hadoop-2.6.0-cdh完全分布式集群的搭建
1 虚拟机配置
| 序号 | 操作系统 | CPU/core | 内存/GB | 硬盘/GB | IP地址 | 主机名 |
|---|---|---|---|---|---|---|
| 1 | Ubuntu | 2 | 3 | 20 | 192.168.0.122 | master |
| 2 | Ubuntu | 1 | 2 | 20 | 192.168.0.123 | slave1 |
| 3 | Ubuntu | 1 | 2 | 20 | 192.168.0.124 | slave2 |
2 集群网络配置
2.1 修改主机名
主节点名字为master,另外2个节点名字分别为slave1和slave2
root@ubuntu:~# vim /etc/hostname
master
2.2 添加映射
未了方便后续操作,3个节点都添加IP和主机名的映射
root@ubuntu:~# vim /etc/hosts
192.168.0.122 master
192.168.0.123 slave1
192.168.0.124 slave2
3 集群ssh免密登录配置
3.1 生成公钥和私钥
在3个节点上都生成ssh key
hadoop@master:ssh-keygen -t rsa
3.2 将公钥复制到远程机器中
在master上执行下面3行命令
hadoop@master:~$ ssh-copy-id -i ~/.ssh/id_rsa.pub master
hadoop@master:~$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
hadoop@master:~$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
3.3免密ssh登陆测试
hadoop@master:~$ ssh master
hadoop@master:~$ ssh slave1
hadoop@master:~$ ssh slave2
4 在主节点安装JDK和Hadoop
4.1 安装jdk
hadoop@master: tar -zxvf java.tar.gz -C ~/app //解压
//设置JVM环境变量
hadoop@master:echo 'export JAVA_HOME=/home/hadoop/app/java' >> ~/.bashrc
hadoop@master:echo 'PATH=${JAVA_HOME}/bin:$PATH' >> ~/.bashrc
hadoop@master:source .bashrc //刷新
4.2 安装hadoop
hadoop@master:tar -zxvf hadoop-2.6.0-cdh5.9.3.tar.gz -C ~/app
hadoop@master:mv app/hadoop-2.6.0-cdh5.9.3 ~/app/hadoop
#设置hadoop环境变量
hadoop@master:echo 'export HADOOP_HOME=/home/hadoop/app/hadoop' >> ~/.bashrc
hadoop@master:echo 'PATH=${HADOOP_HOME}/bin:$PATH' >> ~/.bashrc
hadoop@master:source ~/.bashrc //刷新
5 Hadoop集群主节点配置
5.1 配置环境变量
hadoop@ubuntu:~/app/hadoop/etc/hadoop$ vim hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}替换为
export JAVA_HOME= /home/hadoop/app/java
5.2 开放端口号和指定临时文件夹
hadoop@ubuntu:~/app/hadoop/etc/hadoop$ vim core-site.xml
添加:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
</configuration>
5.3 配置副本数和存储位置
//默认副本系数为3
hadoop@ubuntu:~/app/hadoop/etc/hadoop$ vim hdfs-site.xml
添加:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/tmp/dfs/data</value>
</property>
</configuration>
5.4 配置yarn
hadoop@master:~/app/hadoop/etc/hadoop$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
5.5 设置提交的 Yarn job 只运行在分布式模式
hadoop@master:~/app/hadoop/etc/hadoop$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.6 配置datanode运行位置
hadoop@master:~/app/hadoop/etc/hadoop$ vim slaves
将localhost替换为:
master
slave1
slave2
6 Hadoop集群从节点的配置
6.1 拷贝配置
将第4和5步配置拷贝到slave1和slave2上
hadoop@master:~$ scp -r /home/hadoop/app/ hadoop@slave1:~/
hadoop@master:~$ scp -r /home/hadoop/app/ hadoop@slave2:~/
hadoop@master:~$ scp /home/hadoop/.bashrc hadoop@slave1:~/.bashrc
hadoop@master:~$ scp /home/hadoop/.bashrc hadoop@slave2:~/.bashrc
6.2刷新slave1和slave2配置文件
hadoop@slave1:~$ source .bashrc
hadoop@slave1:~$ source .bashrc
6.4验证3个节点JDK和Hadoop是否按装成功
在3个节点分别查看是否能输出配置信息
hadoop@master: echo `java -version //输出java版本信息
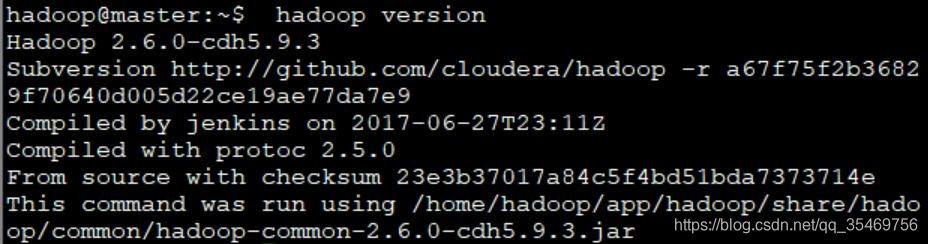
hadoop@master:hadoop version //输出hadoop版本信息

7 Hadoop集群的启停
7.1 初始化
首次启动时,只在master节点格式化文件系统。执行完后可以看到在~/app/tmp/ dfs/下面会自动生成一个叫name的文件夹
hadoop@master:~/app/hadoop/bin$ ./hdfs namenode -format
7.2 启动hadoop集群
hadoop@master:~/app/hadoop/sbin$ ./start-all.sh
7.3 验证集群是否启动成功
方法1:查看进程数
hadoop@master:~/app/hadoop/sbin$ jps:
在主节点上可以看到下面5个进程
2678 ResourceManager
2810 NodeManager
2350 DataNode
2191 NameNode
2543 SecondaryNameNode
从节点只有2个
1665 DataNode
1805 NodeManager
方法2:在浏览器访问console页面
访问hadoop页面:
http://192.168.0.122:50070
访问yarn页面:
http://192.168.0.122:8088/cluster
7.4停止hadoop集群
hadoop@master:~/app/hadoop/sbin$ ./stop-all.sh
8 提交MapeReduce Job
8.1 在HDFS上创建文件夹
hadoop@master:~/app/data$ hadoop fs -mkdir /data
8.2 创建数据源wordcont.txt
hadoop@ubuntu:~ /app/data$ vim wordcont.txt
添加:
hello hadoop
hello spark
8.3 将wordcond.txt提交到HDFS
hadoop@master:~/app/data$ hadoop fs -put wordcount.txt /data
8.4 查看是否添加成功
hadoop@master:~/app/data$ hadoop fs -ls -R /
8.5 运行MR程序
hadoop@master:~/app/hadoop/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.9.3.jar wordcount /data /result
其中 wordcount为程序的主类名, /data 输入目录, /result 输出目录,且输出目录不能存在,否则会报错
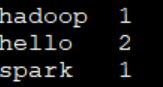
8.6 查看统计结果
hadoop@master:~/app/data$ hadoop fs -ls -R /result

hadoop@master:~/app/data$ hadoop fs -cat /result/part-r-00000
9 Hadoop shell指令小结
hadoop@master:~$ hadoop fs + 命令
常见命令:
-ls -R / 递归显示/下所有文件夹
-get /hello.txt 将hdfs的文件下载到本地
-put ~/data/hello.txt /input/wc 讲本地文件上传到hdfs
-cat /hello.txt 查看文本内容
-mkdir /text 创建文件夹
-rm /hello.txt 删除文件
-rm -R /text 删除文件夹
