolt.selector.DefaultTopicSelector;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.TopologyBuilder;
import java.util.Arrays;
import java.util.Properties;
public class KafkaTopology {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
String topic = "testflume";
KafkaSpoutConfig.Builder<String, String> kafkaBuilder = KafkaSpoutConfig.builder("centos01:9092,centos02:9092,centos03:9092", topic);
kafkaBuilder.setGroupId("testgroup");
KafkaSpoutConfig<String, String> kafkaSpoutConfig = kafkaBuilder.build();
org.apache.storm.kafka.spout.KafkaSpout<String, String> kafkaSpout = new KafkaSpout<String, String>(kafkaSpoutConfig);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", kafkaSpout, 2);
builder.setBolt("print-Bolt", new PointBolt(), 2).localOrShuffleGrouping("kafka-spout");
Config config = new Config();
Properties props = new Properties();
/*
* 指定broker的地址清单,清单里不需要包含所有的broker地址,生产者会从给定的broker里查找其他broker的信息。
* 不过建议至少要提供两个broker的信息作为容错。
*/
props.put("bootstrap.servers", "centos01:9092,centos02:9092,centos03:9092");
/*
* acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
* acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
* acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
* acks=all : 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
*/
props.put("acks", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaBolt bolt = new KafkaBolt<String, String>()
.withProducerProperties(props)
.withTopicSelector(new DefaultTopicSelector("LogError"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper<>());
builder.setBolt("kafka_bolt", bolt, 2).shuffleGrouping("print-Bolt");
if (args.length > 0){
config.setDebug(false);
StormSubmitter.submitTopology("kafka-t", config, builder.createTopology());
}else {
config.setDebug(false);
config.setNumWorkers(2);
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", config, builder.createTopology());
}
}
}
由三部分组成, kafkaspout -> pointbolt -> kafkabolt 其中pointbolt为自定义bolt,用于处理消息,两个kafka组件为传递消息
package stu.storm.kfc;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.IBasicBolt;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.IWindowedBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class PointBolt extends BaseBasicBolt {
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getString(4);
System.err.println("Accept: " + line);
// 包含ERROR的行留下
if (line.contains("ERROR")) {
System.err.println("Filter: " + line);
collector.emit(new Values(line));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("message"));
}
}
可以看到kafkaspout可以由自带的KafkaSpoutConfig构建,而kafkabolt需要自己导入配置
主要遇到的问题就是kafkabolt会报confmissing,这个就是没有配置好文件的原因。
maven如下
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>1.1.0</version>
</dependency>
