HashMap源码部分截取:
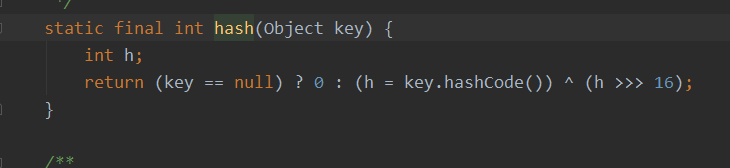
- 取hash操作如下图所示
- put操作如下

-
第二幅图为什么使用(n - 1) & hash = key在数组中的索引
对于创建hashmap时,他的size一定是2^n次方个,有兴趣的可以看一下hashmap的tableSizeFor方法,这就不做阐述!这里&运算有点类似于对数组进行取模运算.因为n为2的n次方,他的二进制是1后面+0,如果减一之后就变为全部为1,比如n=16的二进制10000,15的二进制1111,&与操作是见0就是0,因此如果用16&,不管hash值为多少后面4为全部都是0,这样跟hash表较少出现hash碰撞是相违背的,因为采用n-1的方式&,这样在保证索引永远不大于n-1的同时,因为hash的随机也保证了数据均匀的散列在hash表里 -
第一幅图h = key.hashCode() hashcode如何保证唯一呢?
因为返回的是对象在堆中的存储地址,所以可以保证唯一性!
ps补充:
hashcode本身是个32位int整型值,在系统中,这个值对于不同的对象必须保证唯一(JAVA规范),这也是大家常说的,重写equals必须重写hashcode的重要原因。
- 第一幅图h >>> 16为什么要无符号右移16位呢
因为不同对象的hashcode值是不同的(参照上个问题保证唯一性),转化为2进制有些hashcode位数会非常的高,如果仅仅使用低位的hashcode就会出现较多的hash碰撞,hashcode值无符号右移16位就可以得到较高位数的hashcode值,因而设计者这里^一个h>>>16, ^异或运算是同样则为0,不同则为1.此处比较合适,因为如果用&会偏向于0多一些,用|会偏向于1多一些.
如果有不对的,欢迎指正和讨论!!!共同学习!共同进步!
