相关理论可以看这篇文章 Deep Learning using Linear Support Vector Machines,ICML 2013
主要使用的是SVM的hinge loss形式的损失函数
原始的SVM的损失:(公式图片截取自开头的论文)
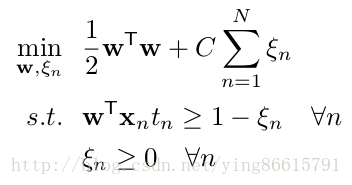
SVM的hinge loss形式的损失:(公式图片截取自开头的论文)
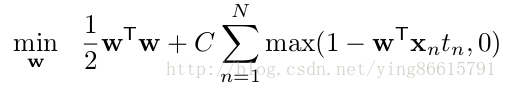
这里解决的是二分类问题,多分类的话和softmax一样,简单说明如下:(公式图片截取自开头的论文)
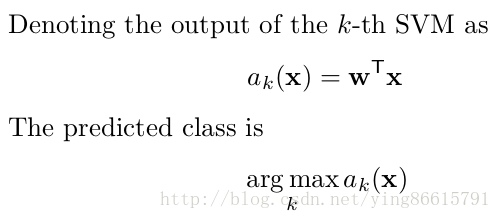
观察那个损失函数可以知道,它其实可以看做是一个 hinge loss 加上一个L2 regularization,前面的1/2就是L2正则项的系数lambda,这在CNN中很容易实现
使用CNN进行多分类的时候,最后一层的神经元个数是类别数目
使用softmax分类时,最后一层的激活函数设置为softmax就好
现在不用激活函数,或者激活函数设置为'linear',即即f(x)=x
prediction = Dense(7,activation='linear', #或者不适用激活函数?
kernel_regularizer=regularizers.l2(0.5),
name=name+'FC_linear')(x)
然后在keras后端添加一个自定义损失(在源代码的losses.py中)
def categorical_squared_hinge(y_true, y_pred):
"""
hinge with 0.5*W^2 ,SVM
"""
y_true = 2. * y_true - 1 # trans [0,1] to [-1,1],注意这个,svm类别标签是-1和1
vvvv = K.maximum(1. - y_true * y_pred, 0.) # hinge loss,参考keras自带的hinge loss
# vvv = K.square(vvvv) # 文章《Deep Learning using Linear Support Vector Machines》有进行平方
vv = K.sum(vvvv, 1, keepdims=False) #axis=len(y_true.get_shape()) - 1
v = K.mean(vv, axis=-1)
return v最后,在编译模型的时候使用自定义损失,名字就是函数的名字了
model.compile( optimizer=adm, loss=['categorical_squared_hinge'], metrics=['accuracy'] )