前置:C++数据结构_树的理论学习笔记(2)_存储结构,二叉树的实现
1.5 Huffman树
1.5.1 Huffman树的定义与存储结构
1.Huffman树的定义
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。树的带权路径长度, 就是树中所有叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)之和

图(C)所示的二叉树其带权路径长度最短,而且再也找不出比此二叉树带权路径长度更短的二叉树了,因此图(C)所示是一棵哈夫曼树
2.Huffman编码
(1)Huffman编码根据字符出现的概率来构造平均长度最短的编码,是一种变长的编码。它的基本原理是频繁使用的数据用较小的代码代替,较少使用的数据用较大的编码代替,每个数据的代码不相同,但最终编码的平均长度最小。
(2)变长的编码:Huffman编码得到的字符编码,其长度因符号出现的概率而有所不同。
(3)Huffman编码的规则:从根结点到叶结点(包含原信息)的路径,向左孩子前进编码为0,向右孩子前进编码为1.也可以反过来规定
示例:
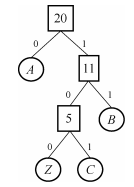
得到字符A、B、C、Z的编码分别为0、11、100、101.显然Huffman编码是前缀编码,即任何一个字符的编码都不是另一个字符编码的前缀。
3.Huffman树的存储结构
以静态散链表来存储结点:
struct HNode
{
int weight; //结点权值
int parent; //双亲数组下标
int LChild; //左孩子数组下标
int RChild; //右孩子数组下标
};
Huffman树是一棵正则二叉树(只有度为0或2的结点的二叉树)。根据二叉树的性质,一棵n个叶子的Huffman树共有2n-1个结点,可以用一个大小为2n-1的一维数组存放Huffman树的各个节点。
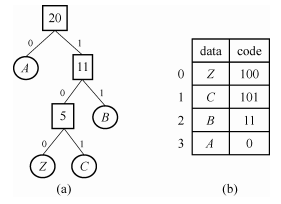
如下图(a)所示的Huffman树有4个叶子结点,因此可以定义存储结构为:
HNode* HTree = new HNode[7];
其存储内容如下图(b)所示,-1表示无孩子结点或双亲结点

还需要设计Huffman编码表对每个结点进行存储。编码表中各元素的C++描述如下:
struct HCode
{
char data;
string code;
};
其中,data存储结点的内存(这里假设其数据类型为char)。code数组存储结点对应的编码(这里采用string存储)。使用HCode类型定义一个一维数组,就可以存储所有结点的编码了。
接下来就可以设计Huffman编码的相关算法了,如构造、编码、解码算法。其C++类描述如下:
class Huffman
{
private:
HNode* HTree; //Huffman树
HCode* HCodeTable; //存储编码表
int N; //叶子结点数量
void code(int i, string newcode); //递归函数,对第i个结点编码
public:
void CreateHTree(int a[], int n, char name[]); //创建Huffman树
void CreateCodeTable(); //创建编码表
void Encode(char* s, char* d); //编码
void Decode(char* s, char* d); //解码
~Huffman();
};
其中,HTree存储Huffman树的结构,HCodeTable存储每个结点的编码内容。(假设要编码的数据和编码结果均为字符串类型)
1.5.2 Huffman树的构造
构造Huffman树的方法就是Huffman算法,描述如下:
将n个带权值的结点构成n棵二叉树的集合T,每棵二叉树只有一个根结点,其左右子树都为空:
①在T中选取两个根结点权值最小的二叉树作为左右子树,构成一棵新二叉树。其根结点的权值为左右子树根结点权值之和;
②在T中删除这两棵树,将新树加入T;
③重复①②操作,直到T中仅存一棵树,该树即Huffman树
图示如下:

生成这样的Huffman树的C++描述:
//输入参数a[]存储每种字符的权值,n为字符的种类,name为各个字符的内容
void Huffman::CreateHTree(int a[], int n, char name[])
{
N = n;
HCodeTable = new HCode[N];
HTree = new HNode[2 * n - 1]; //根据权重数组a[0..n-1]初始化Huffman树
for (int i = 0; i < N; i++)
{
HTree[i].weight = a[i];
HTree[i].LChild = HTree[i].RChild = HTree[i].parent = -1;
HCodeTable[i].data = name[i];
}
int x, y;
for (int i = n; i < 2 * N - 1; i++) //开始建立Huffman树
{
SelectMin(x, y, 0, i); //从1~i中选出两个权值最小的结点的函数
HTree[x].parent = HTree[y].parent = i;
HTree[i].weight = HTree[x].weight + HTree[y].weight;
HTree[i].LChild = x;
HTree[i].RChild = y;
HTree[i].parent = -1;
}
}
1.5.3 Huffman编码表的构建
本文采用向上而下递归的处理方式,对每一个结点进行编码。若子树的根结点是其父结点的左分支则编码“0”,若是右分支则编码“1”,递归处理直到叶子结点。
生成编码表的C++描述如下:
void Huffman::code(int i, string newcode) //递归函数,对第i个结点编码
{
if (HTree[i].LChild == -1)
{
HCodeTable[i].code = newcode;
return;
}
code(HTree[i].LChild, newcode + "0");
code(HTree[i].RChild, newcode + "1");
}
void Huffman::CreateCodeTable() //生成编码表
{
code(2 * N - 2, "");
}
如下图(a)所示的Huffman树,其对应编码表可以是下图(b)的结构
1.5.4 Huffman编、解码的实现
通常,对一段信息进行哈夫曼编码时,需要对编码的数据进行两遍扫描.
(1)第一遍用来统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并要把树的信息及编码表保存起来,以便解压时创建同样的哈夫曼树进行解压;
(2)第二遍根据第一遍扫描得到的哈夫曼编码表对原始数据进行编码,并把编码后得到的码字存储起来
1.编码
生成编码表后,对于要编码的字符串,每读出一个字符,只要在编码表中找出对应编码即可;
2.解码
其基本思想是将编码串从左到右逐位判别,直到确定一个字符。即从Huffman根节点开始,根据每一位是0或者1选择左分支或右分支,直到到达叶子结点,至此每一个字符解码结束。然后,再从根结点开始下一个字符的解码
解码算法的C++描述如下:
void Huffman::Decode(char* s, char* d) //s为编码串,d为解码后的字符串
{
while (*s != '\0')
{
int parent = 2 * N - 2; //根结点在HTree中的下标
while (HTree[parent].LChild != -1) //如果不是叶子结点
{
if (*s == '0')
parent = HTree[parent].LChild;
else
parent = HTree[parent].RChild;
s++;
}
*d = HCodeTable[parent].data;
d++;
}
}

