VirtualBox+Centos7+(jdk1.7.0_71+Hadoop-2.6.0)/(jdk1.10+Hadoop-2.9.1)搭建完全分布式集群平台
本文有很多是自定义的,可以根据自己的实际情况和需求修改,尽量会用
红色标注出来,当然按照步骤,一步一步应该也能成功,不过最好还是要理解。
准备
- 使用到的软件相关版本
操作系统:centos7:文件超过4g放个链接,速度很给力清华镜像站
虚拟机:virtualbox:> 很常见,没有坑,就不放链接了
jdk:jdk1.7.0_71:百度云链接 密码:jyjg
Hadoop:hadoop-2.6.0:百度云链接 密码:cwuk
- 自定义配置
master节点主机名:hadoopmaster
slave节点主机名:hadoop0/hadoop1
master节点IP:192.168.1.200
slave节点IP:192.168.1.201/192.168.1.202
用户名:ziv(三个虚拟机的用户名都是这个)
一、 visualbox主机和虚拟机互ping
1.1、安装三个虚拟机互ping(一个master节点命名为hadoopmaster,两个slave节点命名为hadoop0和hadoop1)
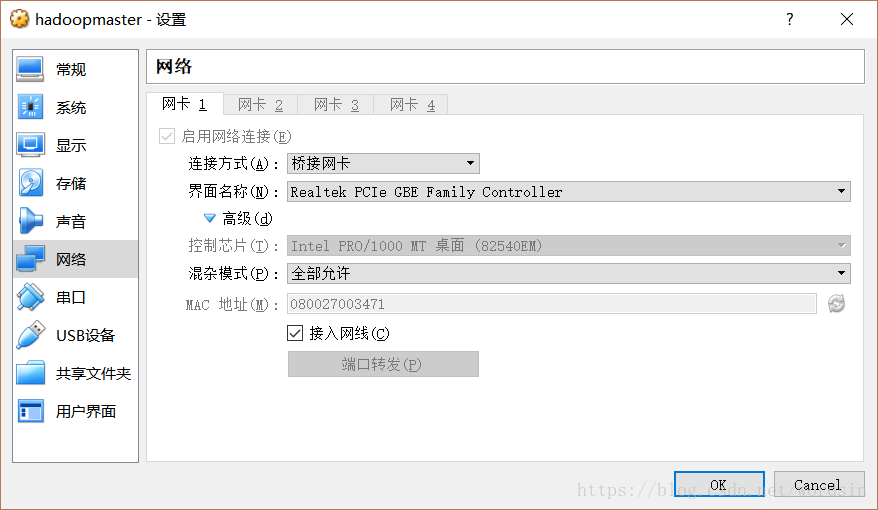
虚拟机设置:(所有节点)
- 桥接网卡
- Realtek PCIe GBE Family Controller
- 全部允许
【坑1】:联网
因为害怕电脑配置低,我安装的时候选择的最小安装,结果什么都没有,连ifconfig都木有啊。
用vi(-_-!!!因为只有vi)打开网络配置文件(文件名前面一部分是一样的,ifcfg-eth*)
vi /etc/sysconfig/network-scripts/ifcfg-eth0>把onboot=no改为onboot=yes
重启网络
service network restart
打开ip服务器配置文件,配置ip服务器(有可能已经配置过了,如果里面有了就不用加了)
vi /etc/resolv.conf
增加nameserver 8.8.8.8 或者114.114.114.114(前者是Google的,全球通用,后者是移动联通电信共用的,都是免费的)
重启网络
service network restart
然后就能联网了,,,
为了使用ifconfig
yum -y install net-tools
1.2、配置虚拟机的IP为静态IP,并分配IP(所有节点)
打开虚拟机的网络配置文件(就是刚才那个联网的文件)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
把下面的这几句放进去(有则改之,无则添加,尽量不要删东西,因为我也不懂)
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.1.200
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
分别是开机启动、静态分配ip、分配的静态ip、子网掩码、网关
这里的都是能自定义的,但是分配的ip要跟主机同网段,也就是前两个数要一样
我的master节点ip是192.168.1.200
两个slave的ip是192.168.1.201/202
重启网络服务
service network restart
这时候应该可以跟主机互ping了
也就意味着,可以用xshell登陆了,真的比虚拟机上快多了
ping192.168.110-c 3
这是我的主机ip,ping3次
二、安装Hadoop前
2.1、 防火墙相关(所有节点)
关闭防火墙可以提高hadoop的速度,而且端口使用也比较随意,虚拟机也无所谓安不安全-_-!!!
systemctl status firewalld.service//检查防火墙状态
systemctl stop firewalld.service//关闭防火墙
systemctl disable firewalld.service//取消防火墙自启动
2.2、安装jdk(所有节点)
将jdk文件解压到
/usr/java/文件夹内
修改/home/ziv/下的.bash_profile
vim /home/ziv/.bash_profile
尾部添加
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export PATH=$JAVA_HOME/bin:$PATH
使修改生效
source /home/ziv/.bash_profile
检测
java -version
【坑2】:jdk下载问题
linux里面的wget十分厉害,再加上虚拟机不方便传文件,我在下载jdk的时候选择了wget;然后解压的时候就尴尬了,tar -zxvf解压报错;
网上有很多乱七八糟的解决方法我也看不懂,—_—。 最后还是用Windows下载后传到虚拟机上的
顺便分享一个东西,很好很强大
yum install lrzsz
安装好以后可以直接从Windows里拖文件到xshell就能复制文件
【坑3】:jdk和hadoop版本问题
听说 jdk和hadoop的版本是一对一的,就跟vs和QT的关系一样,我也没试过太多,我用的是jdk1.7.0_71和hadoop2.6.0,已知同学有用jdk1.10和hadoop2.91安装成功的,可以试试。
2.3、修改主机名(所有节点)
vim /etc/hostname
分别修改为hadoopmaster/hadoop0/hadoop1
vim /etc/hosts
都添加上主机名的映射
192.168.1.200 hadoopmaster
192.168.1.201 hadoop0
192.168.1.202 hadoop1
重启
2.4、免密钥登陆(仅master节点)
- Master节点配置
a、生成密钥
ssh-keygen -t rsa//生成密钥
b、复制公钥文件到同目录下改名为authorized_keys
cp /home/ziv/.ssh/id_rsa.pub /home/ziv/.ssh/authorized_keys
c、复制公钥到slave节点
scp /home/ziv/.ssh/id_rsa.pubziv@hadoop0:~/
scp /home/ziv/.ssh/id_rsa.pubziv@hadoop1:~/
- Slave节点配置(每个slave节点都要操作)
a、然后在slave节点/home/ziv/下新建.ssh文件夹(已有的就不用新建了)
mkdir /home/ziv/.ssh
b、将从master复制过来的id_rsa.pub复制到.ssh文件夹里
cat /home/ziv/id_rsa.pub >> /home/ziv/.ssh/authorized_keys
- 远程登陆
sshhadoop1
或sshziv@hadoop1
【坑4】:文件权限
2.4中远程连接如果还是要密码,可能是权限问题;.ssh文件夹权限需要是700;authorized_keys文件权限需要是600;-_-!!!
chmod 600 /home/
ziv/.ssh/authorized_keys
chmod 700 /home/ziv/.ssh
三、安装并配置Hadoop
3.1、安装Hadoop(因为所有节点上的Hadoop文件夹的配置需要是一样的)
master只是多了一个slaves文件夹,但这个对slave主机没影响;所以我们可以先在master主机上配置hadoop文件夹,然后直接复制到slave节点就行。
将Hadoop文件解压到/home/
ziv/文件夹内;
因为文件位置不一样,所以就不给命令了,就是把hadoop-2.6.0.tar.gz解压到/home/ziv/里
3.2、配置Hadoop环境变量(hadoop-env.sh)
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}修改为
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.3、配置yarn环境变量(yarn-env.sh)
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/yarn-env.sh
将export JAVA_HOME=/home/y/libexec/jdk1.6.0/修改为
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.4、配置核心组件(core-site.xml)
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/core-site.xml
在<configuration>和</configuration>之间插入<!--指定namenode地址--></br> <property> <name>fs.defaultFS</name> <value>`hdfs://hadoopmaster:9000`</value> </property> <!--指定使用hadoop时产生文件的存放目录--> <property> <name>hadoop.tmp.dir</name> <value>`/home/ziv/tmp`</value> </property>
3.5、配置文件系统(hdfs-site.xml)
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
在<configuration>和</configuration>之间插入<!--指定secondnamenode的位置--> <property> <name>dfs.namenode.secondary.http-address</name> <value>`hadoopmaster:9001`</value> </property> <!--指定hdfs保存数据的副本数量--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--指定hdfs中namenode的存储位置--> <property> <name>dfs.namenode.name.dir</name> <value>`/home/ziv/dfs/name/`</value> </property> <!--指定hdfs中datanode的存储位置--> <property> <name>dfs.datanode.data.dir</name> <value>`home/ziv/dfs/data`</value> </property>
3.6、配置yarn-site.xml
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/yarn-site.xml
在<configuration>和</configuration>之间插入<!--指定方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定resourcemanager所在的主机名--> <property> <name>yarn.resourcemanager.hostname</name> <value>`HadoopMaster`</value> </property>
3.7、配置MapReduce计算框架文件(mapred-site.xml)
复制mapred-site.xml.template并改名
cp/home/ziv/hadoop-2.6.0/etc/hadoop/mapred-site.xml.temolate/home/ziv/hadoop-2.6.0/etc/hadoop/mapred-site.xml
在<configuration>和</configuration>之间插入
`
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.8、配置Master的slaves文件(slaves)
vim
/home/ziv/hadoop-2.6.0/etc/hadoop/slaves
里面会有缺省的localhost,可以删掉
将所有slave节点主机名,一行一个写到该文件里
hadoop0
hadoop1
3.9、配置slave节点
复制Master上配置好的hadoop文件夹复制到slave节点
scp -r/home/ziv/hadoop-2.6.0ziv@Hadoop0:~/
scp -r/home/ziv/hadoop-2.6.0ziv@Hadoop1:~/
四、启动hdfs
4.1、配置操作系统环境变量(所有节点)
vim /home/
ziv/.bash_profile
添加
export HADOOP_HOME=/home/ziv/hadoop-2.6.0
export PATH=$HADOOP_HOME/bin:$\HADOOP_HOME/sbin:\$PATH
使设置生效
source /home/ziv/.bash_profile
4.2、格式化(仅master节点)
hdfs namenode -format
4.3、启动和关闭
start-dfs.sh
start-yarn.sh
stop-dfs.sh
stop-yarn.sh
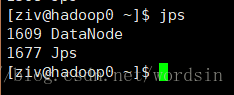
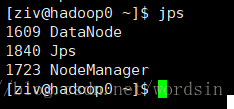
4.5、检测是否成功
jps
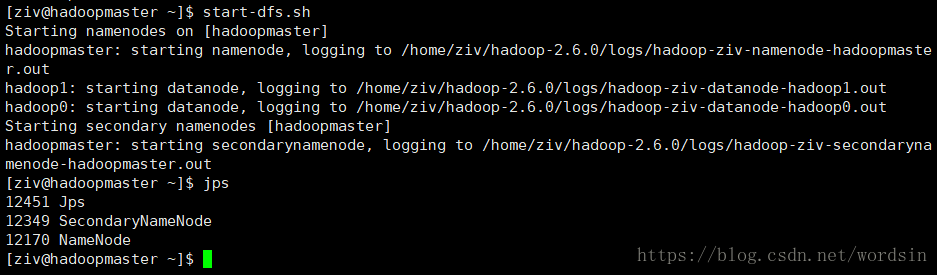
master节点应该有四个
slave节点应该有三个
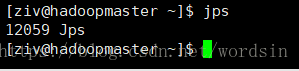
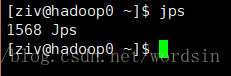
没打开之前jps
start-dfs.sh之后
继续运行 start-yarn.sh之后

【坑5】:mkdir: 无法创建目录”/home/hadoop/hadoop-2.4.1/logs”: 权限不够
在master上运行以下命令:
sudo chown -Rziv:zivhadoop-2.6.0/
花了两天时间,遇见了各种各样的坑,可以说很自信了,如果有哪里没有讲清楚的,欢迎留言-_-!!!