Hive基础
一、简介
Hive 是一个构建在 Hadoop 之上的数据仓库
- 可以将结构化的数据文件映射为一张数据库表
- 提供类 sql 的查询语言 HQL(Hive Query Language),可以将 sql 语句转换为 MapReduce 任务运行
二、优点和缺点
2.1、优点
- 入门简单,HQL语法类似SQL
- 统一的元数据管理,可与 impala/spark 等共享元数据
- 灵活性和扩展性较好:支持自定义用户函数 (UDF),自定义存储格式等
- 支持在不同的计算框架上运行 (MR,Tez,Spark)
- 可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统,一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
- 执行延迟高,不适合做数据的实时处理,适合离线数据处理,稳定可靠 (真实生产环境)
相比MapReduce,Hive的执行效率较慢,但有着更快的开发效率
2.2、缺点
(1)hive的HQL表达能力有限
-
迭代式算法无法表达(复杂的逻辑算法不好封装)
-
数据挖掘方面,由于MapReduce数据处理流程的限制(比较慢,因为底层的缺点也都还在),效率更高的算法却无法实现
(2)hive的效率比较低
1)hive自动生成的MapReduce作业,通常情况下不够智能化
2)hive调优比较困难,粒度较粗(只能在框架的基础上优化,不能深入底层MR程序优化)
3)hive可控性差
三、体系架构

Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL), 使用自己的Driver, 结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口
3.1、客户端 (Client)
客户端需要通过工具连接Hive Server,常见的工具有如下三种:
- Hive Thrift
通信框架,可以使用 Thrift 连接 Hive - Hive JDBC Driver (常用)
连接Hive客户端 - Hive ODBC Driver
3.2、服务端 (Services)
客户端通过一系列接口连接Driver,Driver 是Hive Server的驱动
- CLI(command-line interface 命令行)
命令行接口,是最常用的一种用户接口 - JDBC/ODBC(jdbc访问hive)
通过Client与Hive Server保持通讯,借助thrfit rpc协议来实现交互 - WEBUI(浏览器访问hive)
开发测试常用
其他组件
- 元数据(Metastore)
用于存储hive的元数据,包括表名、表所属的数据库、表的拥有者、列/分区字段、表的类型、表的数据所在目录等内容 - 驱动(Driver)
包括Interpreter、Complier、Optimizer 和 Executor,作用是将我们写的HQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架
>SQL解析器:将SQL字符串(准确说HiveQL)转化为抽象语法树AST;
>编译器:将AST编译生成逻辑执行计划;
>逻辑优化器:对逻辑执行计划进行优化;
>物理执行器:将逻辑执行计划转成可执行的物理计划,常用的为MR/TEZ/Spark;
3.3、底层
Hive底层存储是基于 HDFS 进行存储,Hive的计算底层是转换成 MapReduce 进行计算。
- Hive metastore database
元数据数据库 - Hadoop cluster
使用hadoop的集群进行MapReduce计算
四、Hive元数据管理
Metastore的存储有两个部分,服务和存储,Hive元数据的存储有三种部署模式,分别为内嵌模式、本地模式和远程模式。
◼内嵌模式
- 这种模式也叫单用户模式,它是Hive Metastore的最简单的部署方式,使用Hive内嵌的Derby数据库来存储元数据。
- 但是Derby只能接受一个Hive会话的访问,试图启动第二个Hive会话就会导致Metastore连接失败。
- 适合测试和演示
◼本地模式(常用):实际生产一般存储在MySQL中
本地模式也叫多用户模式,它是Metastore的默认模式,该模式下,单Hive会话以组件方式调用Metastore和Driver。
- 修改配置文件hive-site.xml (库路径、连接驱动、用户名和密码)
hive.jdo.option.connectionURL="jdbc:mysql://{hostname}/{database name}?createDatabaseIfNotExist=true"
hive.jdo.option.ConnectionDriverName="com.mysql.jdbc.Driver"
hive.jdo.option.connectionUserName="{userName}"
hive.jdo.option.connectionPassword="{userPassword}"
- 将MySQL的JDBC驱动Jar文件放到Hive的lib目录下
◼远程模式
用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。它将Metastore分离出来,成为一个独立的Hive服务
五、Hive操作
Hive操作常用的客户端工具有两种,分别为:Beeline和Hive命令行(CLI)
Hive操作又分为两种模式 ,一种为命令行模式,一种为交互模式。
5.1、HiveServer和HiveServer2
- Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
- HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
- HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于
HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI
已经不推荐使用了,官方更加推荐使用 Beeline。
5.2、命令行模式
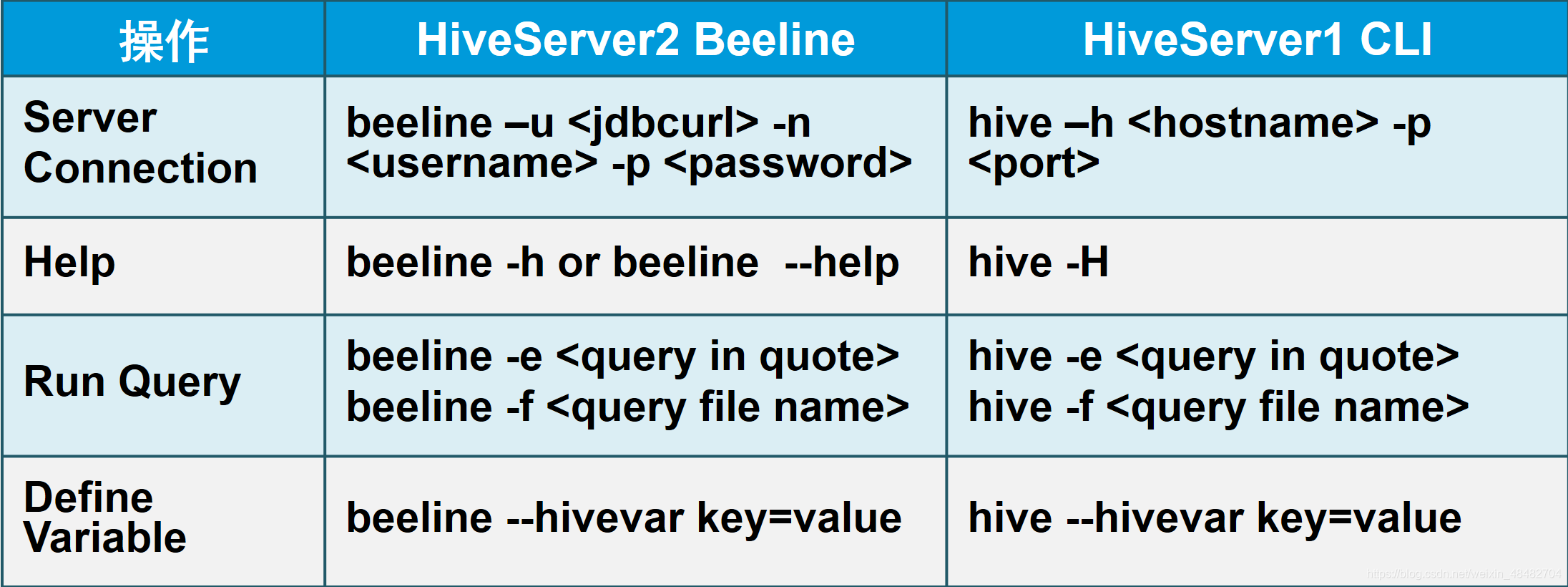
hive
- 使用 -e 参数来直接执行sql语句
# 注意sql语句末尾有分号
[root@single ~]# hive -e "show databases;"
- 使用 –f 参数通过指定文本文件来执行sql语句,可以是本地文本文件也可以是HDFS文件
[root@single test]# vi hive2.sql
# 在hive2.sql文件中写入show databases;
# 保存退出,注意语句末尾有分号
# 本地文件
[root@single test]# hive -f hive2.sql
# HDFS文件
[root@single test]# hive -f hdfs://single:8020/test/hive2.sql;
- 开启本地运行模式:
set hive.exec.mode.local.auto = true;,reduce个数小于等于1的时候本地模式才有效,reduce默认数-1,可以通过命令:set mapreduce.job.reduces;查看,如果需要设置reduce个数,可以使用命令:set mapreduce.job.reduces=1;
beeline
- 需要先后台启动HiveServer2
[root@single ~]# nohup hive --service hiveserver2>/dev/null 2>&1 &
- 使用 -e 参数来直接执行sql语句
[root@single ~]# beeline -u "jdbc:hive2://single:10000" -e "show databases";
- 使用 –f 参数通过指定文本文件来执行sql语句
[root@single test]# beeline -f hive2.sql -u "jdbc:hive2://single:10000"
- 去除beeline页面的INFO日志:
set hive.server2.logging.operation.level=NONE; - 开启beeline页面的INFO日志:
set hive.server2.logging.operation.level=EXECUTION;
5.3、交互模式

hive
(1)交互模式
[root@single ~]# hive
查看所有数据库
hive> show databases;
# hive后面会出现库名,只对当前会话有效
hive> set hive.cli.print.current.db=true;
hive (default)>
创建数据库
hive> create database hivetest;
(2)使用beeline(需要启动hiveserver2)
- 启动metastore(非必须)
[root@single ~]# nohup hive --service metastore>/dev/null 2>&1 &
- 启动hiveserver2
[root@single ~]# nohup hive --service hiveserver2>/dev/null 2>&1 &
使用beeline连接hiveserver2——方法①(需要输入用户名和密码)
[root@single ~]# beeline
...
beeline> !connect jdbc:hive2://single:10000
scan complete in 1ms
Connecting to jdbc:hive2://single:10000
Enter username for jdbc:hive2://single:10000: root
Enter password for jdbc:hive2://single:10000: ****
Connected to: Apache Hive (version 1.1.0-cdh5.14.2)
Driver: Hive JDBC (version 1.1.0-cdh5.14.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://single:10000>
使用beeline直接连接hiveserver2——方法②(不需要输入用户名和密码)
[root@single ~]# beeline -u jdbc:hive2://single:10000
...
scan complete in 2ms
Connecting to jdbc:hive2://single:10000
Connected to: Apache Hive (version 1.1.0-cdh5.14.2)
Driver: Hive JDBC (version 1.1.0-cdh5.14.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.1.0-cdh5.14.2 by Apache Hive
0: jdbc:hive2://single:10000>
六、数据类型
6.1、基本数据类型
| 数据类型 | java | mysql | hive |
|---|---|---|---|
| 字符串 | String | char(n)/varchar(n)/text/… | string/varchar(65536)/char(255) |
| 字符串 | char | ||
| 整数 | byte/short/int/long | smallint/int(n)/bigint(n) | smallint/int/bigint |
| 小数 | float/double/BigDecimal | float/double/money/real | float/double |
| 布尔 | boolean | bit | boolean |
| 日期 | java.util.Date | date/datetime/timestamp | date/timestamp |
| 列表 | HashSet | set(‘V1’,‘V2’,‘V3’,…) | array<data_type> |
6.2、集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的 struct类似,都可以通过 “点 ”符号 访问元素内容 | struct< name:STRING, age:INT> |
| MAP | MAP是 一组键 值对元组集合,使用数组表示法可以访问数据 | map< string, int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些 变量 称为数组的元素,每个数组元素都有一个编号,编号从零开始 | array< INT> |
6.3、隐式转换
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。
