文章简介
本文是吴恩达深度学习第二周作业的代码实现,代码由吴恩达深度学习课后作业markdown文件改编而来,在朋友charm上编写。该段代码的功能是判断图片中是否有猫,如果有猫则输出“cat”,如果没有猫则输出“non-cat”。本段代码由本人亲自改写,并运行成功,如有转载请注明来源。
学习资源
吴恩达深度学习视频和课后作业百度网盘链接:
https://pan.baidu.com/s/1PfQAn7L0ZE_7Up8qxlTVVA
提取码:tj4j
环境配置
Anaconda3-5.0.1其中python版本是3.6
软件网盘链接:https://pan.baidu.com/s/14SPMaPma6yvdIky1XkjMOA
提取码:qlzy
IDE用的是pycharm 2019.3.3专业版
软件网盘链接:https://pan.baidu.com/s/1L1ctB8zBBowN3Wc8Dj_w9A
提取码:4r2b
如有疑问可关注微信公众号“工科派”

主要内容
1)数据集由209个训练集和50个测试集组成
2)代码中将图片向量化,归一化
3)代码中使用sigmoid函数作为激活函数
4)代码中权值和偏置初始值为0
5)代码中定义了前向传播函数和反向传播函数以及代价函数
6)代码中比较了不同学习率的代价函数下降速度
7)代码中调用了本地图片测试分类结果
运行效果图
代码示例
import numpy as np
import matplotlib.pylab as plt
import h5py
import scipy
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset
train_set_x_orig,train_set_y,test_set_x_orig,test_set_y,classes = load_dataset()
index = 46 # 取第46张图片
plt.imshow(train_set_x_orig[index])
plt.show()
print("y = "+ str(train_set_y[ : ,index]) +",it is a ' " +classes[np.squeeze(train_set_y[:,index])].decode("utf-8") + " ' picture.")
print("---------------数据集的详细内容-----------------")
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
print("训练样本的数量是: m_train =" + str(m_train))
print("测试集的样本数量是: m_test =" + str(m_test))
print("每个图片的长宽是: num_px =" + str(num_px))
print("每个图片的尺寸是: (" + str(num_px) +"," + str(num_px) + ",3")
print("训练集X的尺寸:" + str(train_set_x_orig.shape))
print("训练集y的尺寸:" + str(train_set_y.shape))
print("测试集X的尺寸:" + str(test_set_x_orig.shape))
print("测试集y的尺寸:" + str(test_set_y.shape))
print("---------将样本整合为一个向量后数据集详情----------")
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0],-1).T
print("训练集x向量化后的尺寸:"+ str(train_set_x_flatten.shape))
print("训练集y的尺寸:" + str(train_set_y.shape))
print("测试集向量化后尺寸:" + str(test_set_x_flatten.shape))
print("测试集y的尺寸:" + str(test_set_y.shape))
print("整形后的检查:" + str(train_set_x_flatten[0:5,0]))# 取列向的第0-4个数
# -------------------数据归一化----------------------
train_set_x = train_set_x_flatten/255
test_set_x = test_set_x_flatten/255
# -------------------构建sigmoi函数---------------
def sigmoid(z):
s = 1 / (1 + np.exp(-z))
return s
print("---------------测试simoid函数---------------------")
print("sigmiod([0,2]) = " + str(sigmoid(np.array([0,2]))))
# ----------------------初始化权重和偏置----------------------
def initialize_with_zeros(dim):
w = np.zeros((dim,1))
b = 0
assert (w.shape == (dim,1))
assert (isinstance(b,float)or isinstance(b,int))
return w,b
print("---------------测试初始化结果---------------------")
dim = 2
w,b = initialize_with_zeros(dim)
print("w = " + str(w))
print("b = " + str(b))
# ------------构建正向传播函数------------
def propagate(w,b,X,Y):
m = X.shape[1]
A = sigmoid(np.dot(w.T,X) + b)
cost = -1/m*np.sum(Y*np.log(A) + (1-Y)*np.log(1-A))
dw = 1/m*np.dot(X,(A - Y).T)
db = 1/m*np.sum(A-Y)
assert (dw.shape == w.shape)
assert (db.dtype == float)
cost = np.squeeze(cost)
assert (cost.shape == ())
grads = {"dw":dw,
"db":db}
return grads,cost
print("--------------正向传播测试--------------------")
w,b,X,Y = np.array([[1],[2]]),2,np.array([[1,2],[3,4]]),np.array([[1,0]])
grads,cost= propagate(w,b,X,Y)
print("dw = " + str(grads["dw"]))
print("db = " + str(grads["db"]))
print("cost = " + str(cost))
# -------------------构建反向传播函数--------------------
def optimize(w,b,X,Y,num_iteration,learning_rate,print_cost = False):#num_iteration是优化循环的迭代次数
costs = []
for i in range(num_iteration):
grads,cost = propagate(w,b,X,Y)
dw = grads["dw"]
db = grads["db"]
w = w - learning_rate*dw
b = b - learning_rate*db
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print("经过i次循环后损失函数值 i = %i:%f" %(i,cost))
params = {"w" : w,
"b" : b}
grads = {"dw" : dw,
"db" : db}
return params,grads,costs
print("----------------测试反向传播--------------")
params,grads,costs = optimize(w,b,X,Y,num_iteration= 100,learning_rate= 0.009,print_cost= False)
print("w = " + str(params["w"]))
print("b = " + str(params["b"]))
print("dw = " + str(grads["dw"]))
print("db = " + str(grads["db"]))
print(costs)
# --------------构建预测函数-----------------
def predict(w,b,X):
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0],1)
A = sigmoid(np.dot(w.T,X) + b)
for i in range(A.shape[1]):
if A[0,i] <= 0.5:
Y_prediction[0,i] = 0
else:
Y_prediction[0,i] = 1
assert (Y_prediction.shape == (1,m))
return Y_prediction
print("-------------测试预测结果--------------------")
print("预测结果:" + str(predict(w,b,X)))
# -------------------将所有函数合并到一个模型中-----------------
def model(X_train,Y_train,X_test,Y_test,num_iterations = 2000,learning_rate = 0.5,print_cost = False):
w,b = initialize_with_zeros(X_train.shape[0])
parameters,grads,costs = optimize(w,b,X_train,Y_train,num_iterations,learning_rate,print_cost)
w = parameters["w"]
b = parameters["b"]
Y_prediction_test = predict(w,b,X_test)
Y_prediction_train = predict(w,b,X_train)
print("训练集精度:{} %".format(100 - np.mean(np.abs(Y_prediction_train-Y_train))*100))
print("测试集精度:{} %".format(100 - np.mean(np.abs(Y_prediction_test-Y_test))*100))
d = {"costs" : costs,
"测试集预测结果": Y_prediction_test,
"训练集预测结果": Y_prediction_train,
"w": w,
"b": b,
"learning_rate": learning_rate,
"num_iterations": num_iterations}
return d
print("--------------------测试模型---------------------")
d = model(train_set_x,train_set_y,test_set_x,test_set_y,num_iterations= 2000,learning_rate=0.005,print_cost= True)
index = 15
plt.imshow(test_set_x[:,index].reshape((num_px,num_px,3)))
plt.show()
print("y = " + str(test_set_y[0,index]) + ",预测结果是\"" + classes[int(d["测试集预测结果"][0,index])].decode("utf-8")+"\" picture")
print("---------------显示被预测图片---------------")
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('代价函数值')
plt.xlabel('每一百次迭代')
plt.title("学习率 = " + str(d["learning_rate"]))
plt.show()
# ---------------------改变学习率---------------------
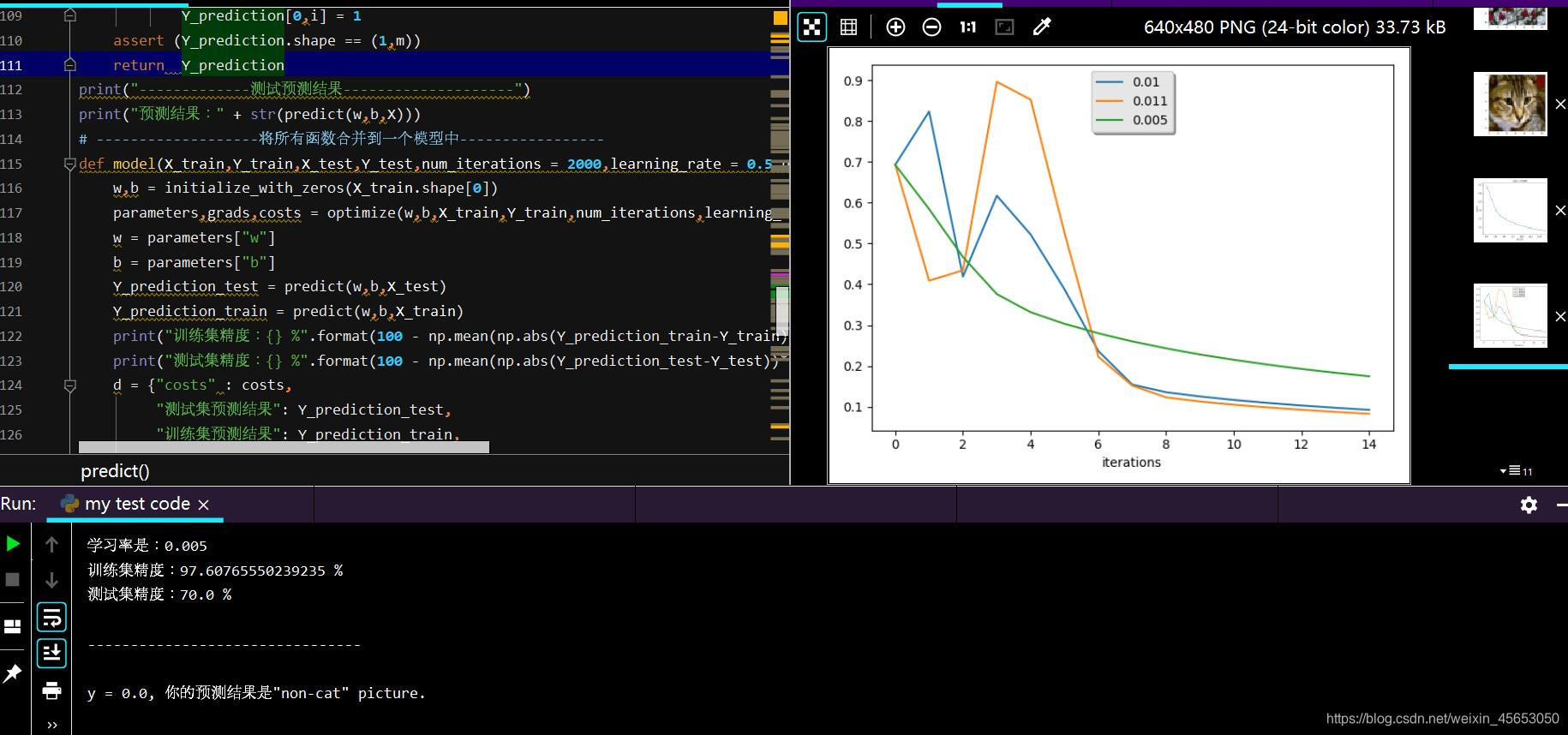
learning_rates = [0.01,0.011,0.005]
models = {}
for i in learning_rates:
print("学习率是:" + str(i))
models[str(i)] = model(train_set_x,train_set_y,test_set_x,test_set_y,num_iterations = 1500,learning_rate = i,print_cost = False)
print('\n' + "--------------------------------" + '\n')
for i in learning_rates:
# plt.plot(np.squeeze(models[str(i)]["损失函数"]), label= str(models[str(i)]["学习率"]))
plt.plot(np.squeeze(models[str(i)]["costs"]), label=str(models[str(i)]["learning_rate"]))
plt.xlabel('cost')
plt.xlabel("iterations")
legend = plt.legend(loc='upper center',shadow= True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()
# --------------测试本地图片------------
my_image = "my_image.jpg"
fname = "images/" + my_image
image = np.array(ndimage.imread(fname,flatten=False))
my_image = scipy.misc.imresize(image,size = (num_px,num_px)).reshape((1,num_px*num_px*3)).T
my_predicted_image = predict(d["w"], d["b"], my_image)
plt.imshow(image)
plt.show()
print("y = " + str(np.squeeze(my_predicted_image)) + ", 你的预测结果是\""
+ classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
