一 、Hadoop简介(转自百度百科)
Hadoop是Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统
(Hadoop Distributed File System),简称HDFS。HDFS有高容错性
的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二 、Hadoop项目结构
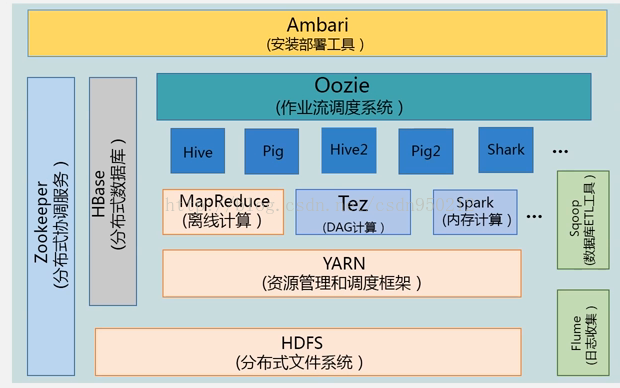
HDFS:负责整个分布式文件的存储。
YARN:负责资源的管理和调度。
MapReduce:离线批处理,无法实现实时计算。
Tez:分析优化MapReduce作业,形成有向无环图。
Spark:逻辑与MapReduce类似,与MapReduce的区别是:Spark是基于内存的计算,MapReduce是基于磁盘的计算。
Hive:批量数据处理,实现数据仓库的功能。
Pig:流数据处理,轻量级的脚本语言。
Oozie:作业流调度系统,工作流管理工具。
Zookeeper:提供分布式协调服务,做分布式锁、集群管理等。
HBase:分布式数据库,支持随机读写和实时应用。
Flume:一个高可靠的、高可用的分布式海量日志采集、聚合和传输的系统。
Sqoop:用于Hadoop与传统数据库之间进行数据传输。
Ambari:Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控。