一、什么是hive
如下图所示,hive在Hadoop生态中处于比较高层的位置,其本质上就是将mapreduce转换成了sql的写法。
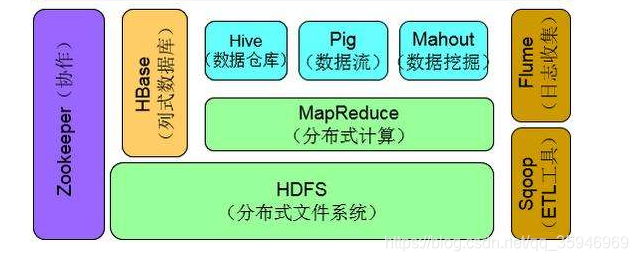
却也sql不尽然相同,毕竟mysql等关系型数据的sql则是服务于web、应用等,是为了让数据更面向对象、更稳定、更原子性操作。而hive的目的则是数据分析,不需要对每一条数据都负责,只是分析数据的特性特征。
二、hive的原理
我们知道了什么是hive,那么hive的原理是什么呢?它和sql数据库一样基于本地文件系统上吗?显然并不是的,总结一下,:
1、hive底层文件系统为HDFS(即分布式文件系统,这就说明hive比起关系型数据库,存储的数据量可以倍数级提升)
2、hive的执行过程:hiveQL转化为mapreduce,mapreduce运行于yarn平台(即hive运行的实质上是mapreduce,并不快,但是可处理数据量大)
三、hive使用
hive实际使用可以通过两种方式:hive-cli客户端中交互式操作;hive命令提交语句或sql文件。
hive在实际使用过程中只要编写普通的sql即可,于一般sql操作无太大区别,需要注意的地方:
1、没有指定databse,则默认使用default库。
2、创建table的时候有三种方式:内部表(类似一般sql表)、外部表(通过hdfs上已存在的结构化数据直接创建出表)、临时表(只对当前session有效)
3、table有分区的概念,table可以按照table内字段进行分区(比如员工表按照年和月进行分区)。分区后每一个分区都在hdfs上有单独的存储文件夹,这样大大提高了单分区的操作速度。
4、hive在涉及join、groupby等操作的时候需要注意数据倾斜、资源分配不均的问题,这也是hive调优的重点。对于要处理的数据,要明白hive转换成mapreduce后,每个节点处理多少数据,是否均匀。
5、hive有describe、explain等语句,可以查看我们所写sql的执行计划。
