问题
- 高并发情况下Java内存模型是怎样提供支持的?
- new出一个对象后,它在内存中是怎样布局的?
硬件层的并发优化基础知识
硬件数据一致性
老的CPU使用总线锁来实现。总线锁在多CPU的情况下效率低,所以发展出了缓存一致性协议,协议非常多,intel用MESI协议(【并发编程】MESI–CPU缓存一致性协议),缓存锁的效率会比总线锁快但是在一些问题中无法解决时还是需要总线锁来保证数据一致性。比如(数据在多级缓存中时,数据量过大无法读取到CPU缓存中时)
所以现在的CPU的数据一致性实现 = 缓存锁(MESI等数据一致性协议)+总线锁
缓存行 cache Line
CPU运算时读取缓存以缓存行(cache Line)为基本单位,一般为64bytes一个缓存行
缓存行伪共享
位于同一缓存行的两个不同数据,被两个CPU锁定,产生互相影响的情况
可以采用缓存行对齐,来避免缓存行伪共享(会牺牲缓存空间来换取效率)
乱序问题
执行读指令等待期间可以同时执行不影响的其他指令
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读取数据时(速度比执行指令慢很多,将近100倍)),去同时执行另外一条指令,前提是两条指令没有依赖关系(a=8,b=a)

执行写指令时可以进行合并写
CPU计算完之后将数据写或缓存时,如果同时有其他的写指令一起,会将数据合并在一起返回缓存
每个CPU中只有4个字节WriteCombineBuffer空间。
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
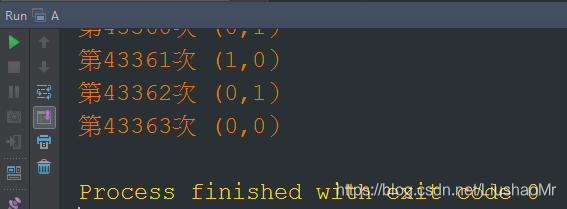
乱序执行(指令重排)的证明
如果不存在乱序执行。则如下代码不会打印出第i次(0,0)
因为在执行 x=b或y=a之前,必定先执行过a=1或者b=1,所以不出现乱序执行则只会出现 [0,1],[1,0],[1,1]这三种情况
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
如何保证特定情况下不乱序(有序性保障)
java中使用volatile(lock汇编指令)提供有序性保障
硬件层面使用CPU内存屏障(汇编指令)来实现有序性保障
sfence: sava fence 在sfence指令前的写操作完成后,sfence指令后的写操作才能开始
lfence: load fence 在lfence指令前的读操作完成后,lfence指令后的读操作才能开始
mfence: mix fence 在mfence指令前的读写操作完成后,mfence指令后的读写操作才能开始
原子指令,如X86上的“lock [add]...”指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,
甚至跨多个CPU。software Locks 通常使用了内存屏障或原子指令来实现变量可见性和保证循序执行
JVM级别如何规范
JVM内存屏障只是规范,具体实现有JVM自身依赖硬件进行实现
1. LoadLoad 屏障:
语句:Load1;LoadLoad;Load2
在Load2指令或者后续的读取指令操作要读取的数据前,要保证Load1的数据读取操作已经完成
2. StoreStore 屏障:
语句: Store1;StoreStore;Store2
在Store2指令或者后续的写入指令操作要写入的数据前,要保证Store1的数据写入操作已经完成
3. LoadStore 屏障:
语句: Load1;LoadStore;Store2
在Store2指令或者后续的写入指令操作要写入的数据前,要保证Load1的数据读取操作已经完成
4. StoreLoad 屏障:
语句: Store1;StoreLoad;Load2
在Load2指令或者后续的读取指令操作要读取的数据前,保证Store1的写入对所有所有处理器可见。
它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令
volatile的实现细节
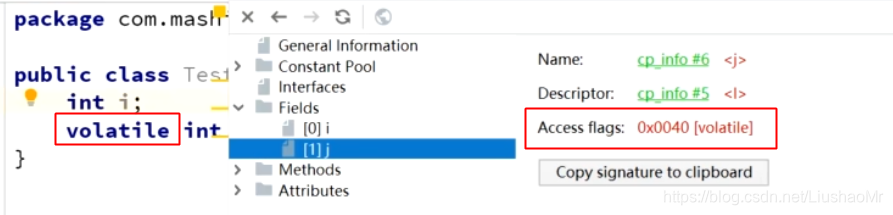
字节码层面
只是在属性前增加了一个访问修饰符 ACC_VOLATILE
JVM层面
volatile内存区的读写操作前后都加屏障
写操作前加了StoreStore屏障,后面加了StoreLoad屏障
读操作前加了LoadLoad屏障,后面加了LoadStore屏障

OS和硬件层面
[volatile与lock前缀指令](https://blog.csdn.net/qq_26222859/article/details/52235930)
hsdis - HotSpot Dis Assembler(JVM反汇编工具)
windows 中使用lock指令实现
synchromized的实现细节
字节码层面
方法:在方法前增加 ACC_SYNCHROMIZED的访问修饰符
同步语句块:会在同步块的入口位置和退出位置分别插入monitorenter和monitorexit字节码指令。
JVM层面
C、C++ 调用操作系统提供的同步机制
OS和硬件层面
X86: lock comxchg xxxx
