一、概述
Java 内存模型(Java Memory Model)描述了一组规则或规范,定义了 JVM 将变量存储到内存和从内存中取出变量这样的底层细节,值得注意的是,这里的变量指的是共享变量(实例字段、静态字段、数组对象元素),不包括线程私有变量(局部变量、方法参数),因为私有变量不会存在竞争关系。
二、JMM 图解
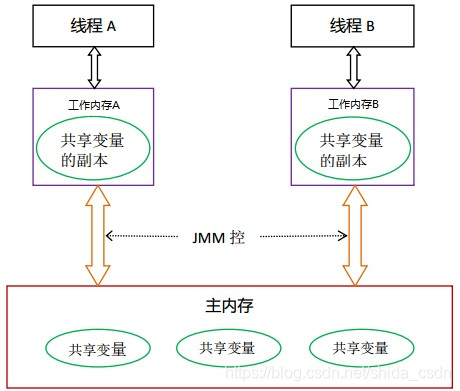
在 JMM 中,线程直接读写的并不是主内存,而是一份自己独享的工作内存(工作内存中存放着共享变量的副本)。为什么要这么做呢?这要从现代计算机的构成说起。我们知道,CPU 与 内存之间存在的速度差异是比较大的,为了缩短这种差距,提高 CPU 的利用率,在计算机体系结构中普遍引入了缓存的概念。而 Java 的线程本质上就是操作系统中的线程(JVM 其实是通过系统调用将程序的线程交给了操作系统内核进行调度),因此其内存模型也就要遵从现代操作系统所使用的 “CPU <--> 缓存 <--> 内存 ” 工作模式了。特别是当处理器是多核的时候,Java 线程可能是在不同的处理器上分别执行的。简单来说,JMM 中的工作内存对应到底层硬件其实就是 CPU 的高速缓存了。
在 JMM 中,工作内存是线程私有的,不同线程之间的变量的传递必须通过主内存。
我们可以通过下边这幅图,与计算机系统简单对应一下:
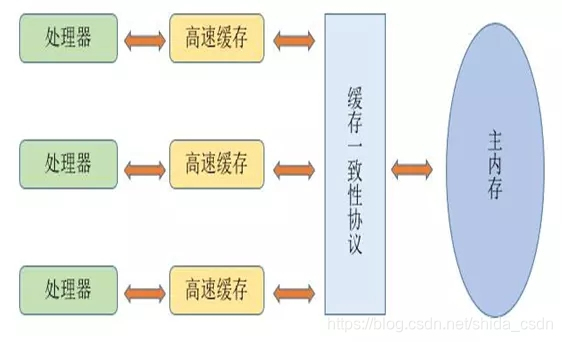
- 处理器对应到线程(想象每个处理器运行了一个 Java 线程);
- 高速缓存就是线程的本地工作内存;
- 缓存一致性协议就是 JVM 、操作系统等的内存管理;
- 主内存就不用多说了,就是计算机内存;
三、JMM 带来的问题
我们知道,不同处理器的高速缓存之间是相互隔离的,只能通过主内存通信。当其中一个处理器修改了高速缓存的内容,而修改结果并没有及时同步到主内存,其他处理器读取的将仍然是老的缓存数据,结果就会出现数据的不一致。因此,高速缓存中的数据何时回写是非常关键的。这里,我们不必过多关注高速缓存内容回写后,其他高速缓存的数据同步更新,因为这可以通过处理器系统的缓存一致性协议来保证(缓存一致性协议发现主内存的数据被更新后,会自动将引用该主内存旧数据的高速缓存设置为失效,就会触发高速缓存的数据重读)。
在多线程环境中,如果线程间存在共享数据,为了保证共享数据在不同线程间的可见性,就必须保证数据被修改后能够立即被回写到内存,关键字 volatile 其中一个作用正是这个。如果不用 volatile 关键字修饰共享变量,那么共享变量被更新后的数据回写时机也就不确定了(也许立马就回写了,但更多是过段时间才会同步到主内存),如果这时候其他线程也在更新该共享变量,两个线程彼此都看不到最新的共享变量结果,都基于旧数据计算,那最后回写到内存的数据将会是不正确的。

JMM 的工作方式显然带来了不同线程间共享变量的可见性问题。
四、volatile 修饰变量的数据可见性
使用 volatile 修饰的变量,JVM 执行时会为其添加内存屏障。
那么,什么是内存屏障呢?它是一种硬件层次的概念了,不同的硬件平台实现内存屏障的手段并不相同,JVM 会根据平台的不同通过不同的系统调用来设置内存屏障。 硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。
内存屏障的主要作用有两个:
- 阻止屏障两侧的指令重排序;
- 强制把写缓冲区/高速缓存中的更新数据写回主内存,让缓存中相应的数据失效
- 对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制重新从主内存加载数据;
- 对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据立即写入主内存,让其他线程可见;
JMM 内存屏障通常有四种:
- LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕;
- StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见;
- LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被执行前,保证Load1要读取的数据被读取完毕;
- StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见;
StoreLoad 屏障的开销是四种屏障中最大的,在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。volatile 所使用的正是 StoreLoad 内存屏障。
因此使用了 volatile 关键字修饰的共享变量,在线程读取前,如果有其他线程已经修改了该变量的值到其工作内存,会先将新数据刷写到主内存,刷写完毕后其他线程才能进行读取。也就是每次读取共享变量的时候,系统都要先检查一下要不要刷新主内存的问题,自然就做到了共享变量在不同线程的可见性了。
四、volatile 防止指令重排
在第三节我们提到,内存屏障除了能够控制内存与缓存之间数据同步的时机,而且还有一个重要功能,那就是防止指令重排序。什么是指令重排序呢?举一个简单的例子:
在线程A中:
context = loadContext(); // 初始化 context 变量
inited = true; // 初始化完毕,设置 inited 为 true,通知线程 B 使用 context
在线程B中:
// 根据线程 A 对 inited 变量的修改决定是否使用 context 变量
while(!inited ){
sleep(100);
}
doSomethingwithconfig(context);
由于线程 A 中的两个赋值语句是没有关联的,因此很可能发生指令重排。假设线程 A 发生了指令重排:
inited = true;
context = loadContext();
显然,线程 A 在将 inited 设置为 true 时,context 还未被初始化,会导致线程 B 使用到错误的 context 变量。
在这种情况下,inited 变量其实是应该被 volatile 修饰的,volatile 会组织 JVM 对指令的重排序。
因此,开发建议是多线程共享的变量最好使用 volatile 修饰。