感知器方程公式定义
一般的二维线性分类预测公式:
y hat = W * x + b
一般的三维线性分类预测公式:
y hat = W1 * x1 + W2 * x2 + W3 * x3 + b
如果是n维线性分类预测公式:
y hat = W1 * x1 + W2 * x2 + ... + Wn * xn + b
感知器就是矩阵相乘,并应用S型函数的结果
1.为什么感知器被称作为“神经网络“?
因为感知器结构和大脑神经元的结构很相似
感知器的作用是利用某一方程组对输入进行计算,并决定返回 1 或 0
而大脑神经元从它的多个树突获得输入(这些输入是神经脉冲),所以神经元的作用就是对神经脉冲进行处理,然后判断是否通过轴突输出神经脉冲
所以神经网络中的神经元就是把一个神经元的输出作为另一个神经元的输入
2.感知器的逻辑运算符
AND、OR、NOT 和 XOR
有趣的现象是某些逻辑运算符可以表示为感知器,例如:逻辑与运算(AND)是如何进行的?
AND 感知器,与运算 就是true和true就是true,true和false就是false,false和true就是false,false和false还是false
OR 感知器,或运算 OR 感知器和 AND 感知器很相似,我们可以增大权重,减小偏差就是 OR 感知器
NOT 感知器,非运算 如果是1就返回0,如果是0就返回1
XOR 感知器,异或运算 一个为true,另一个为false
小测试
将权重(weight1、weight2)和偏差 bias 设为正确的值,以便如上所示地计算 AND 运算。
import pandas as pd
# 设置 weight1, weight2, 和 bias
weight1 = 0.0
weight2 = 0.0
bias = 0.0
# 不要修改下面的任何代码
# 这是输入和输出
test_inputs = [(0, 0), (0, 1), (1, 0), (1, 1)]
correct_outputs = [False, False, False, True]
outputs = []
for test_input, correct_output in zip(test_inputs, correct_outputs):
linear_combination = weight1 * test_input[0] + weight2 * test_input[1] + bias
print(linear_combination)
output = int(linear_combination >= 0)
is_correct_string = 'Yes' if output == correct_output else 'No'
outputs.append([test_input[0], test_input[1], linear_combination, output, is_correct_string])
print(outputs)
# Print output
num_wrong = len([output[4] for output in outputs if output[4] == 'No'])
output_frame = pd.DataFrame(outputs, columns=['Input 1', ' Input 2', ' Linear Combination', ' Activation Output', ' Is Correct'])
print(num_wrong)
if not num_wrong:
print('太棒了! 你已经掌握了如何设置权重和偏差.\n')
else:
print('错了 {} 个. 继续努力!\n'.format(num_wrong))
print(output_frame.to_string(index=False))答案是:
weight1 = 1.0
weight2 = 1.0
bias = -2感知器算法视频
参考视频:https://www.youtube.com/embed/M9c9bN5nJ3U
import numpy as np
# Setting the random seed, feel free to change it and see different solutions.
np.random.seed(12)
def stepFunction(t):
if t >= 0:
return 1
return 0
def prediction(X, W, b):
return stepFunction((np.matmul(X,W)+b)[0])
# TODO: Fill in the code below to implement the perceptron trick.
# The function should receive as inputs the data X, the labels y,
# the weights W (as an array), and the bias b,
# update the weights and bias W, b, according to the perceptron algorithm,
# and return W and b.
def perceptronStep(X, y, W, b, learn_rate = 0.01):
for i in range(len(X)):
y_hat = prediction(X[i],W,b)
if y[i]-y_hat == 1:
W[0] += X[i][0]*learn_rate
W[1] += X[i][1]*learn_rate
b += learn_rate
elif y[i]-y_hat == -1:
W[0] -= X[i][0]*learn_rate
W[1] -= X[i][1]*learn_rate
b -= learn_rate
return W, b
# This function runs the perceptron algorithm repeatedly on the dataset,
# and returns a few of the boundary lines obtained in the iterations,
# for plotting purposes.
# Feel free to play with the learning rate and the num_epochs,
# and see your results plotted below.
def trainPerceptronAlgorithm(X, y, learn_rate = 0.01, num_epochs = 25):
x_min, x_max = min(X.T[0]), max(X.T[0])
y_min, y_max = min(X.T[1]), max(X.T[1])
W = np.array(np.random.rand(2,1))
b = np.random.rand(1)[0] + x_max
# These are the solution lines that get plotted below.
boundary_lines = []
for i in range(num_epochs):
# In each epoch, we apply the perceptron step.
W, b = perceptronStep(X, y, W, b, learn_rate)
boundary_lines.append((-W[0]/W[1], -b/W[1]))
return boundary_lines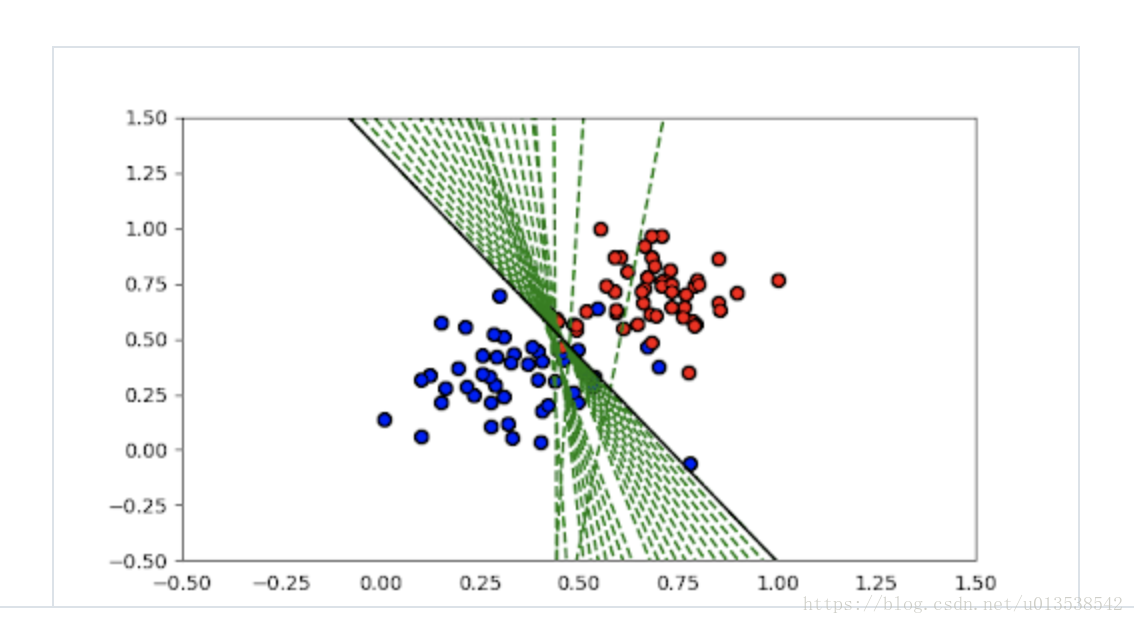
3.非线性数据
- 一条直线能完好分割的数据,就是线性的
- 如果一条直线不能完好分割的数据,就是非线性的
在非线性的数据里,我们需要借助误差函数(Error Function)来达到目的,误差函数越小,离目标越近。
对于优化而言,连续性误差函数比离散型误差函数更好。
那如果将离散型误差函数转变成连续性误差函数了?
- 1.离散性 可以用 0或1来表示,y = 1 if x >= 0 else 0
- 2.连续性 可以用 概率 来表示,sigmoid 函数,公式为: y = 1 / (1 + exp(-x))
- 3.对于离散性的激活函数,我们用 阶跃函数(Step Function) ,step(Wx + b)
- 4.对于连续性激活函数,我们用 S 函数,Sigmoid(Wx + b)
参考视频:https://www.youtube.com/embed/Rm2KxFaPiJg
4.多类别分类和softmax
对于之前的二分类问题,我们得到的结果要么是1,要么是0。但是如果我们希望有多个类别了?比如:结果是黄色,绿色,还是蓝色?猫,狗,还是老虎?
指数 (exp) 就是对数字进行平方运算,所以结果始终为正数
那如果有多个类别,各自的数字不一样,比如:1,2,3,那如何让他们的概率加起来等于1了?
公式就是:
概率1 = exp(1) / (exp(1) + exp(2) + exp(3))
概率2 = exp(2) / (exp(1) + exp(2) + exp(3))
概率3 = exp(3) / (exp(1) + exp(2) + exp(3))
softmax的公式函数
import numpy as np
def softmax(L):
expl = np.exp(L) # 将L数组里的所有元素的值都进行指数运算
sumExpl = sum(expl) # 对expl数组求和
result = []
for i in expl:
result.append(i * 1.0 / sumExpl) # 计算数组里每个元素的概率值
return result另外,维基百科里有更简单的写法,参考链接:https://en.wikipedia.org/wiki/Softmax_function
>>> import numpy as np
>>> z = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0]
>>> softmax = lambda x : np.exp(x)/np.sum(np.exp(x))
>>> softmax(z)5.One-Hot Encoding
什么是One-Hot Encoding
在数字电路的一组比特中,合法的组合值高位是1,低位是0
参考One-Hot
为什么要使用One-Hot Encoding
在机器学习领域,为了ML算法更好的运算,我们会将输入都转换成One-Hot Encoding,那就意味着,所有的输入都是1或者0,那么对于两个类别表示起来就简单了。
比如:你收到礼物就是1,没有收到就是0。
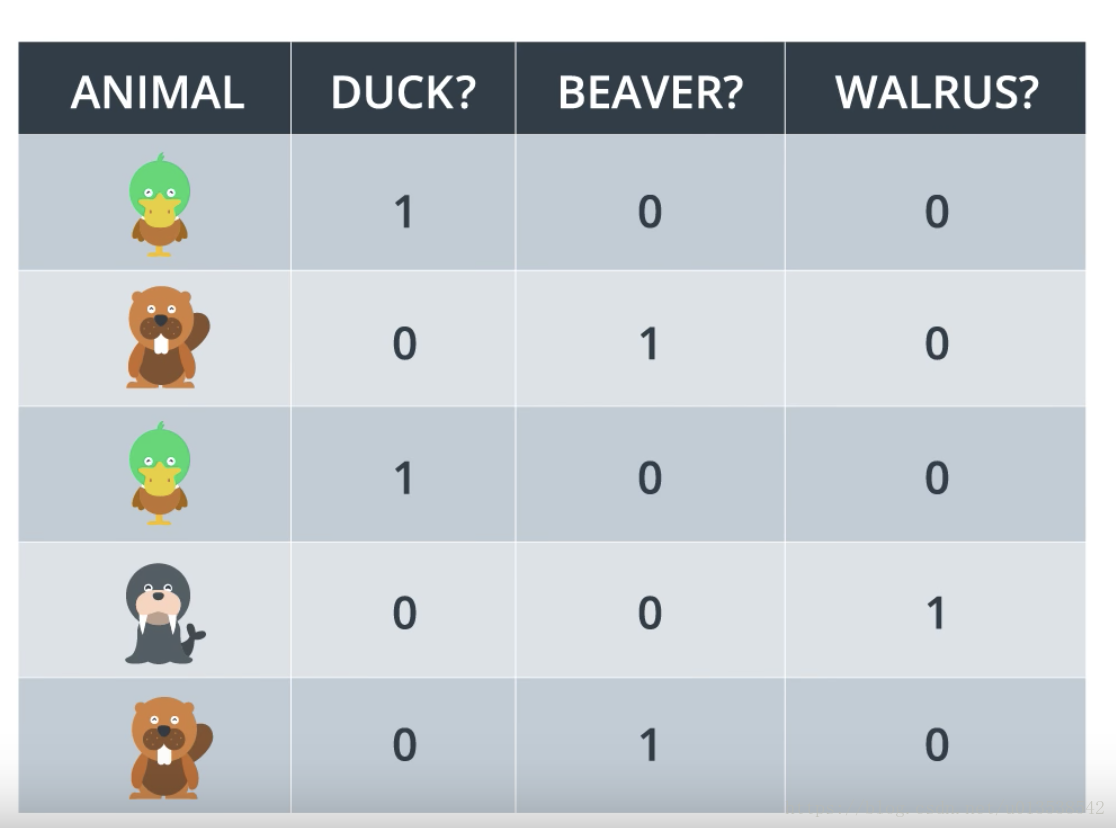
但是,假如有多个类别,有鸭子,海象,海狸,对这样的多类别进行One-Hot Encoding处理,那如何做了?如图所示,就是对每个类别分开分类,形成矩阵,然后对自己就是1,对别的类别就是0
6.最大似然数 Maximum Likelihood
概率(probability)对于深度学习来说,非常重要。
对于一个好的模型来说,最大化概率,也就会最小化误差函数,这样离预测目标就更近。
对于计算概率来讲,使用对数(log)是通常是非常好的选择。即:log(ab) = log(a) + log(b)
在这里,我们要使用底数为e的对数(自然对数),而不是底数为10的对数
7.交叉熵 Cross Entropy
求概率的对数是负值,对它取相反数就会得到正数,最后对它们的相反数求和,就是交叉熵。
简单地说:就是对对数的负数求和,就是交叉熵。

比如,模型A和模型B的交叉熵:
模型A 0.51 + 1.61 + 2.3 + 0.36 = 4.78
模型B 0.36 + 0.1 + 0.22 + 0.51 = 1.19
事实证明模型B的交叉熵较小。 越准确的模型可以得到较低的交叉熵
误差较大的模型得到的交叉熵较高,反之,误差较小的模型得到的交叉熵较小(模型就越优)
这是因为,好模型有较高的概率,反之亦然。
所以,交叉熵可以告诉我们模型的好坏。
现在,我们的目标是,使最大化概率变为最小化交叉熵
我们得到的规律就是:概率和误差函数之间肯定有一定的联系,这种联系就叫做交叉熵。
交叉熵公式:
import numpy as np
# Write a function that takes as input two lists Y, P,
# and returns the float corresponding to their cross-entropy.
def cross_entropy(Y, P):
Y = np.float_(Y)
P = np.float_(P)
return -np.sum(Y * np.log(P) + (1 - Y) * np.log(1 - P))多类别交叉熵 Multi-Class Cross Entropy
8.Logistic回归
在机器学习领域中,最有用的、最热门的基石算法之一:对数几率回归 算法
基本上是这样的:
- 获取数据
- 选择一个随机模型
- 计算误差
- 最小化误差,获得更好的模型
- 完成
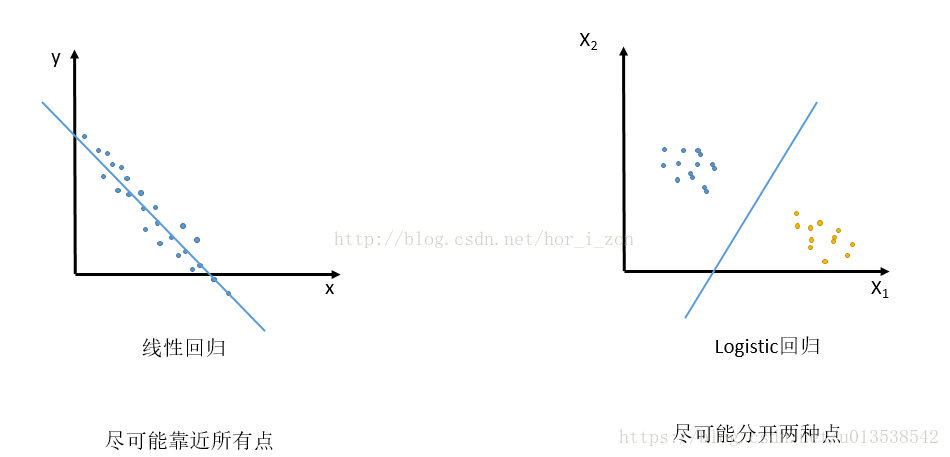
* 注意 *
- 1.线性回归是尽可能靠近所有的点
- 2.logistic回归是尽可能分开两种点
9.梯度下降算法
# 激活 (sigmoid) 函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 输出 (prediction) 公式
def output_formula(features, weights, bias):
return sigmoid(np.matmul(features, weights) + bias)
# Error (log-loss) 公式
def error_formula(y, output):
return - y*np.log(output) - (1 - y) * np.log(1-output)
# Gradient descent step 梯度下降步数,也就是更新权重
def update_weights(x, y, weights, bias, learnrate):
output = output_formula(x, weights, bias)
d_error = -(y - output)
weights -= learnrate * d_error * x
bias -= learnrate * d_error
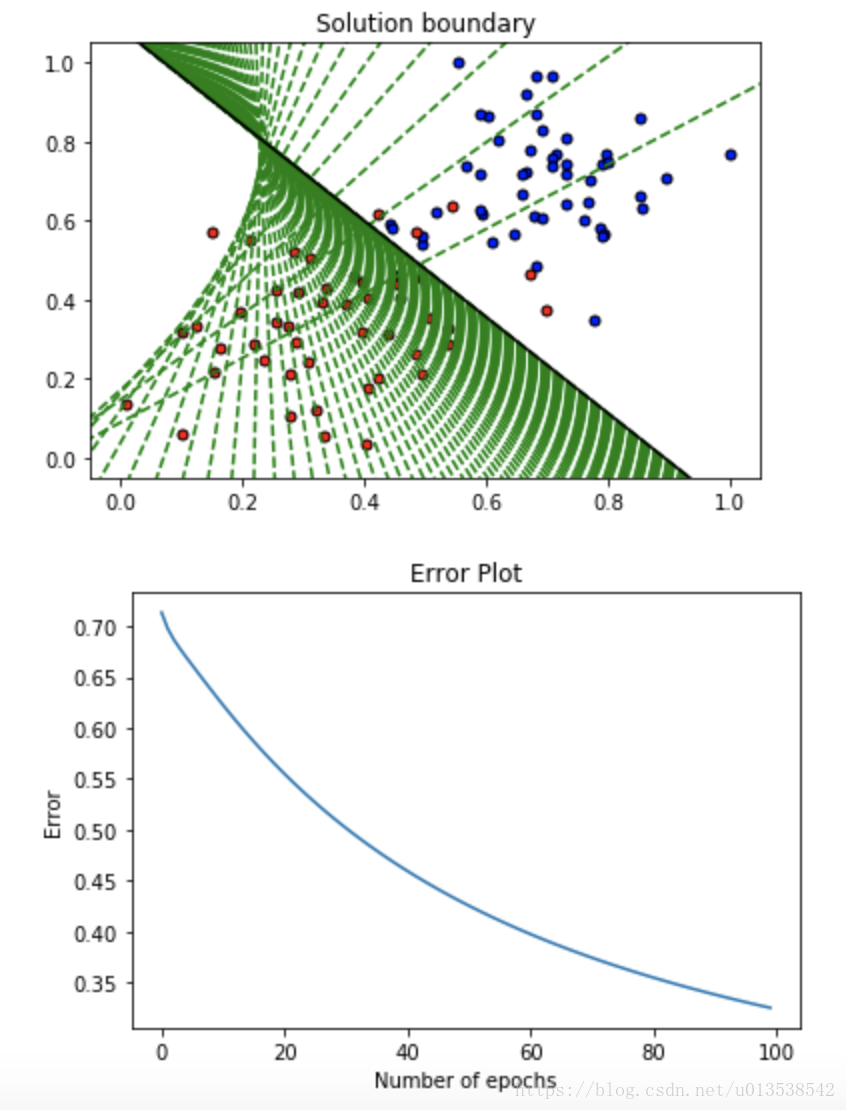
return weights, bias感知器(perceptron)算法与梯度下降(gradient descent)算法的区别:
1.在感知器算法中,并非每个点都会更改权重,只有分类错误的点才会
2.在感知器算法中,y hat只能是1或者0;而在梯度下降算法中,y hat 可以是0到1之间的值
3.在梯度下降算法中,一次预测被正确分类的点会更改权重,让分类直线离这个点远点,而分类错误的点也会更改权重,让分类直线离这个点更近些
如图,在 epochs=100 的情况下,看看直线的预测(移动)过程
看 Github代码 演示
10.神经网络架构
现在我们可以将这些构建基石组合到一起,并构建出色的神经网络。(神经网络也可以称之为多层感知器)
之前的都是线性的分类,现在我们对现有的线性模型进行线性组合,得到更复杂的新模型,使之成为非线性模型,如图:
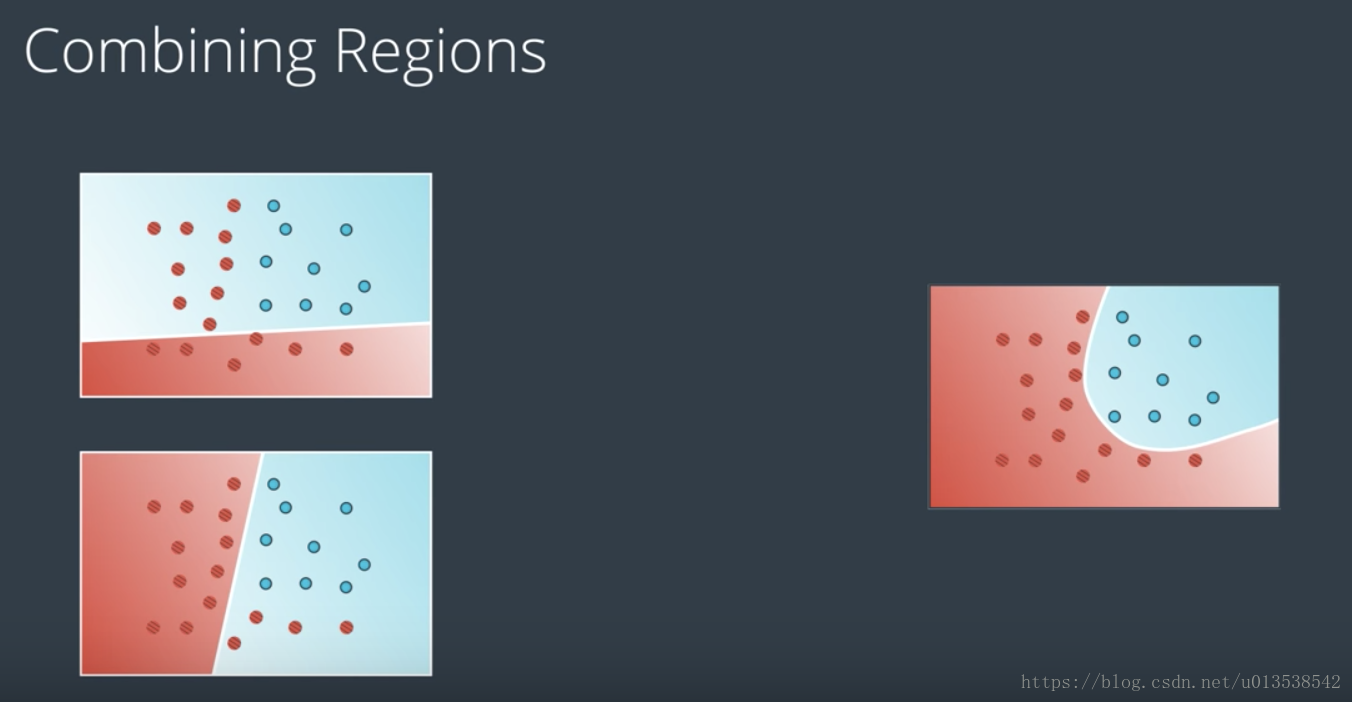
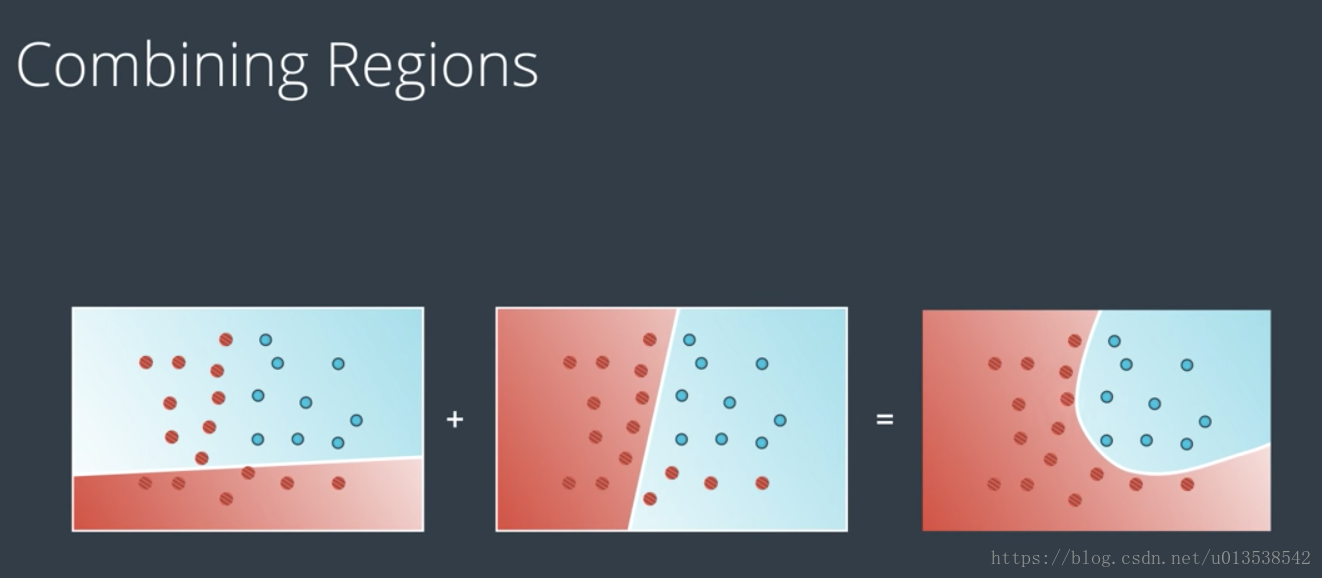
当多个线性模型叠加计算时,每个点得出的结果基本都会大于1,但是对于概率来说,我们的点,必须在0到1之间,此时,我们的做法是将叠加计算的结果(大于1的值)转换成0到1之间的概率,就需要用到上面所讲到的 sigmoid 函数。
通常我们会将线性模型组合到一起,形成非线性模型,然后我们再将这些非线性模型进一步组合,形成更多的非线性模型,随着更多的组合,就会更多的非线性模型,这就是深度神经网络。在深度神经网络中,这些中间的巨大的非线性模型就是隐藏层。
神经网络使用高度非线性化的边界,拆分整个n维空间。
神经网络的多类别分类
之前的神经网络,我们预测的结果都是一个值。那假如,我们需要预测多个值,该怎么做了?
答案很简单,就是在输出层添加多个节点 ,每个节点都会告诉我们预测(输出)的结果对应的label 的得分是多少,然后通过 softmax函数 得到每个类别的概率,这就是神经网络进行多类别分类的方法。(softmax函数就是对多类别分类来计算概率的)
11.前向反馈 Feedforward
前向反馈是神经网络用来将输入变成输出的流程,也就是将一个输出变成下一个输入,一次类推,直到最后一个输出的流程。
训练神经网络,实际上就是各边的权重是多少, 才能很好的对数据建模
12.反向传播 Backpropagation
我们将要训练神经网络,就需要使用 反向传播,反向传播的流程是:
- 1.进行
前向反馈运算 - 2.将
模型的输出与期望的输出进行比较 - 3.计算
误差 - 4.
向后运行前向反馈运算(反向传播),将误差分散到每个权重上 - 5.
更新权重,并获得更好的模型 - 6.继续此流程,直到获得很好的模型
def error_term_formula(y, output):
return (y-output) * output * (1 - output)* 反向传播正好是前向反馈的逆过程 *
13.平均平方误差
平均平方误差,可以表示预测值和标签值的差的平方的平均值
学习权重
使用感知器来构建AND, OR, NOT 或 XOR运算,它们的权重都是人为设定的;那如果你要预测大学录取结果,但你又不知道权重是多少,怎么办?这就需要从样本中学习权重,然后用这些权重来做预测。
预测指标
对于模型预测的有多坏,或多好?我们可以使用 误差 这个 指标 来 衡量。一个普遍的指标是误差平方和(sum of the squared error 亦称作SSE)
误差平方和,可以用于衡量神经网络的预测效果;值越低,效果越好。
现在假设只有一个输出单元,以下就是运行代码的步骤,本次还是用sigmoid函数作为激活函数
# Defining the sigmoid function for activations
# 定义 sigmoid 激活函数,用来计算隐藏层的输出值
def sigmoid(x):
return 1/(1+np.exp(-x))
# Derivative of the sigmoid function
# 激活函数的导数,用来计算梯度下降的输出值
def sigmoid_prime(x):
return sigmoid(x) * (1 - sigmoid(x))
# Input data
# 输入数据
x = np.array([0.1, 0.3])
# Target
# 目标
y = 0.2
# Input to output weights
# 输入到输出的权重
weights = np.array([-0.8, 0.5])
# The learning rate, eta in the weight step equation
# 权重更新的学习率
learnrate = 0.5
# the linear combination performed by the node (h in f(h) and f'(h))
# 输入和权重的线性组合
h = x[0]*weights[0] + x[1]*weights[1]
# or h = np.dot(x, weights)
# The neural network output (y-hat)
# 神经网络输出
nn_output = sigmoid(h)
# output error (y - y-hat)
# 输出误差
error = y - nn_output
# output gradient (f'(h))
# 输出梯度
output_grad = sigmoid_prime(h)
# error term (lowercase delta)
error_term = error * output_grad
# Gradient descent step
# 梯度下降一步
del_w = [ learnrate * error_term * x[0],
learnrate * error_term * x[1]]
# or del_w = learnrate * error_term * x
print('Neural Network output:')
print(nn_output)
print('Amount of Error:')
print(error)
print('Change in Weights:')
print(del_w)关键符号
预测值 y hat
真实值 y
参考:
感知器算法: https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/
非线性模型: https://www.youtube.com/embed/Boy3zHVrWB4
https://www.youtube.com/embed/au-Wxkr_skM
神经网络多层级结构:https://www.youtube.com/embed/pg99FkXYK0M
神经网络多类别分类:https://www.youtube.com/embed/uNTtvxwfox0
前向反馈:https://www.youtube.com/embed/Ioe3bwMgjAM
反向传播:
多元微积分:https://www.khanacademy.org/math/multivariable-calculus