本章内容:
1.Hadoop的发展历程
2.Hadoop生态系统的各个组件及其功能
3.Hadoop的安装和使用方法
4.Hadoop集群的部署和使用方法
1.Hadoop简介
Hadoop是Apache软件基金会旗下开源软件
Hadoop可以支持多种编程语言:C、C++、Java、Python
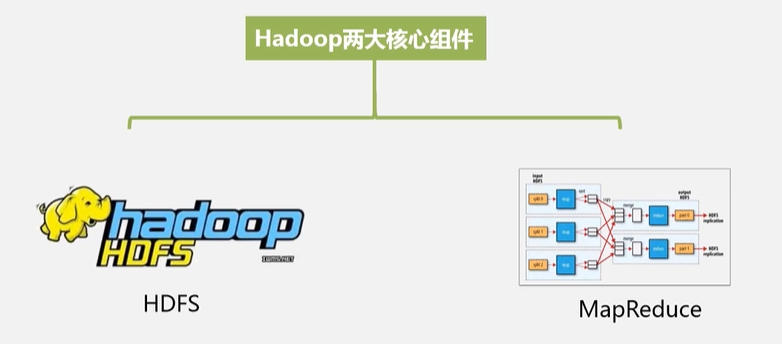
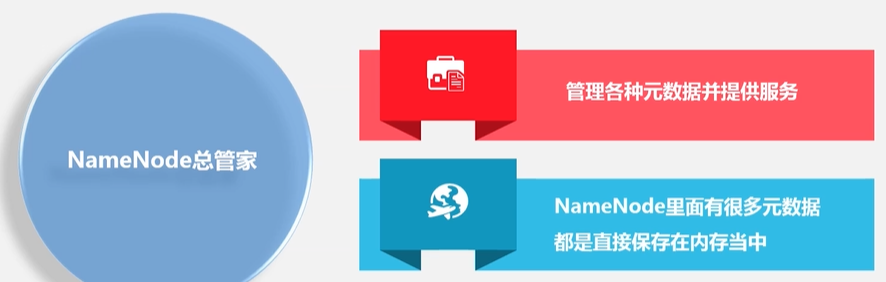
Hadoop两大核心—HDFS+MapReduce:
解决了两大问题:HDFS如何实现海量数据的存储(集群分布式存储),MapReduce如何实现海量数据的处理(集群分布处理)
2003年,谷歌发布了分布式文件系统GFS(Google File System)。HDFS是GFS的开源实现
2004年,谷歌发布了分布式并行编程框架MapReduce。

对1TB的数据进行排序,用时209秒
Hadoop的特性:
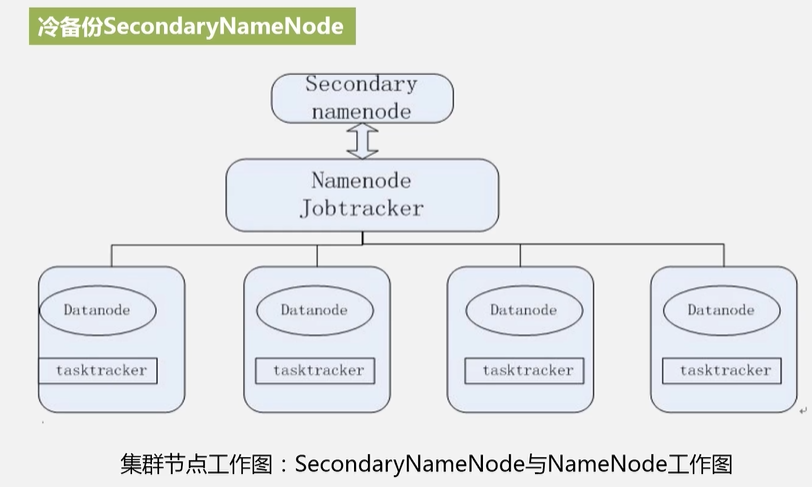
1.Hadoop具有很高的可靠性:多台机器构成集群,部分机器发生故障,剩余机器可以继续对外提供服务
2.Hadoop具有很高的效率:成百上千台机器一起计算
3.Hadoop具有很好的可扩展性:可以不断往集群中增加机器
4.Hadoop成本低:Hadoop可以采用普通PC机来构成一个集群
5.高性能计算(High Performance Computing 编写HPC)
Hadoop应用现状
Facebook公司采用Hadoop集群用于日志处理、推荐系统和数据仓库等方面
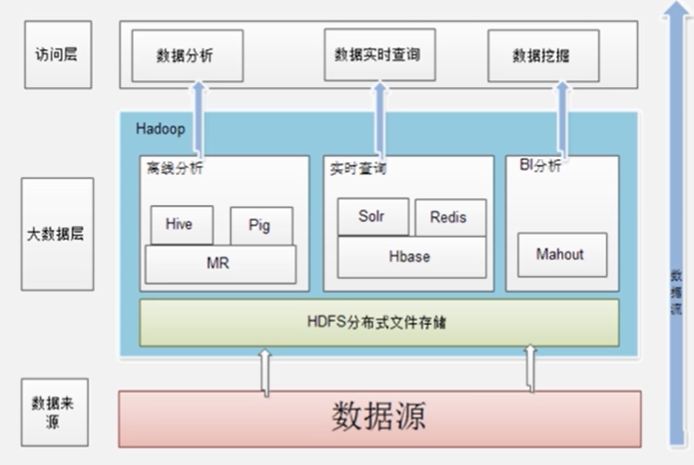
2.Hadoop不同的版本

Hadoop1.0两大核心:HDFS+MapReduce
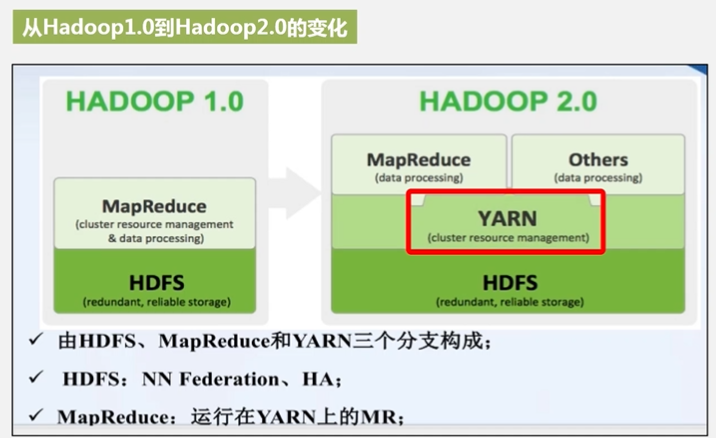
到2.0以后,MapReduce只做数据处理工作,不再做资源调度。MapReduce是架构在YARN资源调度之上的。
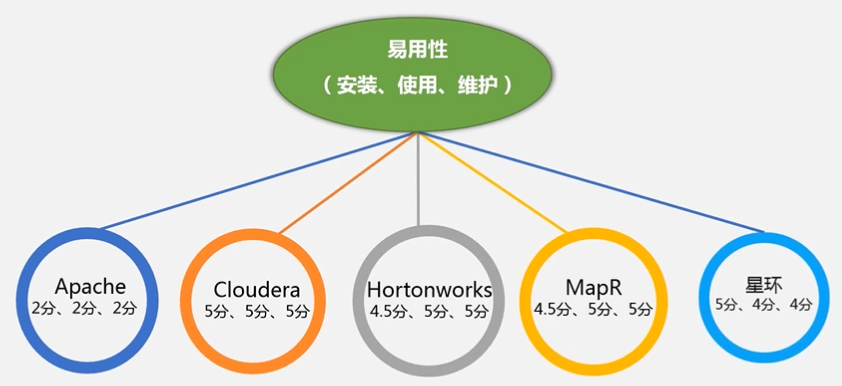
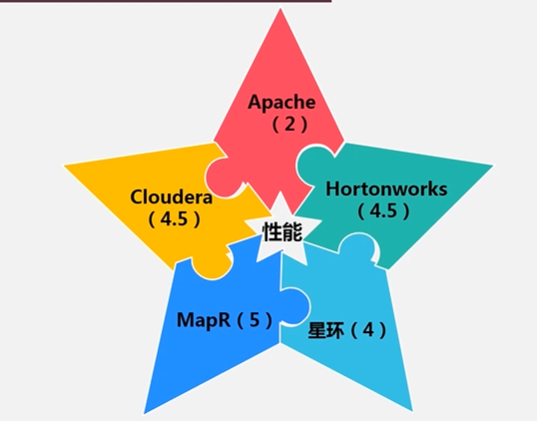
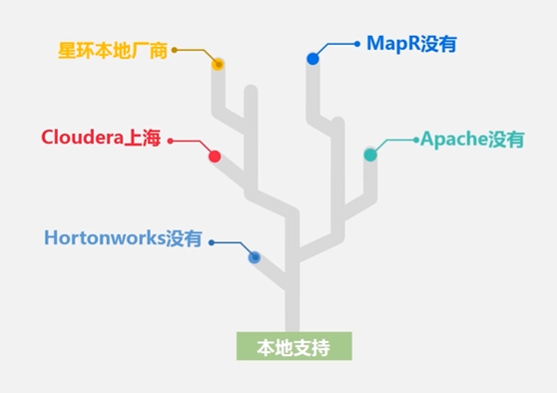
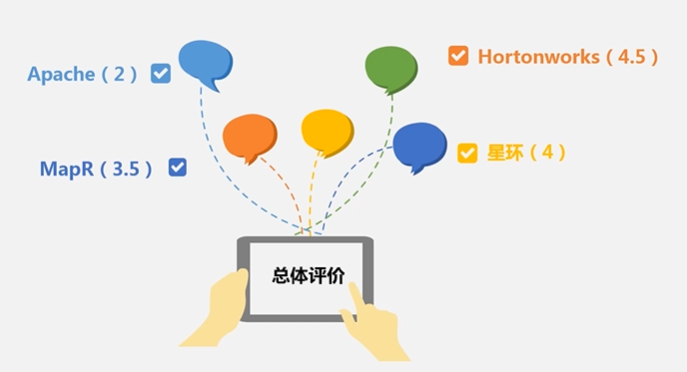
学生Apach、企业Hortonworks,星环
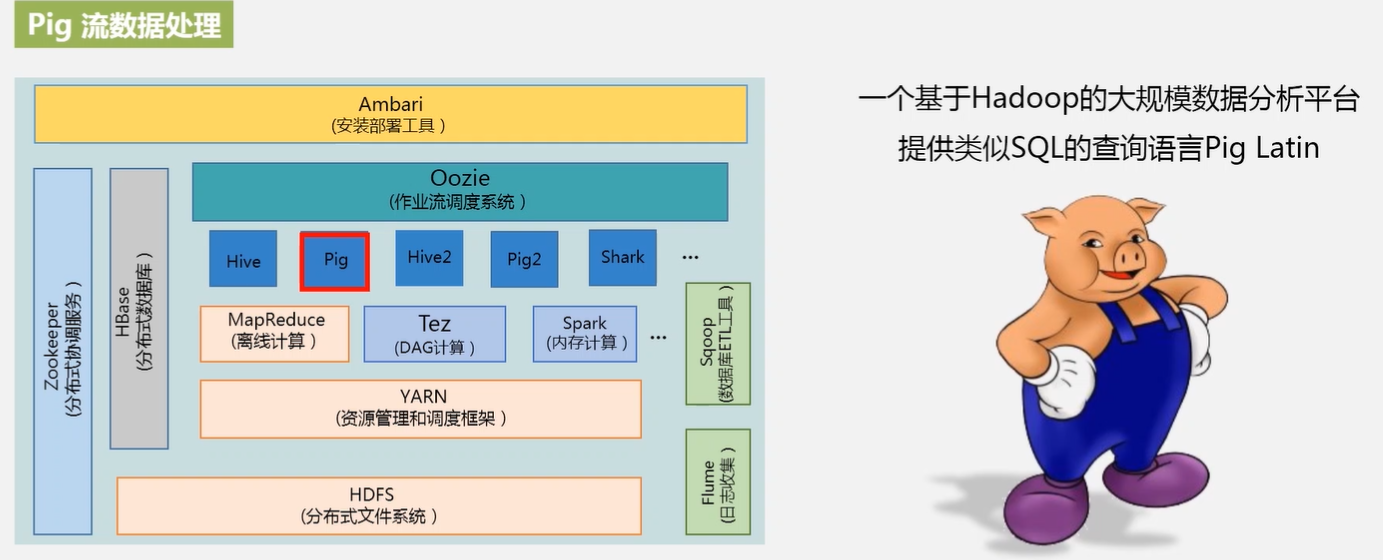
3.Hadoop项目结构
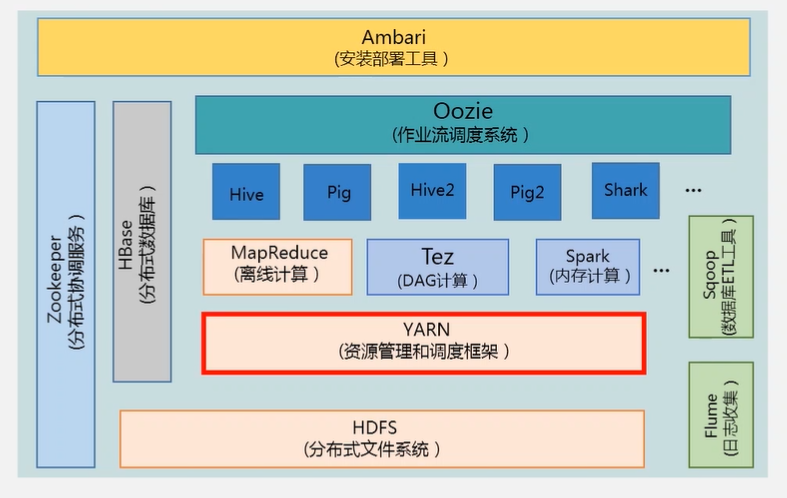
YARN负责对内存、CPU、资源、带宽资源进行调度
Spark与MapReduce的区别:
Spark是基于内存的;MapReduce是基于磁盘的
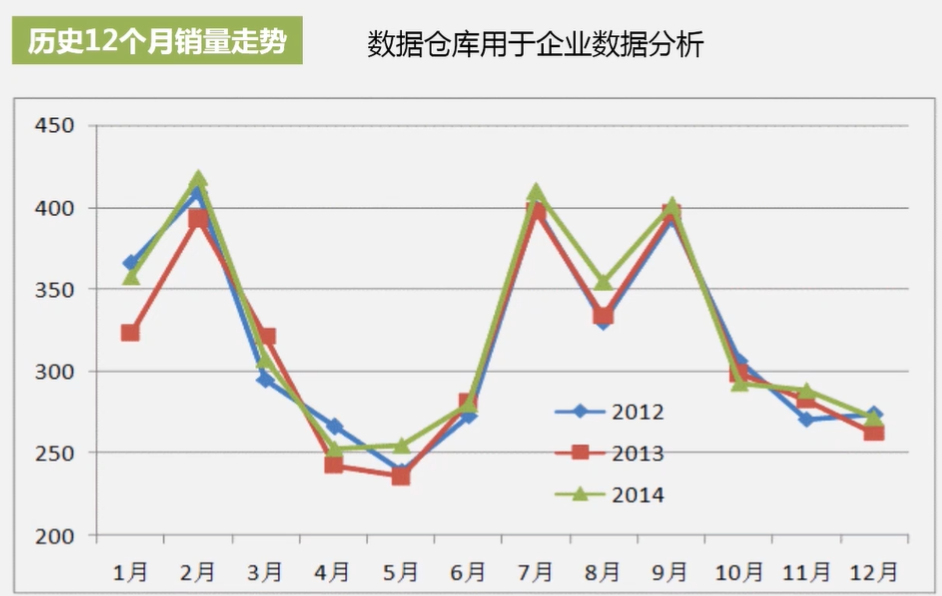
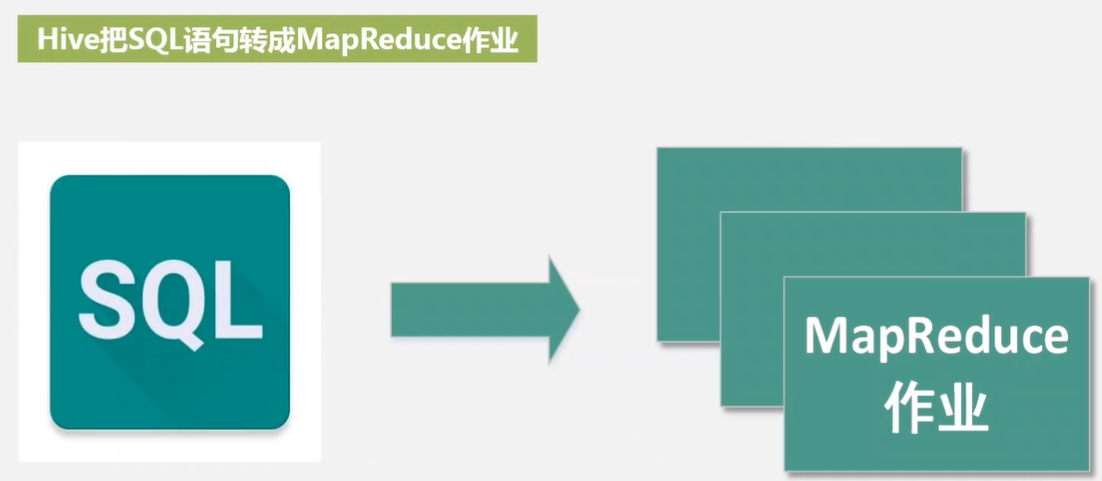
Hive是数据仓库方面的。可用于企业数据分析。

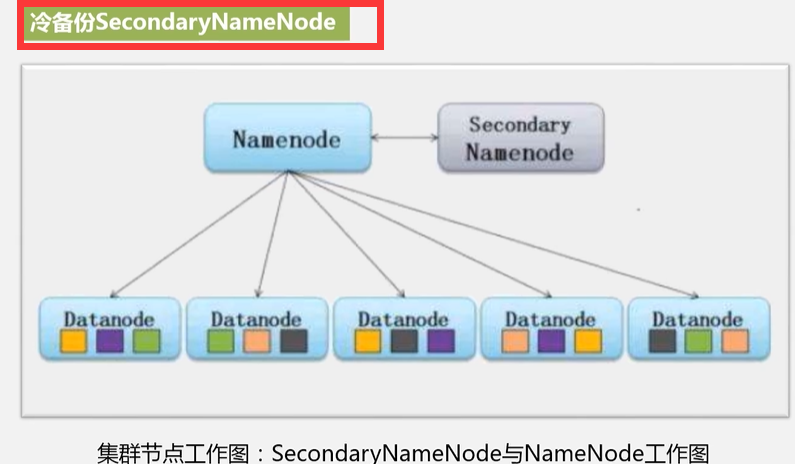
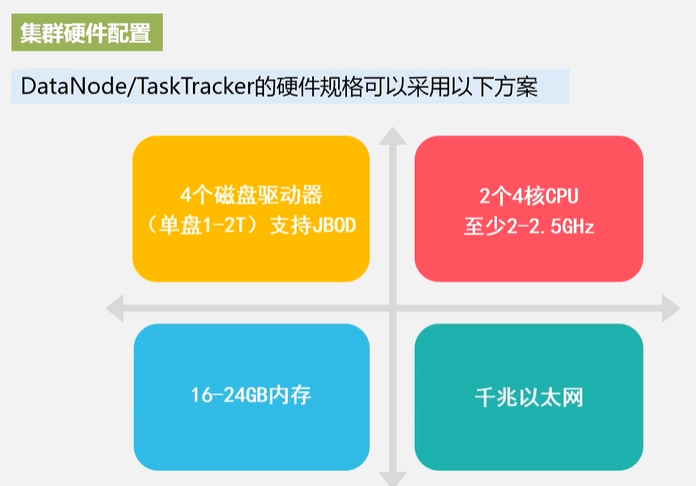
4.Hadoop集群的部署和使用





Hadoop不仅可以在本地使用也可以部署到云端