安装 hadoop 集群
参见:ubuntu 基于 docker 搭建 hadoop 3.2 集群
下载 spark
镜像地址:http://mirrors.hust.edu.cn/apache/spark/
wget http://mirrors.hust.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/
cd /usr/local/
mv spark-2.4.5-bin-hadoop2.7 spark-2.4.5
添加环境变量
echo 'export SPARK_HOME=/usr/local/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
source /etc/profile
修改配置文件
cd $SPARK_HOME/conf
ls
docker.properties.template log4j.properties.template slaves.template spark-env.sh.template
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
1. spark-env.sh
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/share/scala
export SPARK_MASTER_HOST=h01
export SPARK_MASTER_IP=h01
export SPARK_WORKER_MEMORY=2g
2. slaves
mv slaves.template slaves
vi slaves
改成
h01
h02
h03
配置其它节点
scp -r /usr/local/spark-2.4.5 root@h02:/usr/local/
scp -r /usr/local/spark-2.4.5 root@h02:/usr/local/
ssh root@h02
echo 'export SPARK_HOME=/usr/local/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
source /etc/profile
exit
ssh root@h03
echo 'export SPARK_HOME=/usr/local/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
source /etc/profile
exit
启动 spark 集群
需要注意 spark 启动和 hadoop 启动的命令相同
root@h01:/usr/local/spark-2.4.0/sbin$ ./start-all.sh
在容器外打开浏览器访问:localhost:8080
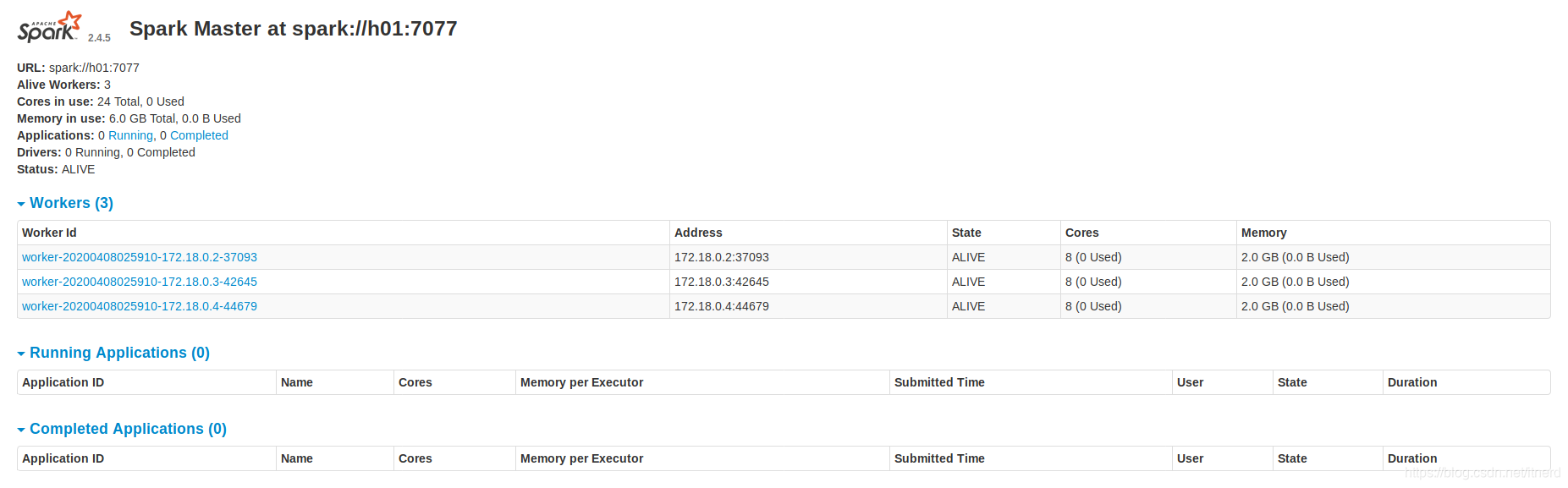 当然前提是,创建容器时做了端口映射:
当然前提是,创建容器时做了端口映射:
docker network create --driver=bridge hadoop
docker run -it --network hadoop -h h01 --name h01 -p 9870:9870 -p 8088:8088 -p 8080:8080 spark /bin/bash
docker run -it --network hadoop -h h02 --name h02 spark /bin/bash
docker run -it --network hadoop -h h03 --name h03 spark /bin/bash
测试
$ cd /usr/local/spark-2.4.5/
$ ./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
Pi is roughly 3.148875744378722
spark shell
$ spark-shell
2020-04-08 01:23:16,397 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://h01:4040
Spark context available as 'sc' (master = local[*], app id = local-1586309004477).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_242)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
