一、简介
win10, notebook ,python 3.6
支持向量机总结
我们在这里看到了支持向量机背后的原则的简单直观的介绍。这些方法是强大的分类方法,原因有很多:
- 他们依赖相对较少的支持向量,意味着它们是非常紧凑的模型,并且占用很少的内存。
- 一旦训练了模型,预测阶段非常快。
- 因为它们仅受边缘附近的点的影响,它们适用于高维数据,甚至维度大于样本的数据,这对于其他算法来说是一个挑战。
- 内核方法的集成使得它们非常通用,能够适应许多类型的数据。
然而,SVM也有几个缺点:
- 在最差的情况下,样本数
N的复杂度为O(N^3),对于高效的实现,是O(N^2)。对于大量的训练样本,这种计算成本可能令人望而却步。 - 结果强烈依赖于软化参数
C的合适选择。这必须通过交叉验证仔细选择,随着数据集增大,开销也增大。 - 结果没有直接的概率解释。这可以通过内部交叉验证来估计(参见SVC的概率参数),但这种额外的估计是昂贵的。
考虑到这些特性,一般来说,只要其他更简单,更快,并且不需要调优的方法不足以满足我的需求,我一般只会考虑 SVM。然而,如果你投入了足够的 CPU 周期,使用 SVM 训练和验证你的数据,这个方法有很好的效果。
参考:
python数据分析手册
https://jakevdp.github.io/PythonDataScienceHandbook/05.07-support-vector-machines.html
https://www.kesci.com/home/project/5be0480f954d6e0010618cef/code
github的翻译:
https://www.jianshu.com/p/864adfd2f795
二、简单线性SVM
1、首先生成数据
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns; sns.set()
# 随机来点数据,n_samples:50个样本点,centers:中心数,random_state:随机种子,
# cluster_std:簇离散程度,
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
# 数据散点图
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
# print(X)
# print(y)如图:

2、建立模型
# 导入模型,使用线性核,将C参数设置为一个非常大的数值
from sklearn.svm import SVC # "Support vector classifier"
model = SVC(kernel='linear',C=1E10)
# 数据传入SVM模型
model.fit(X, y)辅助绘制函数:
def plot_svc_decision_function(model, ax=None, plot_support=True):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary and margins
# ax.contour在这里画的是三条等高线
# 像levels,alpha这些参数,都可以调节一下,看一下有什么变化
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
# plot support vectors
# 下面的操作是画出距离分界线最近的点
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)3、结果
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(model)
支持向量:
# 支持向量
model.support_vectors_array([[0.44359863, 3.11530945],
[2.33812285, 3.43116792],
[2.06156753, 1.96918596]])4、更改数据集试试
观察可以发现,只需要支持向量我们就可以把模型构建出来
接下来我们尝试一下,用不同多的数据点,看看效果会不会发生变化
分别使用60个和120个数据点
def plot_svm(N=10, ax=None):
X, y = make_blobs(n_samples=200, centers=2,
random_state=0, cluster_std=0.60)
X = X[:N]
y = y[:N]
model = SVC(kernel='linear', C=1E10)
model.fit(X, y)
ax = ax or plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
ax.set_xlim(-1, 4)
ax.set_ylim(-1, 6)
plot_svc_decision_function(model, ax)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, N in zip(ax, [60, 120]):
plot_svm(N, axi)
axi.set_title('N = {0}'.format(N))
左边是60个点的结果,右边的是120个点的结果
观察发现,只要支持向量没变,其他的数据怎么加无所谓!
5、Notebook使用小技巧
notebook,使用 IPython 的交互式小部件,以交互方式查看 SVM 模型的此功能:
from ipywidgets import interact, fixed
interact(plot_svm, N=[10, 200], ax=fixed(None))三、核函数SVM
1、数据
from sklearn.datasets.samples_generator import make_circles
X, y = make_circles(100, factor=.1, random_state=0,noise=.1)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
2、三维可视化
#加入了新的维度r
from mpl_toolkits import mplot3d
r = np.exp(-(X ** 2).sum(1))
def plot_3D(elev=30, azim=30, X=X, y=y):
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap='autumn')
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('r')
plot_3D(elev=45, azim=45, X=X, y=y)
我们可以看到,使用这个附加维度,通过在r = 0.7处绘制分离平面,数据可以线性分离。
在这里,我们必须选择并仔细调整我们的预测:
如果我们没有将径向基函数置于正确的位置,我们就不会看到这样清晰的线性可分离结果。
一般来说,做出这样的选择的需求是一个问题:我们想以某种方式自动找到最佳的基函数来使用。
为此,一个策略是计算以数据集中每个点为中心的基函数,并使 SVM 算法筛选出结果。这种类型的基函数变换被称为核变换,因为它基于每对点之间的相似关系(或核)。
这种策略的潜在问题 - 将N个点投影到N个维度 - 就是随着N增长,它的计算开销可能会变得非常大。然而,由于一个被称为核技巧的简洁的小过程,内核转换数据上的拟合可以隐式完成,也就是说,不需要为核投影构建完全的N维数据表示!这个核技巧内置在 SVM 中,也是该方法如此强大的原因之一。
3、模型构造,加入径向基函数
#加入径向基函数
clf = SVC(kernel='rbf', C=1E6)
clf.fit(X, y)4、绘制
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(clf)
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=300, lw=1, facecolors='none');
使用这种核支持向量机,我们学习一个合适的非线性决策边界。这种核变换策略在机器学习中经常被使用!
四、调整SVM软间距
SVM 实现了软化因子,即“软化”边距:也就是说,如果允许更好的匹配,它允许某些点进入边距。
边缘的硬度由调整参数控制,通常称为C。
对于非常大的C,边距是硬的,点不能进入。
对于较小的C,边缘较软,可以扩展并包含一些点。
调节C参数
- 当C趋近于无穷大时:意味着分类严格不能有错误
- 当C趋近于很小的时:意味着可以有更大的错误容忍
参数C的最佳值将取决于你的数据集,并应使用交叉验证或类似的过程进行调整
1、数据
X, y = make_blobs(n_samples=100, centers=2,
random_state=0, cluster_std=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn');
2、C= 10,与C= 0.1
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, C in zip(ax, [10.0, 0.1]):
model = SVC(kernel='linear', C=C).fit(X, y)
axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(model, axi)
axi.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, lw=1, facecolors='none');
axi.set_title('C = {0:.1f}'.format(C), size=14)
3、gama = 10, 与gama = 0.1
X, y = make_blobs(n_samples=100, centers=2,
random_state=0, cluster_std=1.1)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, gamma in zip(ax, [10.0, 0.1]):
model = SVC(kernel='rbf', gamma=gamma).fit(X, y)
axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(model, axi)
axi.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, lw=1, facecolors='none');
axi.set_title('gamma = {0:.1f}'.format(gamma), size=14) 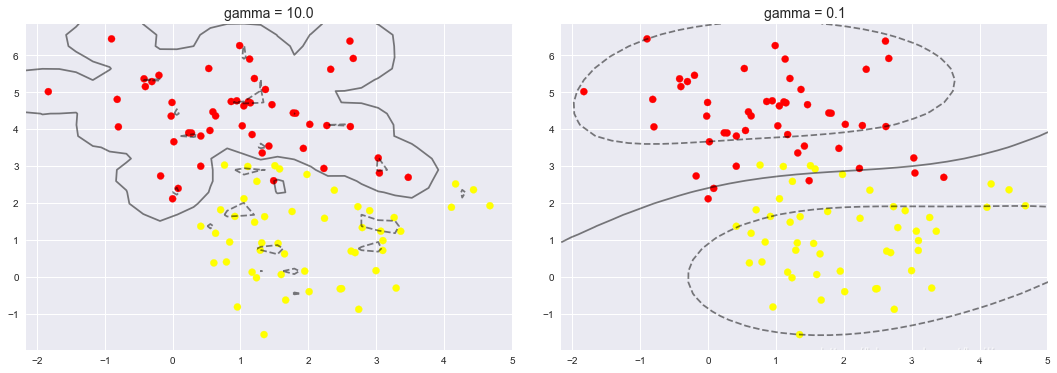
五、SVM实现人脸识别
使用 Wild 数据集中的标记人脸,其中包含数千张各种公众人物的整理照片。 数据集的获取器内置于 Scikit-Learn中。