其实吧,本来这次爬虫作业是想做其他网页的……
为什么没做呢?直接上图吧……

……这个网页不让扒!不让扒!不让扒!也可能是我没找对方法吧……无妨,换一个网页继续吧
于是我就把目光投向了现在唯一打开的网页:咱们的班级
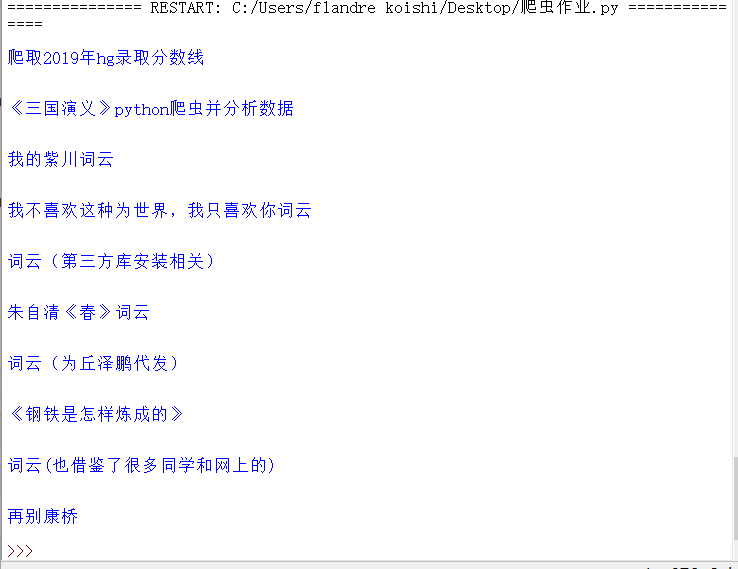
那就把咱们班级第一页的标题都爬下来吧。
但最开始,我的代码选择了借鉴同学的码。结果,是这样的……

这我就真是奇了怪了,于是,我选择再研究一番,发现
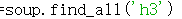
这个东西(现在是已经修改过的了)里的参数应该是这个问题的关键
做个爬虫,连源码都不看,这像话么?于是,利用了高效的资源(指百度)成功找到如何爬出源码,如图所示:

有一说一结果而言确实好用,效果如图所示:

然后,找到标题所在处,比如这个:
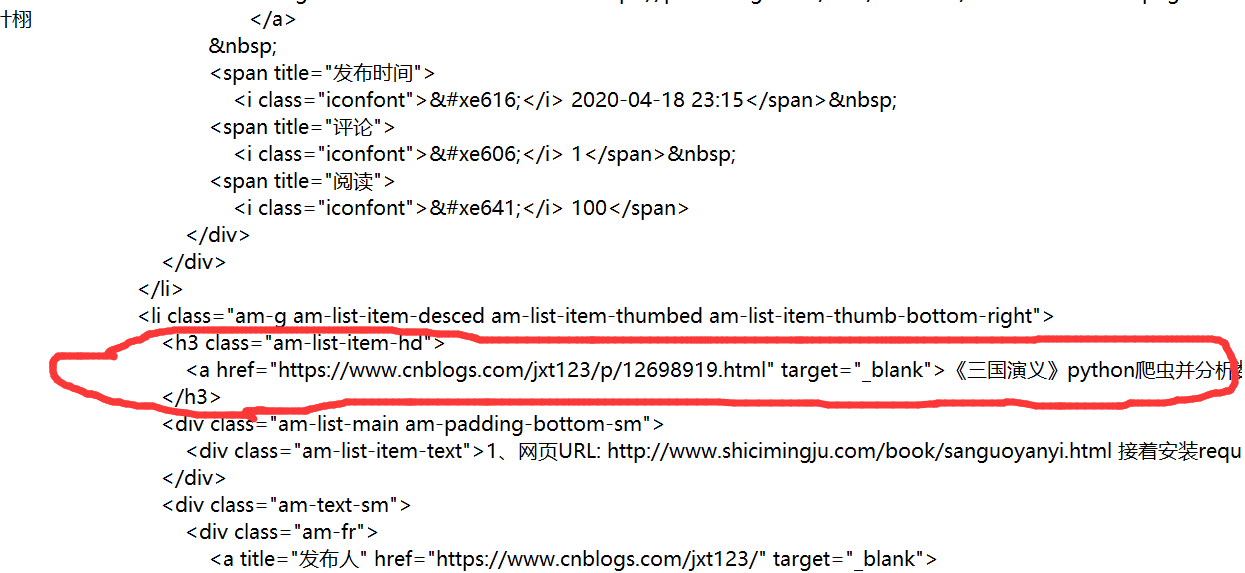
发现是在<h3></h3>里
那还等啥?填参数啊!
源代码如下:
import pandas as pd
import requests as rq
from bs4 import BeautifulSoup
ur1="https://edu.cnblogs.com/campus/academy/2020python?page=2"
r=rq.get(ur1)
try:
r.raise_for_status()
r.encoding=r.apparent_encoding
message=r.text
except:
print('ERROR')
soup=BeautifulSoup(message,'html.parser')
index=soup.find_all('h3')
for i in index:
print(i.text)
效果如下: