改文章为转载,出处为http://blog.csdn.net/l1028386804/article/details/79441007,本文已按照作者要求转载
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/79441007
一、前言
本博文是基于《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》,请先阅读《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》
首先我们启动服务器上的Storm、Kafka、Flume、Zookeeper和MySQL,具体参见博文《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》。
二、简单介绍
为了方便,这里我们只是简单的向/home/flume/log.log中追加单词,每行一个单词,利用Storm接收每个单词,将单词计数更新到数据库,具体的逻辑为,如果数据库中没有相关单词,则将数据插入数据库,如果存在相关单词,则更新数据库中的计数。具体SQL逻辑参见博文《MySQL之——实现无数据插入,有数据更新》
三、程序实现
1、创建项目
创建Maven项目结构如下:
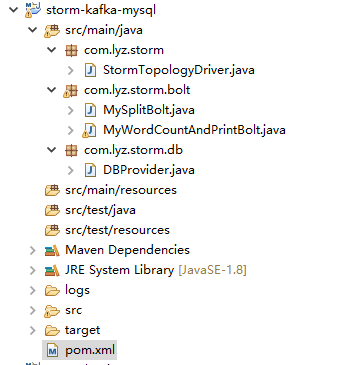
2、配置pom.xml
-
<?xml version="1.0" encoding="UTF-8"?>
-
<project xmlns="http://maven.apache.org/POM/4.0.0"
-
xmlns:xsi=
"http://www.w3.org/2001/XMLSchema-instance"
-
xsi:schemaLocation=
"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
-
<modelVersion>4.0.0
</modelVersion>
-
<groupId>com.lyz
</groupId>
-
<artifactId>storm-kafka-mysql
</artifactId>
-
<version>1.0-SNAPSHOT
</version>
-
-
<dependencies>
-
<dependency>
-
<groupId>org.apache.storm
</groupId>
-
<artifactId>storm-core
</artifactId>
-
<version>1.1.0
</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.storm
</groupId>
-
<artifactId>storm-kafka
</artifactId>
-
<version>1.1.0
</version>
-
</dependency>
-
<dependency>
-
<groupId>redis.clients
</groupId>
-
<artifactId>jedis
</artifactId>
-
<version>2.7.3
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>mysql
</groupId>
-
<artifactId>mysql-connector-java
</artifactId>
-
<version>5.1.28
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>c3p0
</groupId>
-
<artifactId>c3p0
</artifactId>
-
<version>0.9.1.2
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>org.apache.kafka
</groupId>
-
<artifactId>kafka_2.12
</artifactId>
-
<version>1.0.0
</version>
-
<exclusions>
-
<exclusion>
-
<groupId>org.apache.zookeeper
</groupId>
-
<artifactId>zookeeper
</artifactId>
-
</exclusion>
-
<exclusion>
-
<groupId>log4j
</groupId>
-
<artifactId>log4j
</artifactId>
-
</exclusion>
-
<exclusion>
-
<groupId>org.slf4j
</groupId>
-
<artifactId>slf4j-log4j12
</artifactId>
-
</exclusion>
-
</exclusions>
-
</dependency>
-
-
<dependency>
-
<groupId>org.apache.kafka
</groupId>
-
<artifactId>kafka-clients
</artifactId>
-
<version>1.0.0
</version>
-
</dependency>
-
-
</dependencies>
-
<build>
-
<plugins>
-
<plugin>
-
<artifactId>maven-assembly-plugin
</artifactId>
-
<configuration>
-
<descriptorRefs>
-
<descriptorRef>jar-with-dependencies
</descriptorRef>
-
</descriptorRefs>
-
<archive>
-
<manifest>
-
<!--告诉运行的主类是哪个,注意根据自己的情况,下面的包名做相应的修改-->
-
<mainClass>com.lyz.storm.StormTopologyDriver
</mainClass>
-
</manifest>
-
</archive>
-
</configuration>
-
<executions>
-
<execution>
-
<id>make-assembly
</id>
-
<phase>package
</phase>
-
<goals>
-
<goal>single
</goal>
-
</goals>
-
</execution>
-
</executions>
-
</plugin>
-
<plugin>
-
<groupId>org.apache.maven.plugins
</groupId>
-
<artifactId>maven-compiler-plugin
</artifactId>
-
<configuration>
-
<source>1.8
</source>
-
<target>1.8
</target>
-
</configuration>
-
</plugin>
-
</plugins>
-
</build>
-
</project>
3、实现单词分割计数的MySplitBolt类
-
package com.lyz.storm.bolt;
-
-
import org.apache.storm.topology.BasicOutputCollector;
-
import org.apache.storm.topology.OutputFieldsDeclarer;
-
import org.apache.storm.topology.base.BaseBasicBolt;
-
import org.apache.storm.tuple.Fields;
-
import org.apache.storm.tuple.Tuple;
-
import org.apache.storm.tuple.Values;
-
-
/
-
* 这个Bolt模拟从kafkaSpout接收数据,并把数据信息发送给MyWordCountAndPrintBolt的过程。
-
* @author liuyazhuang
-
-
/
-
public
class MySplitBolt extends BaseBasicBolt {
-
-
private
static
final
long serialVersionUID =
4482101012916443908L;
-
-
@Override
-
public void execute(Tuple input, BasicOutputCollector collector) {
-
//1、数据如何获取
-
//如果StormTopologyDriver中的spout配置的是MyLocalFileSpout,则用的是declareOutputFields中的juzi这个key
-
//byte[] juzi = (byte[]) input.getValueByField("juzi");
-
//2、这里用这个是因为StormTopologyDriver这个里面的spout用的是KafkaSpout,而KafkaSpout中的declareOutputFields返回的是bytes,所以下面用bytes,这个地方主要模拟的是从kafka中获取数据
-
byte[] juzi = (
byte[]) input.getValueByField(
"bytes");
-
//2、进行切割
-
String[] strings =
new String(juzi).split(
" ");
-
//3、发送数据
-
for (String word : strings) {
-
//Values对象帮我们生成一个list
-
collector.emit(
new Values(word,
1));
-
}
-
}
-
-
@Override
-
public void declareOutputFields(OutputFieldsDeclarer declarer) {
-
declarer.declare(
new Fields(
"word",
"num"));
-
}
-
}
4、实现入库操作的MyWordCountAndPrintBolt类
-
package com.lyz.storm.bolt;
-
-
import java.sql.Connection;
-
import java.sql.SQLException;
-
import java.sql.Statement;
-
import java.util.Map;
-
-
import org.apache.storm.task.TopologyContext;
-
import org.apache.storm.topology.BasicOutputCollector;
-
import org.apache.storm.topology.OutputFieldsDeclarer;
-
import org.apache.storm.topology.base.BaseBasicBolt;
-
import org.apache.storm.tuple.Tuple;
-
-
import com.lyz.storm.db.DBProvider;
-
-
-
/
-
* 用于统计分析,并且把统计分析的结果存储到mysql中。
-
* @author liuyazhuang
-
-
/
-
public
class MyWordCountAndPrintBolt extends BaseBasicBolt {
-
-
private
static
final
long serialVersionUID =
5564341843792874197L;
-
private DBProvider provider;
-
@Override
-
public void prepare(Map stormConf, TopologyContext context) {
-
//连接redis---代表可以连接任何事物
-
provider =
new DBProvider();
-
super.prepare(stormConf,context);
-
}
-
-
@Override
-
public void execute(Tuple input, BasicOutputCollector collector) {
-
String word = (String) input.getValueByField(
"word");
-
Integer num = (Integer) input.getValueByField(
"num");
-
Connection conn =
null;
-
Statement stmt =
null;
-
try {
-
conn = provider.getConnection();
-
stmt = conn.createStatement() ;
-
stmt.executeUpdate(
"INSERT INTO word_count (word, count) VALUES ('" + word +
"', " + num +
") ON DUPLICATE KEY UPDATE count = count + " + num) ;
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
finally{
-
if(stmt !=
null){
-
try {
-
stmt.close();
-
stmt =
null;
-
}
catch (Exception e2) {
-
e2.printStackTrace();
-
}
-
}
-
if(conn !=
null){
-
try {
-
conn.close();
-
conn =
null;
-
}
catch (Exception e2) {
-
e2.printStackTrace();
-
}
-
}
-
}
-
}
-
-
@Override
-
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
-
//todo 不需要定义输出的字段
-
}
-
}
5、实现操作数据库的DBProvider类
-
package com.lyz.storm.db;
-
-
import java.beans.PropertyVetoException;
-
import java.sql.Connection;
-
import java.sql.PreparedStatement;
-
import java.sql.ResultSet;
-
import java.sql.SQLException;
-
-
import com.mchange.v2.c3p0.ComboPooledDataSource;
-
-
/
-
* JDBC操作数据库
-
* @author liuyazhuang
-
-
/
-
public
class DBProvider {
-
-
private
static ComboPooledDataSource source ;
-
private
static
final String DB_DRIVER =
"com.mysql.jdbc.Driver";
-
private
static
final String DB_URL =
"jdbc:mysql://127.0.0.1:3306/sharding_0?useUnicode=true&characterEncoding=UTF-8&useOldAliasMetadataBehavior=true";
-
private
static
final String USER =
"root";
-
private
static
final String PASSWORD =
"root";
-
private
static Connection connection;
-
-
static{
-
try {
-
source =
new ComboPooledDataSource();
-
source.setDriverClass(DB_DRIVER);
-
source.setJdbcUrl(DB_URL);
-
source.setUser(USER);
-
source.setPassword(PASSWORD);
-
source.setInitialPoolSize(
10);
-
source.setMaxPoolSize(
20);
-
source.setMinPoolSize(
5);
-
source.setAcquireIncrement(
1);
-
source.setMaxIdleTime(
3);
-
source.setMaxStatements(
3000);
-
source.setCheckoutTimeout(
2000);
-
}
catch (PropertyVetoException e) {
-
e.printStackTrace();
-
}
-
}
-
-
/
-
* 获取数据库连接
-
-
@return 数据库连接
-
/
-
public Connection getConnection() throws SQLException {
-
connection = source.getConnection();
-
return connection;
-
}
-
-
-
//关闭操作
-
public static void closeConnection(Connection con){
-
if(con!=
null){
-
try {
-
con.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
-
public static void closeResultSet(ResultSet rs){
-
if(rs!=
null){
-
try {
-
rs.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
-
public static void closePreparedStatement(PreparedStatement ps){
-
if(ps!=
null){
-
try {
-
ps.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
}
6、实现程序的入口类StormTopologyDriver
-
package com.lyz.storm;
-
-
import org.apache.storm.Config;
-
import org.apache.storm.LocalCluster;
-
import org.apache.storm.StormSubmitter;
-
import org.apache.storm.generated.StormTopology;
-
import org.apache.storm.kafka.KafkaSpout;
-
import org.apache.storm.kafka.SpoutConfig;
-
import org.apache.storm.kafka.ZkHosts;
-
import org.apache.storm.topology.TopologyBuilder;
-
-
import com.lyz.storm.bolt.MySplitBolt;
-
import com.lyz.storm.bolt.MyWordCountAndPrintBolt;
-
-
/*
-
* 这个Driver使Kafka、strom、mysql进行串联起来。
-
-
这个代码执行前需要创建kafka的topic,创建代码如下:
-
* [root@liuyazhuang kafka]# bin/kafka-topics.sh --create --zookeeper liuyazhuang1:2181 --replication-factor 1 -partitions 3 --topic wordCount
-
-
接着还要向kafka中传递数据,打开一个shell的producer来模拟生产数据
-
* [root@liuyazhuang kafka]# bin/kafka-console-producer.sh --broker-list liuyazhuang:9092 --topic wordCount
-
* 接着输入数据
-
-
@author liuyazhuang
-
*/
-
public
class StormTopologyDriver {
-
-
public static void main(String[] args) throws Exception {
-
//1、准备任务信息
-
TopologyBuilder topologyBuilder =
new TopologyBuilder();
-
SpoutConfig spoutConfig =
new SpoutConfig(
new ZkHosts(
"192.168.209.121:2181"),
"wordCount",
"/wordCount",
"wordCount");
-
topologyBuilder.setSpout(
"KafkaSpout",
new KafkaSpout(spoutConfig),
2);
-
topologyBuilder.setBolt(
"bolt1",
new MySplitBolt(),
4).shuffleGrouping(
"KafkaSpout");
-
topologyBuilder.setBolt(
"bolt2",
new MyWordCountAndPrintBolt(),
2).shuffleGrouping(
"bolt1");
-
-
//2、任务提交
-
Config config =
new Config();
-
config.setNumWorkers(
2);
-
StormTopology stormTopology = topologyBuilder.createTopology();
-
-
if(args !=
null && args.length >
0){
-
StormSubmitter.submitTopology(args[
0], config, topologyBuilder.createTopology());
-
}
else{
-
//本地模式
-
LocalCluster localCluster =
new LocalCluster();
-
localCluster.submitTopology(
"wordcount",config,stormTopology);
-
}
-
-
}
-
}
7、创建数据库
执行如下脚本创建数据库
-
create
database sharding_0;
-
CREATE
TABLE
word_count (
-
id
int(
11)
NOT
NULL AUTO_INCREMENT,
-
word
varchar(
255)
DEFAULT
'',
-
count
int(
11)
DEFAULT
NULL,
-
PRIMARY
KEY (
id),
-
UNIQUE
KEY
word (
word)
USING BTREE
-
)
ENGINE=
InnoDB AUTO_INCREMENT=
233
DEFAULT
CHARSET=utf8;
至此,我们的程序案例编写完成。
四、温馨提示
大家可以到链接http://download.csdn.net/download/l1028386804/10269075下载完整的Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(程序案例篇)源代码
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/79441007
一、前言
本博文是基于《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》,请先阅读《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》
首先我们启动服务器上的Storm、Kafka、Flume、Zookeeper和MySQL,具体参见博文《Storm之——Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(环境搭建篇)》。
二、简单介绍
为了方便,这里我们只是简单的向/home/flume/log.log中追加单词,每行一个单词,利用Storm接收每个单词,将单词计数更新到数据库,具体的逻辑为,如果数据库中没有相关单词,则将数据插入数据库,如果存在相关单词,则更新数据库中的计数。具体SQL逻辑参见博文《MySQL之——实现无数据插入,有数据更新》
三、程序实现
1、创建项目
创建Maven项目结构如下:
2、配置pom.xml
-
<?xml version="1.0" encoding="UTF-8"?>
-
<project xmlns="http://maven.apache.org/POM/4.0.0"
-
xmlns:xsi=
"http://www.w3.org/2001/XMLSchema-instance"
-
xsi:schemaLocation=
"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
-
<modelVersion>4.0.0
</modelVersion>
-
<groupId>com.lyz
</groupId>
-
<artifactId>storm-kafka-mysql
</artifactId>
-
<version>1.0-SNAPSHOT
</version>
-
-
<dependencies>
-
<dependency>
-
<groupId>org.apache.storm
</groupId>
-
<artifactId>storm-core
</artifactId>
-
<version>1.1.0
</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.storm
</groupId>
-
<artifactId>storm-kafka
</artifactId>
-
<version>1.1.0
</version>
-
</dependency>
-
<dependency>
-
<groupId>redis.clients
</groupId>
-
<artifactId>jedis
</artifactId>
-
<version>2.7.3
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>mysql
</groupId>
-
<artifactId>mysql-connector-java
</artifactId>
-
<version>5.1.28
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>c3p0
</groupId>
-
<artifactId>c3p0
</artifactId>
-
<version>0.9.1.2
</version>
-
</dependency>
-
-
<dependency>
-
<groupId>org.apache.kafka
</groupId>
-
<artifactId>kafka_2.12
</artifactId>
-
<version>1.0.0
</version>
-
<exclusions>
-
<exclusion>
-
<groupId>org.apache.zookeeper
</groupId>
-
<artifactId>zookeeper
</artifactId>
-
</exclusion>
-
<exclusion>
-
<groupId>log4j
</groupId>
-
<artifactId>log4j
</artifactId>
-
</exclusion>
-
<exclusion>
-
<groupId>org.slf4j
</groupId>
-
<artifactId>slf4j-log4j12
</artifactId>
-
</exclusion>
-
</exclusions>
-
</dependency>
-
-
<dependency>
-
<groupId>org.apache.kafka
</groupId>
-
<artifactId>kafka-clients
</artifactId>
-
<version>1.0.0
</version>
-
</dependency>
-
-
</dependencies>
-
<build>
-
<plugins>
-
<plugin>
-
<artifactId>maven-assembly-plugin
</artifactId>
-
<configuration>
-
<descriptorRefs>
-
<descriptorRef>jar-with-dependencies
</descriptorRef>
-
</descriptorRefs>
-
<archive>
-
<manifest>
-
<!--告诉运行的主类是哪个,注意根据自己的情况,下面的包名做相应的修改-->
-
<mainClass>com.lyz.storm.StormTopologyDriver
</mainClass>
-
</manifest>
-
</archive>
-
</configuration>
-
<executions>
-
<execution>
-
<id>make-assembly
</id>
-
<phase>package
</phase>
-
<goals>
-
<goal>single
</goal>
-
</goals>
-
</execution>
-
</executions>
-
</plugin>
-
<plugin>
-
<groupId>org.apache.maven.plugins
</groupId>
-
<artifactId>maven-compiler-plugin
</artifactId>
-
<configuration>
-
<source>1.8
</source>
-
<target>1.8
</target>
-
</configuration>
-
</plugin>
-
</plugins>
-
</build>
-
</project>
3、实现单词分割计数的MySplitBolt类
-
package com.lyz.storm.bolt;
-
-
import org.apache.storm.topology.BasicOutputCollector;
-
import org.apache.storm.topology.OutputFieldsDeclarer;
-
import org.apache.storm.topology.base.BaseBasicBolt;
-
import org.apache.storm.tuple.Fields;
-
import org.apache.storm.tuple.Tuple;
-
import org.apache.storm.tuple.Values;
-
-
/
-
* 这个Bolt模拟从kafkaSpout接收数据,并把数据信息发送给MyWordCountAndPrintBolt的过程。
-
* @author liuyazhuang
-
-
/
-
public
class MySplitBolt extends BaseBasicBolt {
-
-
private
static
final
long serialVersionUID =
4482101012916443908L;
-
-
@Override
-
public void execute(Tuple input, BasicOutputCollector collector) {
-
//1、数据如何获取
-
//如果StormTopologyDriver中的spout配置的是MyLocalFileSpout,则用的是declareOutputFields中的juzi这个key
-
//byte[] juzi = (byte[]) input.getValueByField("juzi");
-
//2、这里用这个是因为StormTopologyDriver这个里面的spout用的是KafkaSpout,而KafkaSpout中的declareOutputFields返回的是bytes,所以下面用bytes,这个地方主要模拟的是从kafka中获取数据
-
byte[] juzi = (
byte[]) input.getValueByField(
"bytes");
-
//2、进行切割
-
String[] strings =
new String(juzi).split(
" ");
-
//3、发送数据
-
for (String word : strings) {
-
//Values对象帮我们生成一个list
-
collector.emit(
new Values(word,
1));
-
}
-
}
-
-
@Override
-
public void declareOutputFields(OutputFieldsDeclarer declarer) {
-
declarer.declare(
new Fields(
"word",
"num"));
-
}
-
}
4、实现入库操作的MyWordCountAndPrintBolt类
-
package com.lyz.storm.bolt;
-
-
import java.sql.Connection;
-
import java.sql.SQLException;
-
import java.sql.Statement;
-
import java.util.Map;
-
-
import org.apache.storm.task.TopologyContext;
-
import org.apache.storm.topology.BasicOutputCollector;
-
import org.apache.storm.topology.OutputFieldsDeclarer;
-
import org.apache.storm.topology.base.BaseBasicBolt;
-
import org.apache.storm.tuple.Tuple;
-
-
import com.lyz.storm.db.DBProvider;
-
-
-
/
-
* 用于统计分析,并且把统计分析的结果存储到mysql中。
-
* @author liuyazhuang
-
-
/
-
public
class MyWordCountAndPrintBolt extends BaseBasicBolt {
-
-
private
static
final
long serialVersionUID =
5564341843792874197L;
-
private DBProvider provider;
-
@Override
-
public void prepare(Map stormConf, TopologyContext context) {
-
//连接redis---代表可以连接任何事物
-
provider =
new DBProvider();
-
super.prepare(stormConf,context);
-
}
-
-
@Override
-
public void execute(Tuple input, BasicOutputCollector collector) {
-
String word = (String) input.getValueByField(
"word");
-
Integer num = (Integer) input.getValueByField(
"num");
-
Connection conn =
null;
-
Statement stmt =
null;
-
try {
-
conn = provider.getConnection();
-
stmt = conn.createStatement() ;
-
stmt.executeUpdate(
"INSERT INTO word_count (word, count) VALUES ('" + word +
"', " + num +
") ON DUPLICATE KEY UPDATE count = count + " + num) ;
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
finally{
-
if(stmt !=
null){
-
try {
-
stmt.close();
-
stmt =
null;
-
}
catch (Exception e2) {
-
e2.printStackTrace();
-
}
-
}
-
if(conn !=
null){
-
try {
-
conn.close();
-
conn =
null;
-
}
catch (Exception e2) {
-
e2.printStackTrace();
-
}
-
}
-
}
-
}
-
-
@Override
-
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
-
//todo 不需要定义输出的字段
-
}
-
}
5、实现操作数据库的DBProvider类
-
package com.lyz.storm.db;
-
-
import java.beans.PropertyVetoException;
-
import java.sql.Connection;
-
import java.sql.PreparedStatement;
-
import java.sql.ResultSet;
-
import java.sql.SQLException;
-
-
import com.mchange.v2.c3p0.ComboPooledDataSource;
-
-
/
-
* JDBC操作数据库
-
* @author liuyazhuang
-
-
/
-
public
class DBProvider {
-
-
private
static ComboPooledDataSource source ;
-
private
static
final String DB_DRIVER =
"com.mysql.jdbc.Driver";
-
private
static
final String DB_URL =
"jdbc:mysql://127.0.0.1:3306/sharding_0?useUnicode=true&characterEncoding=UTF-8&useOldAliasMetadataBehavior=true";
-
private
static
final String USER =
"root";
-
private
static
final String PASSWORD =
"root";
-
private
static Connection connection;
-
-
static{
-
try {
-
source =
new ComboPooledDataSource();
-
source.setDriverClass(DB_DRIVER);
-
source.setJdbcUrl(DB_URL);
-
source.setUser(USER);
-
source.setPassword(PASSWORD);
-
source.setInitialPoolSize(
10);
-
source.setMaxPoolSize(
20);
-
source.setMinPoolSize(
5);
-
source.setAcquireIncrement(
1);
-
source.setMaxIdleTime(
3);
-
source.setMaxStatements(
3000);
-
source.setCheckoutTimeout(
2000);
-
}
catch (PropertyVetoException e) {
-
e.printStackTrace();
-
}
-
}
-
-
/
-
* 获取数据库连接
-
-
@return 数据库连接
-
/
-
public Connection getConnection() throws SQLException {
-
connection = source.getConnection();
-
return connection;
-
}
-
-
-
//关闭操作
-
public static void closeConnection(Connection con){
-
if(con!=
null){
-
try {
-
con.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
-
public static void closeResultSet(ResultSet rs){
-
if(rs!=
null){
-
try {
-
rs.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
-
public static void closePreparedStatement(PreparedStatement ps){
-
if(ps!=
null){
-
try {
-
ps.close();
-
}
catch (SQLException e) {
-
e.printStackTrace();
-
}
-
}
-
}
-
}
6、实现程序的入口类StormTopologyDriver
-
package com.lyz.storm;
-
-
import org.apache.storm.Config;
-
import org.apache.storm.LocalCluster;
-
import org.apache.storm.StormSubmitter;
-
import org.apache.storm.generated.StormTopology;
-
import org.apache.storm.kafka.KafkaSpout;
-
import org.apache.storm.kafka.SpoutConfig;
-
import org.apache.storm.kafka.ZkHosts;
-
import org.apache.storm.topology.TopologyBuilder;
-
-
import com.lyz.storm.bolt.MySplitBolt;
-
import com.lyz.storm.bolt.MyWordCountAndPrintBolt;
-
-
/*
-
* 这个Driver使Kafka、strom、mysql进行串联起来。
-
-
这个代码执行前需要创建kafka的topic,创建代码如下:
-
* [root@liuyazhuang kafka]# bin/kafka-topics.sh --create --zookeeper liuyazhuang1:2181 --replication-factor 1 -partitions 3 --topic wordCount
-
-
接着还要向kafka中传递数据,打开一个shell的producer来模拟生产数据
-
* [root@liuyazhuang kafka]# bin/kafka-console-producer.sh --broker-list liuyazhuang:9092 --topic wordCount
-
* 接着输入数据
-
-
@author liuyazhuang
-
*/
-
public
class StormTopologyDriver {
-
-
public static void main(String[] args) throws Exception {
-
//1、准备任务信息
-
TopologyBuilder topologyBuilder =
new TopologyBuilder();
-
SpoutConfig spoutConfig =
new SpoutConfig(
new ZkHosts(
"192.168.209.121:2181"),
"wordCount",
"/wordCount",
"wordCount");
-
topologyBuilder.setSpout(
"KafkaSpout",
new KafkaSpout(spoutConfig),
2);
-
topologyBuilder.setBolt(
"bolt1",
new MySplitBolt(),
4).shuffleGrouping(
"KafkaSpout");
-
topologyBuilder.setBolt(
"bolt2",
new MyWordCountAndPrintBolt(),
2).shuffleGrouping(
"bolt1");
-
-
//2、任务提交
-
Config config =
new Config();
-
config.setNumWorkers(
2);
-
StormTopology stormTopology = topologyBuilder.createTopology();
-
-
if(args !=
null && args.length >
0){
-
StormSubmitter.submitTopology(args[
0], config, topologyBuilder.createTopology());
-
}
else{
-
//本地模式
-
LocalCluster localCluster =
new LocalCluster();
-
localCluster.submitTopology(
"wordcount",config,stormTopology);
-
}
-
-
}
-
}
7、创建数据库
执行如下脚本创建数据库
-
create
database sharding_0;
-
CREATE
TABLE
word_count (
-
id
int(
11)
NOT
NULL AUTO_INCREMENT,
-
word
varchar(
255)
DEFAULT
'',
-
count
int(
11)
DEFAULT
NULL,
-
PRIMARY
KEY (
id),
-
UNIQUE
KEY
word (
word)
USING BTREE
-
)
ENGINE=
InnoDB AUTO_INCREMENT=
233
DEFAULT
CHARSET=utf8;
至此,我们的程序案例编写完成。
四、温馨提示
大家可以到链接http://download.csdn.net/download/l1028386804/10269075下载完整的Storm+Kafka+Flume+Zookeeper+MySQL实现数据实时分析(程序案例篇)源代码