Spark streaming
Spark streaming是一种数据传输技术,它把客户机收到的数据变成一个稳定的连续的流,源源不断的送出。
流式计算框架:
Apache storm
spark streaming
Apache samza

数据来源 实时处理 存储到

接下来实现一个spark streaming小demo
从Scoket 实时读取数据,进行实时处理
1:先安装nc
#wget http://vault.centos.org/6.6/os/i386/Packages/nc-1.84-22.el6.i686.rpm
#rpm -ivh nc-1.84-22.el6.i686.rpm
2:运行nc ,端口为9999
nc -lk 9999
3:运行spark streaming小案例
./bin/run-example streaming.NetworkWordCount lhq 9999
Spark streaming 的word count代码

Spark streaming 编程
两种创建方式:第一种是自己new sparkconf()编程。第二种是在 spark shell 编写spark streaming程序
==============读取hdfs数据,实现wordcount=
第一步打开hdfs相关进程
第二步打开spark进程
第三步运行命令 bin/spark-shell --master local[2]
第四部将下面框框代码运行在spark-shell命令行
第五步在另外一个界面将数据上传到代码中相应的位置
hadoop fs -put /usr/local/test/streaming1.txt /streaming/1
第六步:数据上传完成之后,就可以去刚刚那个界面看结果了
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
val lines = ssc.textFileStream(“hdfs://lhq:9000/streaming/”)
val words = lines.flatMap(.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey( + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
==如何在spark-shell中执行某个scala代码=
第一步:在spark目录下(任意目录)创建文件:touch HDFSWordCount.scala
第二步:将上面框框中的 代码粘贴到一个文件中HDFSWordCount.scala
第三步:保证hdfs,spark 相关进程都开
第四部:在spark-shell命令行中执行下面代码
:load /usr/local/spark/HDFSWordCount.scala
第五步:在另外一个界面将数据上传到代码中处理数据的位置:
hadoop fs -put /usr/local/test/streaming1.txt /streaming/1
第六步:在回到刚刚的界面数据已经处理
===============如何将streaming处理的数据存储=
代码:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
val lines = ssc.textFileStream(“hdfs://lhq:9000/streaming/”)
val words = lines.flatMap(.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey( + _)
wordCounts.saveAsTextFiles(“hdfs://lhq:9000/streaming/output”)
ssc.start()
ssc.awaitTermination()
执行步骤按照 上面两种办法都可以
Spark Streaming结合flume=
有两种结合方法:这一种是flume将数据推向streaming
代码:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume._
val ssc = new StreamingContext(sc, Seconds(5))
val stream=FlumeUtils.createStream(ssc, “lhq”, 9999, StorageLevel.MEMORY_ONLY_SER_2)
stream.count().map(cnt => “Received " + cnt + " flume events.” ).print()
ssc.start()
ssc.awaitTermination()
flume脚本:
在flume/conf/flume-spark-push.sh
#define agent
a2.sources = r2
a2.channels = c2
a2.sinks = k2
#define sources
a2.sources.r2.type = exec
a2.sources.r2.command = tail -f /usr/local/test/wctotal.log
a2.sources.r2.shell = /bin/bash -c
#define channels
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
#define sink
a2.sinks.k2.type = avro
a2.sinks.k2.hostname = lhq
a2.sinks.k2.port = 9999
#bind the sources and sinks to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
创建flume读取得原文件/usr/local/test/wctotal.log
1:flume和streaming集成需要一个外界下载的jar包:
https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume_2.11/1.4.1
2.11是scala版本,1.4.1是spark版本(可以根据自己的情况下载)
将这个jar包上传到/usr/local/flume-streaming-jars文件夹中
在flume家目录中,将两个jar拷贝到这个文件夹中

3:Spark目录下执行命令
spark-shell --jars
/usr/local/flume-streaming-jars/spark-streaming-flume_2.11-1.4.1.jar,/usr/local/flume-streaming-jars/flume-avro-source-1.5.2.jar,/usr/local/flume-streaming-jars/flume-ng-sdk-1.5.2.jar
4:将上面的代码在spark-shell命令行中执行
5:同时在另外一个页面:运行flume
bin/flume-ng agent -c conf -n a2 -f conf/flume-spark-push.sh -Dflume.root.logger=DEBUG,console
6:向wctotal源文件中添加数据,看看streaming的结果

结果:会变成1 flume events或者2,3
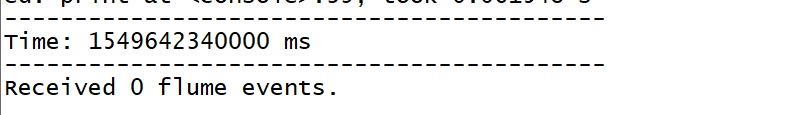
=====kafka结合streaming1=
Kafka:
启动zokeeper,启动kafka
前端启动:
bin/kafka-server-start.sh config/server.properties
后台启动:
nohup bin/kafka-server-start.sh config/server.properties &
创建topic
bin/kafka-topics.sh --create --zookeeper lhq:2181 --replication-factor 1 --partitions 1 --topic test
查看已有的topic
bin/kafka-topics.sh --list --zookeeper lhq:2181
生产数据:
bin/kafka-console-producer.sh --broker-list lhq:9092 --topic test
消费数据:
bin/kafka-console-consumer.sh -zookeeper lhq:2181 --topic test --from-beginning
在生产者界面输入:信息,消费者就会出现相关信息
代码:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
import java.util.HashMap
import org.apache.kafka.clients.producer.{ProducerConfig, KafkaProducer, ProducerRecord}
val ssc = new StreamingContext(sc, Seconds(5))
val topicMap=Map(“test”->1)
val lines = KafkaUtils.createStream(ssc, “lhq:2181”, “testWordCountGroup”, topicMap).map(.2)
val words = lines.flatMap(.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(+_)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
下载jar包:
https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka_2.10/1.4.1
上传到/usr/local/kafka-streaming-jars
进入kafka的libs目录下
cp kafka_2.10-0.8.2.0.jar kafka-clients-0.8.2.0.jar zkclient-0.3.jar metrics-core-2.2.0.jar /usr/local/kafka-streaming-jars/
spark-shell --jars
/usr/local/kafka-streaming-jars/spark-streaming-kafka_2.10-1.4.1.jar,/usr/local/kafka-streaming-jars/kafka_2.10-0.8.2.0.jar,/usr/local/kafka-streaming-jars/kafka-clients-0.8.2.0.jar,/usr/local/kafka-streaming-jars/zkclient-0.3.jar,/usr/local/kafka-streaming-jars/metrics-core-2.2.0.jar
再将上面代码在spark-shell中运行
下一步到生产者界面输入信息:hadoop hadoop spark回车
在spark-shell界面会看到
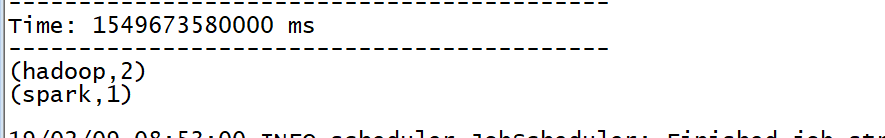
这就是集成成功
=====kafka结合streaming2-direct=
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
import kafka.serializer.StringDecoder
val ssc = new StreamingContext(sc, Seconds(5))
val kafkaParams = Map[String, String](“metadata.broker.list” -> “lhq:9092”)
val topicsSet=Set(“test”)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val lines = messages.map(.2)
val words = lines.flatMap(.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey( + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
创建文件
touch kafka-streaming-driectstream.scala
将代码帖进去
运行spark
spark-shell --jars
/usr/local/kafka-streaming-jars/spark-streaming-kafka_2.10-1.4.1.jar,/usr/local/kafka-streaming-jars/kafka_2.10-0.8.2.0.jar,/usr/local/kafka-streaming-jars/kafka-clients-0.8.2.0.jar,/usr/local/kafka-streaming-jars/zkclient-0.3.jar,/usr/local/kafka-streaming-jars/metrics-core-2.2.0.jar
Scala>:load /usr/local/spark/kafka-streaming-driectstream.scala
此时报错
:31: error: object serializer is not a member of package org.apache.spark.streaming.kafka
import kafka.serializer.StringDecoder