Mancher算法解析
本文参考
https://blog.csdn.net/qq_32354501/article/details/80084325?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
https://blog.csdn.net/u014771464/article/details/79120964
Manacher算法是一种用来解决回文字符串的算法,将最原始的方法的时间复杂度O(n3)转变为O(n),接下来将给出两种回文串的求解方法
最原始的方法
直接上代码
public static void main(String[] args)
{
String str = "sdffttrrgfddfh";
String result1=longestPalindrome1(str);//暴力破解算法
System.out.println(result1);
}
public static String longestPalindrome1(String s)
{
if(s.length()<=1)
return s;
for(int i=s.length();i>0;i--)
{
for(int j=0;j<s.length()-i;j++)
{
String sub=s.substring(j,i+j);
int count=0;//匹配个数
for(int k=0;k<sub.length()/2;k++)
{
if(sub.charAt(k)==sub.charAt(sub.length()-k-1))
count++;
}
if(count==sub.length()/2)
return sub;
}
}
return null;
}
采取使用多重循环的方式将子串进行回文判断,当匹配的回文数即count=子串的长度的一半时,return 当前的子串;由于从最长开始,长度慢慢减少,找出的回文串即为最长的回文子串
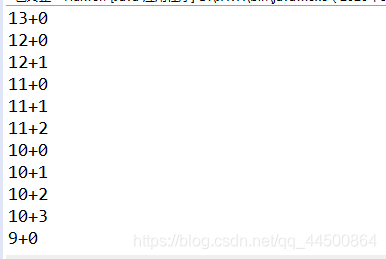
其中代码:String sub=s.substring(j,i+j);的 i 和 j 演变如下图(只显示一部分用于理解代码):
Manacher算法
Manacher算法是一种从中心向两边扩张的算法,依靠辅助数组找到最大的回文半径,以此来查找最长的回文子串
直接上代码
public static void main(String[]args)
{
String str="sdffttrrgfddfh";
System.out.println(manacher(str));
}
public static String manacher(String str)
{
String sub="$#";
for(int i=0;i<str.length();i++)
{
sub+=str.charAt(i);
sub+="#";
}
sub+="!";
int id=0,sub_side=0,maxlen=0,maxindex=0;
/*id代表最大回文子串的中心位置
sub_side代表以id为中心的回文子串的边界
maxlen代表最大回文子串的长度,maxindex代表相应的索引位置
*/
int[]p=new int[sub.length()];//P[i]代表以i为中心的字符串的回文半径
for(int i=0;i<sub.length();i++)
{
p[i]=sub_side>i?Math.min(p[2*id-i],sub_side-i):1;
while (((i-p[i])>=0)&&((i+p[i])<sub.length()-1)&&(sub.charAt(i+p[i])==sub.charAt(i-p[i])))
++p[i];
if(sub_side<i)
{
sub_side=i+p[i];
id=i;
}
if(maxlen<p[i])
{
maxlen=p[i];
maxindex=i;
}
}
return str.substring(((maxindex-maxlen)/2),((maxindex-maxlen)/2)+maxlen-1);
}
由于字符串长度有奇偶变化,引入’#‘添加到每个字符中间,再加上’$‘和’!'用来当做边界防止越界
例如:abaaba字符,Manacher第一步将其变为$#a#b#a#a#b#a#! 进行预处理
这里需要介绍一下回文半径,回文半径即回文中心到回文边界的距离,放到代码中就是 id 到 sub_side的距离
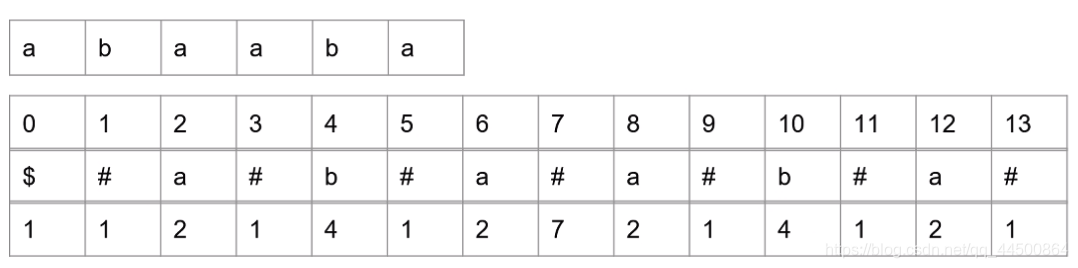 p数组为最下面一行,代表算上#符号的回文半径,例如第2个位置的回文半径即为第三个位置的#到回文中心即第二个位置的距离
p数组为最下面一行,代表算上#符号的回文半径,例如第2个位置的回文半径即为第三个位置的#到回文中心即第二个位置的距离
不难发现 p[i]-1即为原来字符串中回文串的半径
接下来介绍几种情况
第一种情况

其中mx代表以 id 为中心的回文半径的右边界,例如
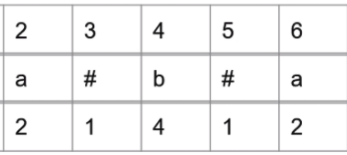
右边界是第6个字符 a,回文中心为第4个字符 b,i为第i个字符
当 mx - i > P[j] 的时候,以p[j]为中心的回文子串包含在以第 id 个字符为中心的回文子串中,由于 i 和 j 对称,以第 i 个字符为中心的回文子串
必然包含在以第 id 个字符为中心的回文子串中,所以必有 P[i] = P[j]。
第二种情况
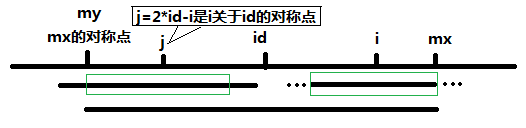
当mx - i <= p[j]时,以p[ j ]为中心的回文子串的回文半径超过了以第 id 个字符为中心的回文子串的左边界my(根据对称),根据对称性,以
第 p[ i ]个字符为中心的回文子串必将超出边界范围,所以必须进行扩展即重新选取回文中心,对应代码中的这一段
if(sub_side<i)
{
sub_side=i+p[i];//sub_side相当于mx
id=i;
}
再使用暴力匹配的方法。
第三种情况
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去暴力匹配了。
