1. Hadoop简介
- 基于Java开放的,具有很好的跨平台特性
- Linux平台
- 核心:
分布式文件系统HDFS(Hadoop Distributed File System)顺序读写
分布式并行编程模型MapReduce - 其他重要组件:
Hive:Hadoop上的数据仓库(架构在MapReduce之上),可以支持SQL语句
HBase:Hadoop上的非关系型的分布式数据库,随机读写——面向列的存储(实时应用)
Zookeeper(管理员):提供分布式协调一致性服务
Spark:类似于Hadoop MapReduce的通用并行框架
Pig(轻量级脚本语言):进行编写代码,简化MapReduce的操作
Oozie:作业流调度系统
Flume:日志收集工具
Sqoop :完成数据导入导出,可以将关系型数据库中的数据直接导入平台上/导出
Ambari:安装部署工具
2. Hadoop集群节点介绍
- NameNode(名称节点):负责协调集群中的数据存储
- DataNode:存储被拆分的数据块
- SecondaryNameNode(第二名称节点):帮助NameNode收集文件系统运行的状态信息
- JobTracker:协调数据计算任务
- TaskTracker:负责执行由JobTracker指派的任务
(1)HDFS中的NameNode(名称节点)+DataNode(若干个)
取数据时,首先向NameNode获得要访问的数据到底放在了哪些DataNode中,再到具体地址上个的数据节点上取数据。
(2)MapReduce两大核心组件:JobTracker(作业管家——管理)+TaskTracker(部署在每个小的机器上(各个节点上),负责分配给自己的那一小部分作业)。
(3)SeconaryNameNode是HDFS中的组件——NameNode的冷备份(出了故障需要一定时间才能替换上去)。
TaskTracker和DataNode可以在同一个节点上(大集群会分开放),且大部分节点都是这两个。
3 分布式文件系统HDFS
1)概述
- 用于解决分布式存储问题
- 把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群
- 一个文件被分成多个块,以块作为存储单位,一个块一般大于普通文件系统(一般默认为64MB)
- 集群由多个机架组成(里面很多台机器(节点),机架和机架通过光纤高速交换机进行连接)
- 采用了主从(Master/Slave)结构模型
- 采用的均是TCP/IP的通信协议
- 防止机器故障,每个数据均会被冗余保存(一般3份)
- 缺点:不适合低时延访问,实时性不高;而HBase的实时性强
2)名称节点以及数据节点
物理结构由计算机集群中的多个节点构成的: “主节点”(Master Node)/ “名称结点”(NameNode)和“从节点”(Slave Node)/“数据节点”(DataNode)
名称节点:
负责管理分布式文件系统的命名空间(Namespace),HDFS的命名空间包含目录、文件和块。保存了两个核心的数据结构,即FsImage和EditLog。记录了每个文件中各个块所在的数据节点的位置信息。
- FsImage:用于保存系统文件数
包含文件系统中所有目录和文件inode的序列化形式。
没有记录哪些节点上存储了块数据,而是由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。 - 操作日志文件EditLog
记录了所有针对文件的创建、删除、重命名等操作。
数据节点:
负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
4 MapReduce
1)概述
- 是一种分布式并行编程框架(多台计算机同行在运行编程)
- 是Hadoop的两大核心技术之一:主要用于分布式数据处理
- 采用非共享式架构,可扩展性较好,容错率也较好,一个节点出错并不会影响整个集群
- 廉价
- 非实时密集型数据处理
- MapReduce理念:
计算向数据靠拢,而不是数据向计算靠拢
数据是分块存储,要计算某块数据时,不是讲数据拿到节点上计算,而应该是找到离这块数据最近的节点去处理这块数据,可以减少网络中数据传输开销
2)模型简介
- 屏蔽了整个分布式程序运行的相关底层细节
- MapReduce整个复杂的计算过程高度的抽象成两个函数:Map函数和Reduce函数(一个汇总求和的过程)
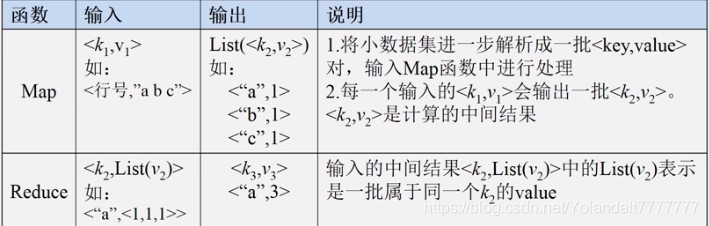
- MapReduce的策略:
处理大规模数据——将强大的数据集切成很多独立的小分片(Split),然后为每个分片单独启动一个map任务,最终多个map任务并行在多个机器上处理。
3 架构以及体系结构
Master/slave架构
用Java开发,但是支持用不同语言去编写。
- 一个Master服务器:有作业跟踪器JobTracker——负责整个作业的调度的处理以及失败和恢复。
- 若干个slave服务器:有负责具体任务执行的组件TaskTracker——负责接收JobTracker给它发的作业处理指令,完成具体任务处理。
体系结构
- Client(客户端):
可以提交用户编写的应用程序将应用程序交到JobTracker端
可以通过它提供的一些接口去查看提交作业的运行状态(一个作业会包含多个任务(Task)) - JobTracker(作业跟踪器)(管家)
a) 资源的监控和作业的调度;监控底层其他TaskTracker以及当前运行的Jobde 健康状况;
b) 还会跟踪任务的执行进度和资源使用量,会将这些信息发送给任务调度器(Task Scheduler) - Task Scheduler
负责具体任务的调度,即决定将哪个任务分发给哪个TaskTracker去执行;是一个可插拔模块,可以自己编写 - TaskTracker(任务调度器)
a) 执行具体相关任务,一般接受JobTracker发送的命令
b) 会将自己的资源使用情况以及任务运行进度通过心跳(heartbeat)的方式发送给JobTracker,
c) TaskTracker使用槽(slot)的概念去衡量自己的资源使用情况,将自己全部资源等分给Map和Reduce,且两种类型的slot不通用 - Task(任务)
a) Map任务——执行Map函数
b) Reduce任务——执行Reduce函数
c) 同一台机器上可以同时运行这两个任务
