目录
数据仓库(DW或DWH)是一个面向主题的、集成的、随时间变化的,但信息本身相对稳定的数据集合。
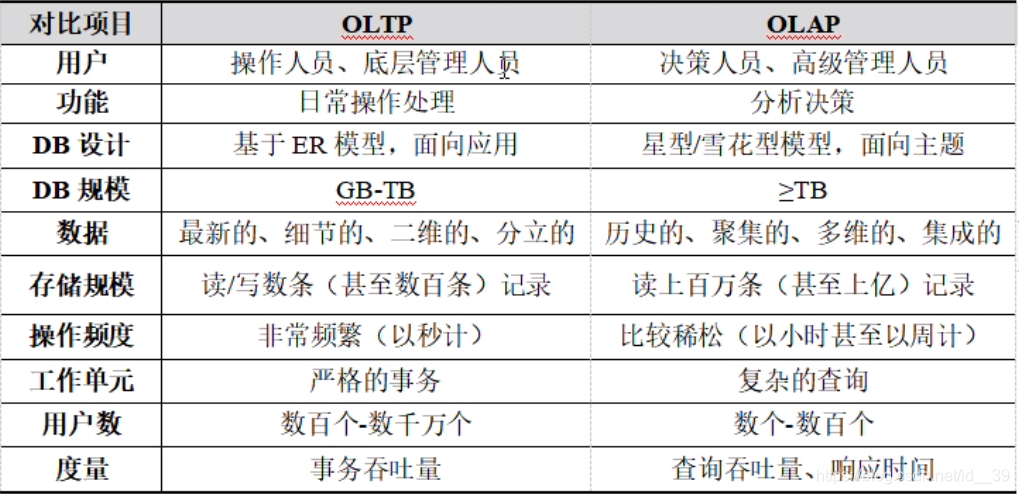
数据仓库三个特点:(选择题)
- 面向主题
- 随时间变化
- 相对稳定
数据库和数据仓库的主要区别:
- 数据库只存放当前值;数据仓库存放历史值;
- 数据库内数据是动态变化的,只要有业务发生,数据就会被更新;而数据仓库则是静态的历史数据,只能定期添加、刷新;
- 数据库中的数据结构比较复杂,有各种结构以适合业务处理系统的需要;而数据仓库中的数据结构则相对简单;
- 数据库中数据访问频率较高,但访问量较少;而数据仓库的访问频率低但访问量却很高;
- 数据库中数据的目标是面向业务处理人员的,为业务处理人员提供信息处理支持;而数据仓库则是面向高层管理人员的,为其提供决策支持;
- 数据库在访问数据时要求响应速度快,其响应时间一般在几秒内;而数据仓库的响应时间则可长达数几个小时;
数据处理两大类型:
- 联机事务处理(OLTP):传统关系数据库主要应用,侧重事务处理
- 联机分析处理(OLAP):数据仓库系统主要应用,复杂的分析操作,侧重决策支持
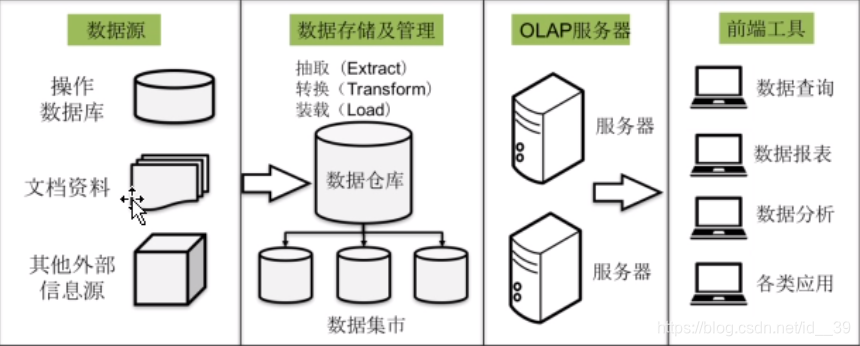
数据仓库结构:
- 数据源:是数据仓库的基础,即系统的数据来源,通常包含企业的各种内部信息和外部信息。
- 操作数据库
- 文档资料
- 其他外部信息源
- 数据存储及管理:是整个数据仓库的核心,决定了对外部数据的表现形式,针对系统现有的数据,进行抽取、清理并有效集成,再按照主题进行组织。
- 抽取
- 转换
- 装载
- 数据仓库–>数据集市
- OLAP服务器:对需要分析的数据按多维数据模型进行重组,以支持用户随时进行多角度、多层次的分析,并发现数据规律和趋势。
- 服务器
- 前端工具:主要包含各种数据分析工具、报表工具、查询工具、数据挖掘工具以及各种基于数据仓库或数据集市开发的应用。
- 数据查询
- 数据报表
- 数据分析
- 各类应用
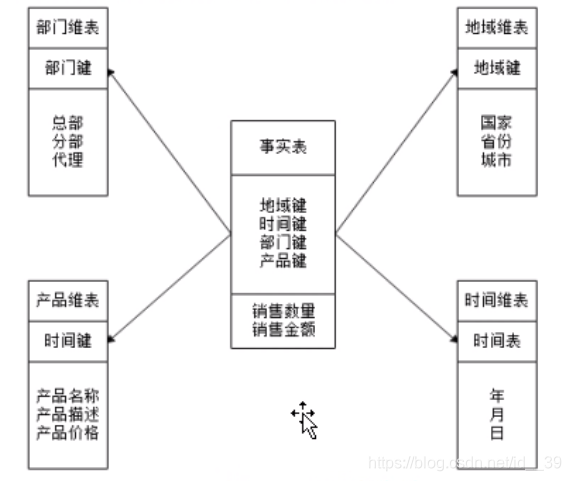
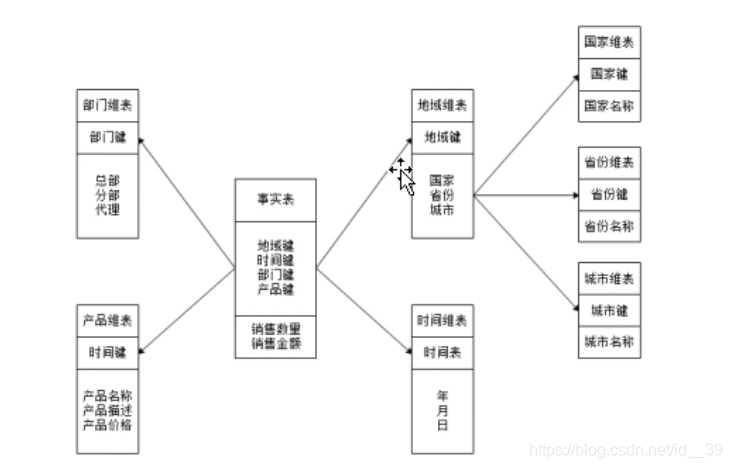
数据仓库的数据模型:
- 星型模型(常用):是以一个事实表和一组维度表组合而成,并以事实表为中心,所有维度表直接与事实表相连,但维度表之间是不关联的。
- 事实表:是分析主题的度量,包含了唯独表关联的外键,记录会不断增加
- 维度表:记录事实数据或汇总的数据(维度是对数据进行分析的一个角度)
- 雪花模型:是当一个或多个维表没有直接连到事实表上,而是通过其他维表连到事实表上。
Hive:
- 起源于Facebook。
- 是建立在hadoop文件系统上的数据仓库平台,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),是一种可以存储、查询和分析存储在hadoop中的大规模数据的工具,即Hive是一个SQL解析引擎,它将SQL语句转译成MapReduce作业并在hadoop上执行。(HiveQL不区分大小写)
- Hive采用SQL的查询语言HQL
Hive和MySQL区别:
| 对比项 | Hive | MySQL |
|---|---|---|
| 查询语言 | Hive QL | SQL |
| 数据存储位置 | HDFS | 块设备、本地文件系统 |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
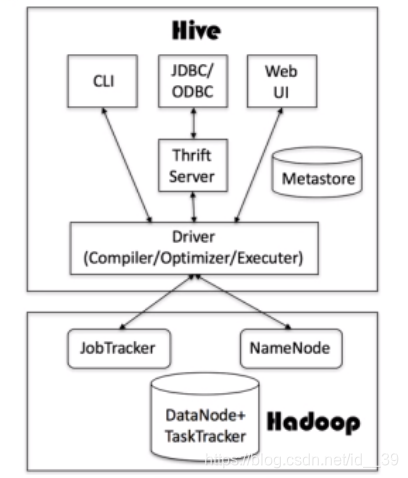
Hive系统框架组成:
- 用户接口(CLI,JDBC/ODBC,WebUI)
- 跨语言服务(Thrift server)(不同的编程语言进行调用)
- 底层驱动引擎(编译器,优化器,执行器)
- 元数据库(Metastore)(表名,列,分区等相关信息,存储在derby或MySql)
Hive运行机制:
- 用户通过用户接口连接Hive,发布Hive SQL
- hive解析查询并制定查询计划
- hive将查询转换成MapReduce作业
- hive在hadoop上执行MapReduce作业(降低分析人员使用hadoop进行数据分析的难度)
hive工作原理
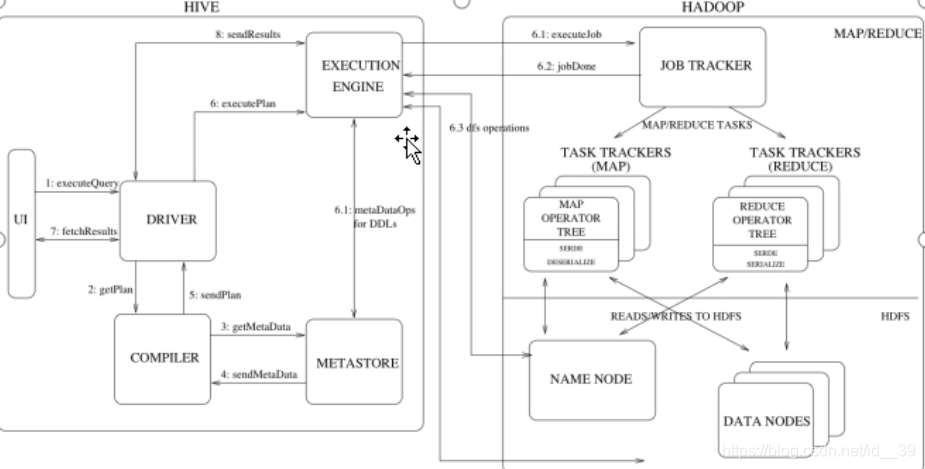
1:UI向Driver发送查询操作;
2:Driver借助编译器解析查询,期望获取查询计划;
3:编译器将元数据请求发送给Metastore;
4:Metastore将元数据以响应的方式发送给编译器;
5:编译器检查需求,并将计划重新发送给Driver;
6:Driver(驱动引擎)将执行计划发送给执行引擎,执行任务;
7:执行引擎从DataNode中获取结果,并将结果发送给UI和Driver;
hive数据模型
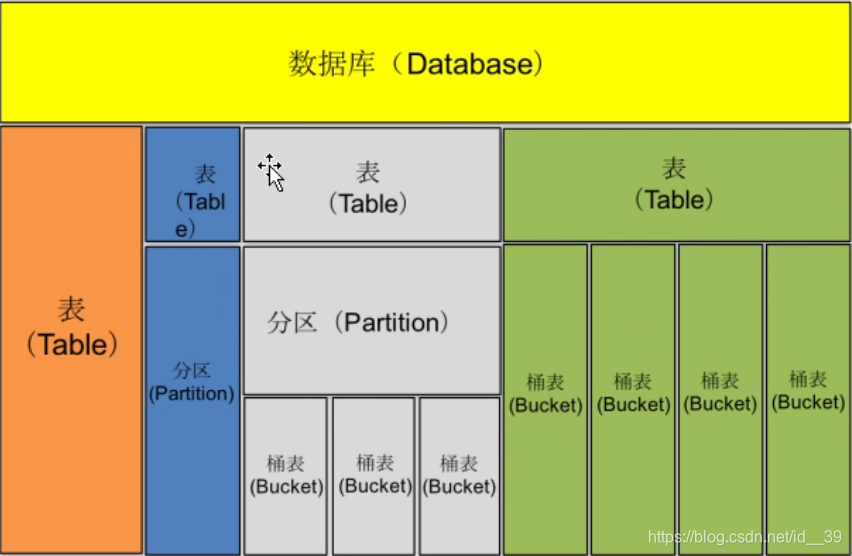
hive中所有数据都存储在HDFS中,它包含四种数据类型(粒度从大到小进行划分):
- 数据库(Database):相当于关系型数据库中的命名空间,它的作用是将用户和数据库的应用隔离到不同的数据库或者模式中;
- 表(Table):Hive的表在逻辑上由存储的数据和描述表格数据形式的相关元数据组成。表存储的数据存放在分布式文件系统中。Hive中的表分为两种类型,一种叫做内部表,这种表的数据存储在Hive数据仓库中,一种叫做外部表,这种表的数据可以存放在Hive数据仓库外的分布式文件系统中,也可以存储在hive数据仓库中。。hive数据仓库也就是HDFS中的一个目录,这个目录是Hive数据存储的默认路径,它可以在Hive的配置文件中配置,最终也会存放到元数据库中。
- 分区表(Partition):在Hive存储上的体现就是在表的主目录(Hive的表实际显示就是一个文件夹)下的一个子目录,这个子目录的名字就是我们定义的分区列的名字;分区的目的是为了加快数据查询速度设计的。
- 桶表(Bucket):就是把大表分成了小表,把表或者分区组织成桶表的目的主要是为了获得更高的查询效率,尤其是抽样查询更加便捷。桶表是Hive数据模型的最小单元,数据加载到桶表时,会对字段的值进行哈希取值,然后除以桶个数得到余数进行分桶,保证每个桶中都有数据,在物理上,每个桶表就是表或分区的一个文件。