机器学习(Machine Learning)是一门多学科交叉专业,涵盖概率论知识,统计学知识以及复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式, 并将现有内容进行知识结构划分来有效提高学习效率。本专栏将以学习笔记形式对《机器学习》的重点基础知识进行总结整理,欢迎大家一起学习交流!
专栏链接:《机器学习》学习笔记
目录
1. 概述
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。 神经网络中最基本的成分是神经元模型,即上述定义中的“简单单元”。如果某神经元的电位超过一个阈值,那么它就会被激活,即兴奋起来,向其他神经元发送化学物质。
2.神经元模型
M-P 神经元模型 [McCulloch and Pitts, 1943]

M-P神经元模型,在这个模型中,神经元接收到来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。
★功能性的神经元层:有激活函数、有阈值函数(有 Sigmoid 函数)
激活函数
理想激活函数是阶跃函数 , 0表示抑制神经元而1表示激活神经元
阶跃函数具有不连续、不光滑等不好的性质 , 常用的是 Sigmoid 函数

3. 感知机与多层网络
3.1 感知机
感知机(Perceptron)由两层神经元组成(输入层、输出层),输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称“阈值逻辑单元”(threshold logic unit)。
感知机能容易的实现逻辑与、或、非运算。

对于“与”、“或”、“非”问题是线性可分的;
对于“异或”问题是非线性可分的。

3.2 多层前馈网络结构
多层网络:包含隐层的网络
前馈网络:神经元之间不存在同层连接也不存在跨层连接,即网络中无环或者回路。
隐层和输出层神经元亦称“功能单元”(functional unit),无隐藏层的又称“感知机(Perceptron)”
“前馈”并不意味着网络中信号不能像后传,而是指网络拓扑结构上不存在环或回路。
神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值。
换言之,神经网络“学”到的东西,蕴含在连接权和阈值中。

优点:
多层前馈网络有强大的表示能力
只需一个包含足够多神经元的隐层 , 多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数
缺点:
但是,如何设置隐层神经元数是未决问题。实际常用“试错法”
3.3 神经网络发展回顾
1940年代 -萌芽期: M-P模型 (1943), Hebb 学习规则 (1945)
1958左右 -1969左右 ~繁荣期 : 感知机 (1958), Adaline (1960), …
1969年: Minsky & Papert “Perceptrons”
冰河期
1985左右 -1995左右 ~繁荣期 : Hopfield (1983), BP (1986), …
1995年左右:SVM 及 统计学习 兴起
沉寂期
2010左右 -至今 ~繁荣期 :深度学习
发展交替模式 : 热十(年) 冷十五(年)
3.4 误差逆传播算法(BP算法)
误差逆传播算法(error BackPropagation)又称反向传播算法,是多层网络中的杰出代表,它是迄今最成功的神经网络学习算法。现实生活中使用神经网络时,大多是在用BP算法进行训练。值得指出的是,BP算法不仅可以用于多层前馈神经网络,还可用于其类型的神经网络,例如训练递归神经网络。

最成功、最常用的神经网络算法,可被用于多种任务(不仅限于分类)
给定训练集![]()
输入: d维特征向量
输出: l个输出值
隐层:假定使用q个隐层神经元
假定功能单元均使用Sigmoid函数

BP 算法推导
对于训练例![]() , 假定网络的实际输出为
, 假定网络的实际输出为![]()
![]()
则网络在![]() 上的均方误差为:
上的均方误差为:

需通过学习确定的参数数目:![]()
BP 是一个迭代学习算法 , 在迭代的每一轮中采用如下误差修正:![]()

BP 算法基于梯度下降策略,以目标的负梯度方向对参数进行调整
以![]() 为例,对误差
为例,对误差![]() ,, 给定学习率
,, 给定学习率![]() ,, 有:
,, 有:
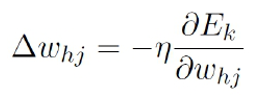
注意到![]() ,先影响到
,先影响到![]() ,再影响到
,再影响到![]() , 然后才影响到
, 然后才影响到![]() , 有:
, 有:
 (链式法则)
(链式法则)
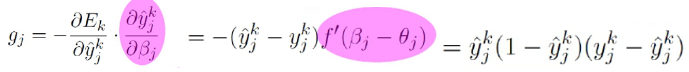
其中项![]() 对
对![]() 有
有![]()
再注意到![]()
于是,
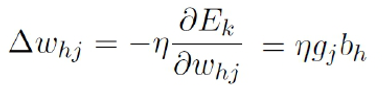
类似地,有:

其中:
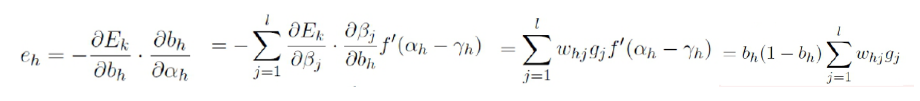
![]()
需要注意的是,BP算法的目标是要最小化训练集D上的积累误差
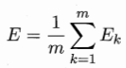

3.5 标准BP算法 和 累积BP算法
标准BP算法
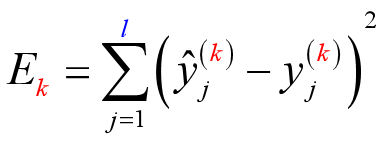
每次针对单个训练样例更新权值与阈值 (每训练1个样本更新一次参数)
参数更新频繁 , 不同样例可能抵消 , 需要多次迭代
累积BP算法
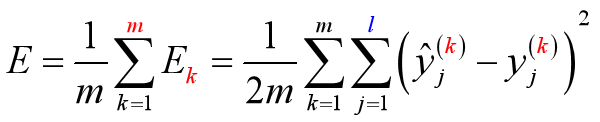
其优化目标是最小化整个训练集上的累计误差
读取整个训练集一遍才对参数进行更新 , 参数更新频率较低
在很多任务中 , 累计误差下降到一定程度后 , 进一步下降会非常缓慢, 这时 标准BP算法往往会获得较好的解, 尤其当训练集非常大时效果更明显。
3.6 BP神经网络过拟合
用“试错法”设置隐藏神经元的个数。
由于其强大的表达能力,BP神经网络经常遭遇过拟合
过拟合表现:训练误差持续降低,但测试误差却可能上升。
两种策略:“早停”、“正则化”
主要策略
早停 (early stopping)
早停将数据分为训练集和验证集,训练集用于计算梯度、权值、阈值,验证集用于估计误差,当训练集误差下降,验证集误差上升,则停止训练。 早停将数据分为训练集和验证集,训练集用于计算梯度、权值、阈值,验证集用于估计误差,当训练集误差下降,验证集误差上升,则停止训练。
☞若训练误差连续 a 轮的变化小于 b, 则停止训练
☞使用验证集:若训练误差降低、验证误差升高 , 则停止训练
正则化 (regularization)
正则化在误差目标函数中增加一个用于描述网络复杂度的部分;例如权值与阈值的平方和。 误差目标函数:
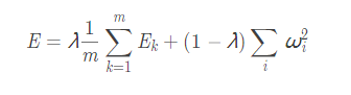
式![]() 偏好比较小的连接权和阈值, 使网络输出更“光滑”
偏好比较小的连接权和阈值, 使网络输出更“光滑”
3.7 全局最小 和 局部极小
神经网络的训练过程可看作一个参数寻优过程:
在参数空间中,寻找一组最优参数使得误差最小
存在多个“局部极小”
只有一个“全局最小”

“跳出”局部极小的常见策略:不同的初始参数、模拟退火、随机扰动、遗传算法 ……
以上用于跳出局部极小的技术大多是启发式,理论上尚缺保障。




4 其他常见神经网络模型
RBF: 分类任务中除BP之外最常用
ART:“竞争学习”的代表
SOM:最常用的聚类方法之一
级联相关网络:“构造性”神经网络的代表
Elman网络:递归神经网络的代表
Boltzmann机:“基于能量的模型”的代表
……
5 深度学习的兴起
2006年 , Hinton发表了深度学习的 Nature 文章
2012年 , Hinton 组参加 ImageNet 竞赛 , 使用 CNN 模型以超过第二名 10个百分点的成绩夺得当年竞赛的冠军
伴随云计算、大数据时代的到来,计算能力的大幅提升,使得深度学习模型在计算机视觉、自然语言处理、语音识别等众多领域都取 得了较大的成功。
最常用的深度学习模型:卷积神经网络
深度学习最重要的特征: 表示学习 、联合优化
欢迎留言,一起学习交流~~~
感谢阅读
