神经网络-卷积神经网络
卷积神经网络:逐层训练是一种训练深度学习参数的一种方法,卷积网络是通过权值共享减少训练难度。关于卷积网络网上可以查到很多关于其算法的讲解以及公式推到。卷积神经网络以其在图像处理特有的优势以至于越来越多的人参与研究当中,这里以手写字母识别为主讲一下个人见解。

在图中可以看出仿照生物视觉,数据的处理到底层越来越抽象越来越觉有表达性。如字-词-句-语义。卷积神经网络最主要的两个部分就是卷积层与下采样层,现在关于算法的创新改进,大部分是对输入预处理,正则化,卷积核大小以及数目的调整,以及下采样的选择(最大下采样或者平均下采样,或者改进成权值竞争的思路)。以下先以字母是别流程作为分析然后在具体阐述。

如上图在字母1的识别流程图,网络结构是C-S-C-S-F-O。两层卷积两层下采样,最后到全链接的到输出结果向量。
这里要先说一下基本的概念与计算模式:卷积其实就是用一个矩阵进行数据过滤,高大尚的说法是局部感受野权值共享,就是一个初始化后的参数矩阵按照卷积模式处理图像,这里卷积模式分为full,same,valid三种三种模式处理的结果得到的特征图大小不一样,三种模式理论上都是对图像矩阵逐个元素相乘求和。表达式为:
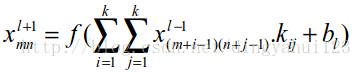
差别在于图像在过滤之初的边界选则不一样,下图是卷积过程的一种动态展示,也是vaild模式的卷积,如图图像矩阵是5X5的图像矩阵,卷积核是3X3的权值矩阵,在开始时权值参数按照预先约定随机初始化,这里的滑动步长为1,即每次移动一个矩阵元素的大小进行下一次卷积操作。valid模式会使图像的大小发生改变,得到的矩阵美其名约特征图,假设原图NXN,卷积核mxm,那么得到的特征图大小为N-m+1(步长为1)。卷积核初始化时参数不同,经过卷积操作得到的特征图也是不一样的,从理论上理解为了保持数据多样性,因为可以理解为不同特征图代表提取到不同的特征,其实也是增加参数增加模型容量和表达能力。
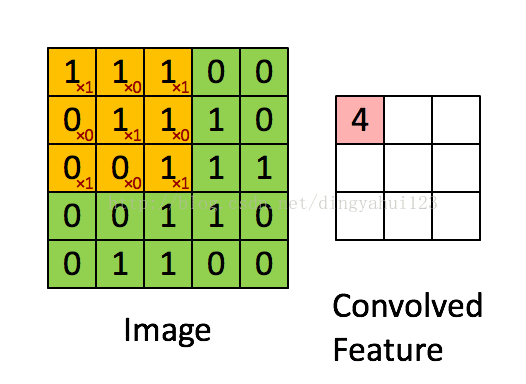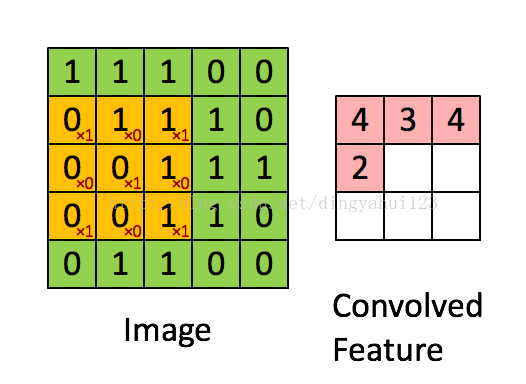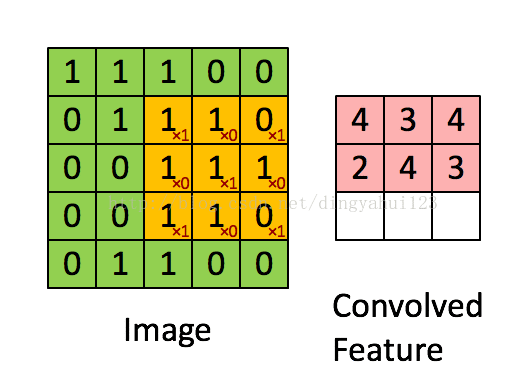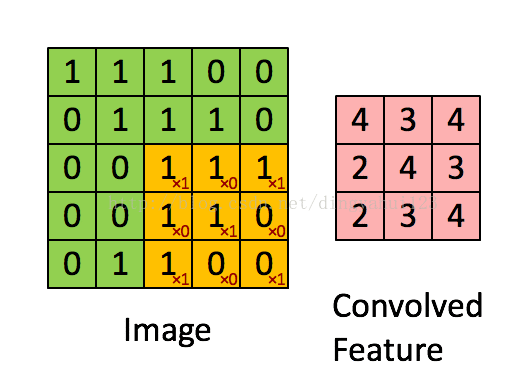
valid模式的卷积图像大小减小从而在后面的运算也变小,但是这种模式的卷积要事先规划好卷积核大小,因为会遇到经过卷积后图像大小变为奇数而到至下采样运算出错,比如说上图的5X5矩阵,经过卷积得到3X3大小的特征图,下一步是下采样,而下采样的步长一般不是1,而是下采样核大小一致,比如这里用2X2大小的平均下采样进行操作,就会在第二次操作的时候图像出现一列数据不足的情况,处理这种情况一般有两种方法解决:1)填补数据,就是增加一行与1列数据,一般补0,2)删除一行一列(其他下采样大小与步长类似,只是补数据与删除数据量不同),但是会导致数据的丢失,所以一般采用,增加数据的处理方式。所以我们在修改比如手写字母是别代码时,增加特征图个数可以,但在修改层次结构比如,层次数目,卷积核大小的时候,要考虑到图像大小对核操作的影响。
与valid模式不同的是full模式会使图像变大,same不改变图像大小,此一般会用于反卷积还原训练。比如先卷积取特者然后反卷积的目标检测算法。
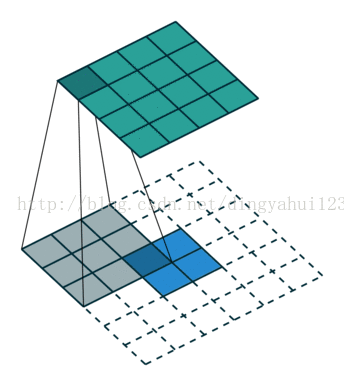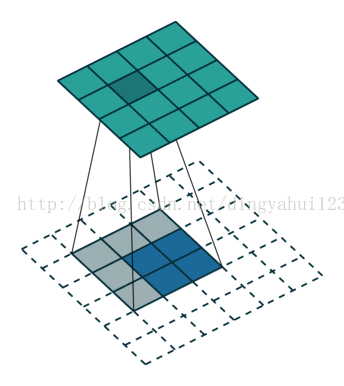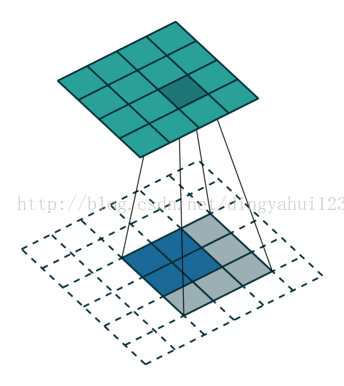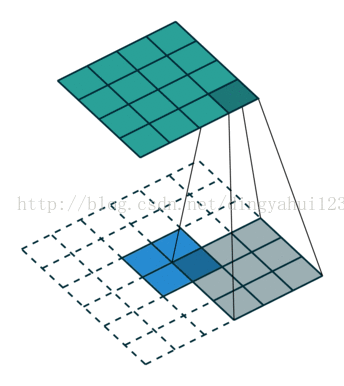
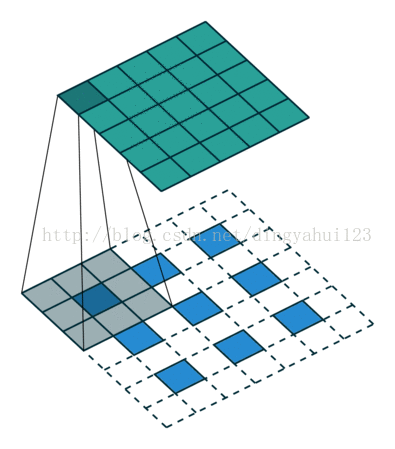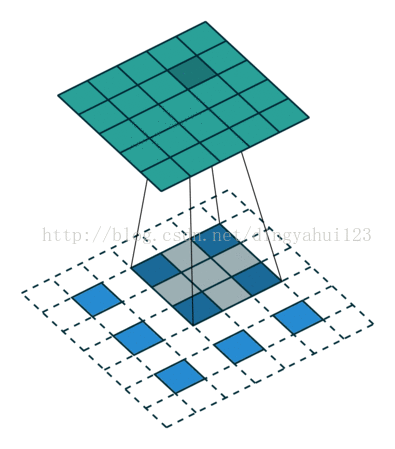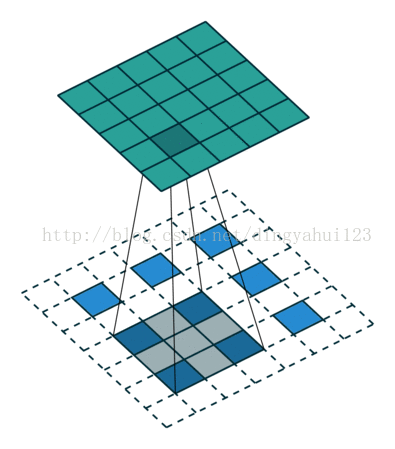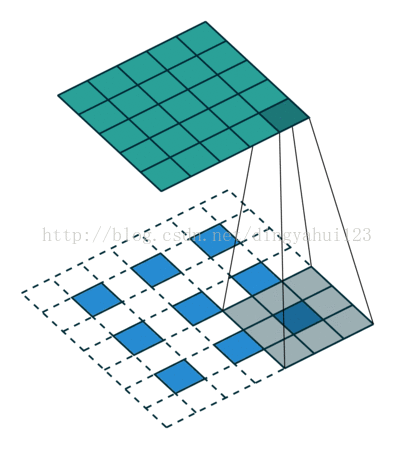
full模式 same模式
如上两图,左图为full模式的卷积,原图2X2,卷积核3X3,卷积结果4X4(N-m+1),same模式图像大小不变,从图看出三种模式卷积不同在于初始时放置规则不一样,那么在full与same初始卷积时数据是要进行填充操作的。上面字母是别中从原图经过6个不同的5X5卷积核,图像变为24X24@6的特征图。经过2X2的下采样变为12X12@6的特征图。在进行下一次卷积的时候,这里是全链接的卷积模式,这里全链接是指,比如C2层的一个特征图是由上层6个特征图经过6个不同5X5卷积核与各自特征图共同得到的。也就是这里得到的所谓12个特征图不是简单的12种卷积核,而是6X12个不同的5x5大小的矩阵。也有人进行算法修改,不进行全链接以一种排列组合的方式尽量让上层所有特征参与运算,这样做是减少全链接的运算量,虽然全链接保证数据复杂与完整,但是运算量大,所谓的一种怕列组合的方式比如C2层的n1是有上层的特征图1、2、3与3个不同的卷积核得到,n2是由上层的2、3、4与三个卷积核操作得到,。。。n5由1、2、3、4得到。类推n12由上层所有图得到。
卷积结果要外加偏置送入激活函数,卷积神经网络其实是神经网络的延伸,这里的偏置与激活函数都合经典人工神经网络一样的。偏置的作用是仿照生物神经脉冲超过一定阈值的才会兴奋,这里加个偏置比较送入激活函数是一样的。在数学理论上也是防止我们的激活函数一开始就趋于极端要么最大值要么最小值,起到一个调节作用。激活函数的选择要方便我们以后对权值的更新修改,即要求其非线性,单调可微,输出范围也要有限定。关于激活函数常用的有sigmoid、ReLU等,真正仿生的化激活函数应该就是两个值1(兴奋),0(抑制)。但是在数学理论上与数据复杂性表达上这样的阶跃函数不利于权值修改,也不利于我们的模型容量的扩充。每种激活函数都有其自己的优点与缺点,卷积网络牛逼之处在于卷积核权值共享,激活函数的选择只是你在修改权值的时候梯度求解或者在初始时容易出现一些极端情况才考率选择哪个激活函数更好。
下采样:下采样是进一步对特征图进行二次处理,进行下采样的目的是为了尽量保持数据复杂与完整性的情况下减少处理数据,比如上面的字母识别,对特征图进行下采样操作,图像从24X24变成了12X12,数目没有变图像大小变为原来的一半。下采样其实也是一种卷积=过滤操作,下采样也有不同的模式,常用的最大下采样和平均下采样。最大下采样选取对应点中最大值作为下一层特征图的中一个值,比如2X2的下采样核,在进行下采样时,对应特征特的四个矩阵值那个值最大选哪个作为结果。平均下采样就是取平均值,比如2X2的核,那么四个参数每个都是0.25,过滤时和特征值对应位置相乘相加作为结果。
光栅化:如上图的字母是别流程,经过卷积操作的后的图像可视化效果,卷积其实和其他手工特征进行模糊操作很像,其实是进行方向性特征提取。卷积的知识可惨看博客,http://blog.csdn.net/zouxy09/article/details/49080029。在经过卷积下采样之后将最后的结果拉成一个n维的列向量就是所谓光栅化,这里其实是回归了经典神经网络,比如这里的192维向量作为输入降维到10维(10个类别)的列向量,这里中间没有隐层,有人修改这里的结构比如从120降到84再到10,增加了隐层增加的参数个数,增加了容量和泛化能力,也有可能过拟合。
分类:这里的分类是和标签进行对比,所谓的标签就是我们人工对字幕设定的一个标定其身份的特征向量,比如这里的激活函数sigmod,输出结果10维中的每个值都是0-1,我们的标签比如字母0的标签是0,1,0,0,0,0,0,0,0,0。其他以此类推,在没有权值调节的时候降维输出的结果每一维值都很接近,经过反向误差调节最后的降维输出和标签就很接近了比如经过多次迭代字母1的输出向第二维接近1,其他无限接近与0,这样就能根据比对标签,我们在输出端判定他是字母1。
参数调节:反向参数调节根据链式法则误差传递调节每一层权值参数,关键是卷积核的调节具体分析请参考http://blog.csdn.net/zouxy09/article/details/9993371,关于参数调节其实也算核心,只有当我们调节网络结构,比如卷积时选择的数量,或者输入图像的数量时我们在原有代码基础上修改相关的部分,即误差产生传递关系要清楚。
应用:卷积网络的应用主要在图像识别和语音处理上,所以创新点往往是结构的微调。现有的也已经有结构平台供试用,层数达到十几层分类上千种。现在也有将卷积网络用于视频上,视频是图像的有序序列集,视频的运动目标检测分类等其实就是融入视频图像中目标的时间与空间信息。容入这些信息思路有:1)在输入层,将图像序列合成再用卷积网络提取分类,这种思想比如先检测目标二值化,将运动过程合在一个图像里,这样就有一个运动剪影过程,如运动历史图像和运动能量图像等。这里的卷积网络就相当于对当个图像模式识别。2)在输入对运动过程处理,比如3D卷积神经网络对运动动作分类。那么具体输入时融入的方法目前有四种,如下所示

在上图中1)单帧融合:单帧融合就是把一帧帧的图像分别输入到CNN中去,和普通的处理图像的CNN没有区别。这种思路没有考虑时间与空间的连续信息,只是一个状态点,而且训练量非常大。2)晚期融合:把相聚L的两帧图像分别输入到两个CNN中去,然后在最后一层连接到同一个full connect的softmax层上去。这里考虑了动作的一个状态的变化,但是,L的选择很难确定多少为好。3)早期融合把连续L帧的图像叠在一起输入到一个CNN中去,他是在晚期融合的基础上的改进,充分考虑了一个动作变化序列。4)慢融合:和上边的CNN的区别在于一个卷积核的输出不是一个二维的图像,而是一个三维的图像。卷积通过多帧组成一个立方体运用3D卷积核处理视频数据。也有卷积网络结合其他算法,比如卷积提起特征SVM分类,或者在卷积的某一层结果出外加编码重构,重构特征比单纯的提出特征要好,但是者参数回调就会相应做出修改。算法的融合一般比单个算法好,现在好多发表的论文大部分是算法结合,或者输入数据预处理,内部微调的等。
卷积网络的训练过程是参数寻优的过程,里面也有许多的技巧,比如参数初始化是预置范围,训练数据的打乱次序等,一个基本的问题训练数据要保持一致,即每类训练样本的数量要一样。这样才能使训练不偏向于某一类样本。另外就是样本标签的设置,上面也提到,要考虑你的激活函数,你不能标签设置为2,0,0,0,0,0之类。因为激活函数的结果最大才是1,如果这样设置会使得只测试此样本正确,其他识别错误。学习率的设定不再多说,就是一个影响微调量大小的参数一般0-1之间设定。过大过小都会带来一定影响。迭代次数的设定需要实验验证,这和你的数据量有关,数据量很大的情况下,迭代次数一般不是很大就会趋于收敛。在未知的情况下可以根据损失函数曲线看迭代次数对调节的影响,在达到一定次数后,在增加次数效果不一定会增强,因为达到一定程度后,会在极值点震荡。
