在这里插入图片描述
由于 CPU 的 运算速度远远 大于 Main Memory 主存的速度,所以要 使用一个 Cache 来进行缓存
cpu和 内存
最早的时候 单核 CPU 是这种方法
多核CPU的 3级缓存
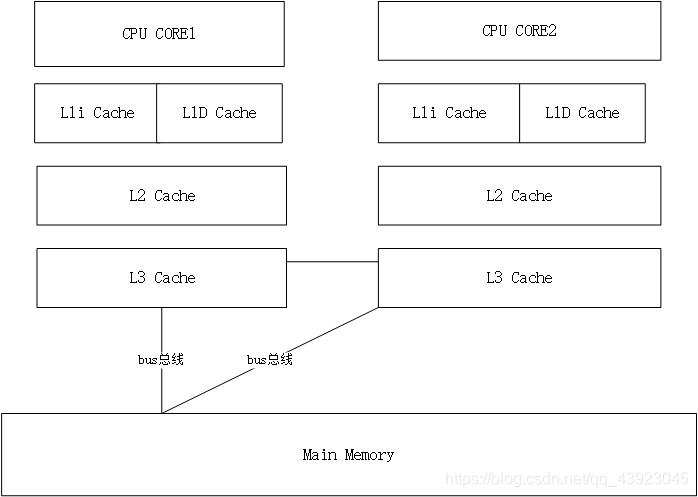
CPU 的缓存分 L1,L2,L3, 他们比内存快,但是贵,只能用作高速缓存,CPU 查找数据的时候先去 L1, 然后去看L2,如果没有就去内存,还有些机器带了 L3 cache,多一级也是为了提高速度
高速缓存器 Cache 是位于 CPU core 和内存将的寄存器,容量比内存小,但是交换速度快,用于缓存CPU 内短时间即将访问到的小数据。CPU 中加入 Cache 这样整个内存储器(cache+内存) 就兼具了 Cache的高速 和 内存的大容量的优点。而Cache 对 CPU 性能的影响主要因为 CPU 的数据交换顺序和 CPU cache间的带宽决定
CPU的处理能力要远比内存强,主内存执行一次内存读、写操作的时间可能足够处理器执行上百条的指令。为了弥补处理器与内存处理能力之间的鸿沟,在内存和处理器之间引入了高速缓存(Cache)。高速缓存是一种存取速率远比主内存大而容量远比主内存小的存储部件,每个处理器都有其高速缓存
但是这里就会出现一个 内存可见性的 问题了
比如 主内存中有一个 int i = 0, 那么这里两个 cache ,一个线程在 cache中 给 i 的值 +100, 而由于 cache中保存的 只是 i的副本,其实并没有写回主内存,假设这个线程是在 左边的那个 cache 操作,而 又一个线程去右边的 那个 cache 去读 这个 i, 他只能读到 i 的值 为 0
总线锁和缓存锁
为了解决这个问题 intel 和 amd推出了一种协议
缓存一致性协议(MESI)
下面是缓存锁
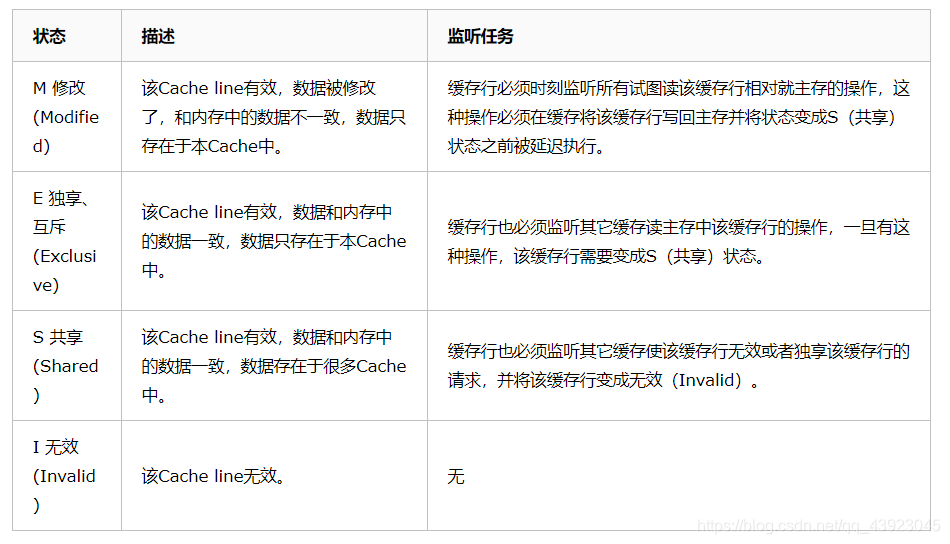
现在 Intel 的 i7处理器 和 AMD 的处理器 都是在这种协议上做了相关的扩充,已经不是用这种最原始的方法。
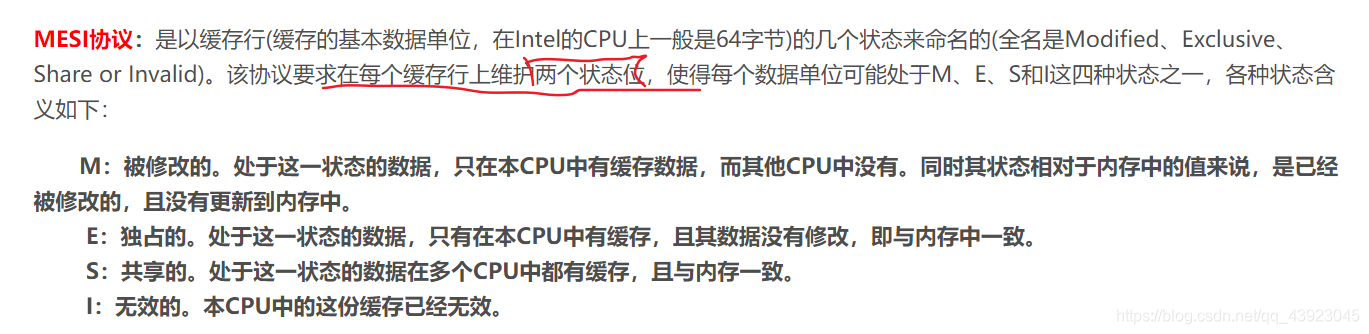
简单来说 就是在数据上打个标记
前端总线(也叫CPU总线)是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号、通过地址总线发送地址信号指定其要访问的部件、通过数据总线双向传输。在CPU1要做 i++操作的时候,其在总线上发出一个LOCK#信号,其他处理器就不能操作缓存了该共享变量内存地址的缓存,也就是阻塞了其他CPU,使该处理器可以独享此共享内存。
总线锁定把CPU和内存的通信给锁住了,使得在锁定期间,其他处理器不能操作其他内存地址的数据,从而开销较大,所以后来的CPU都提供了缓存一致性机制,Intel的奔腾486之后就提供了这种优化。
总线锁:就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
缓存锁:所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行数据时,会使缓存行无效。
