最小化损失函数的优化方法
一、最小二乘法
对损失函数求导,使导数为0
二、梯度下降法
- 步长/学习率很重要,太小速度慢,太大不收敛
- 对数据先进行归一化,能够提高梯度下降的执行速度
- 通过误差调整权重的方法:样本数量和迭代次数
1.批量梯度下降法BGD
(1)使用全部数据
(2)梯度就是导数
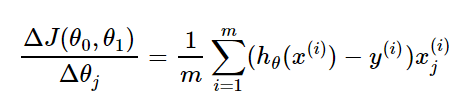
(3)梯度更新,就是在原有形式上变化一个梯度的值。其中j表示第几次迭代,α是学习速率
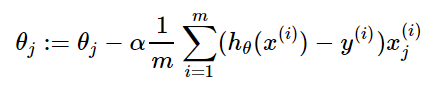
(4)优点:当损失函数是凸函数时,可达到全局最优
(5)缺点:速度慢
2.随机梯度下降法SGD
(1)每次迭代使用一个样本进行更新
(2)求导
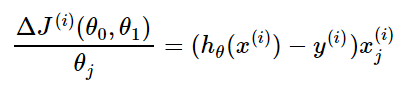
(3)梯度更新
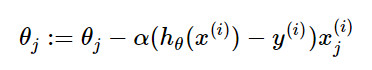
(4)优点:速度快
(5)缺点:局部最优,准确性下降
(6)刚开始学习率大,之后学习率减小
3.小批量梯度下降
(1)每次迭代使用batch_size个样本进行梯度更新
(2)优点:迭代次数降低,准确性比SGD高
(3)缺点:batch_size值的选择
(4)适量增大batch_size值:内存的利用率提高;迭代次数减少;梯度下降方向越准
