目录:
1.介绍
许多组织与Spark一起部署了Alluxio,以提高性能并提高数据可管理性。 Qunar最近在生产中部署了Alluxio,其Spark流作业平均提高了15倍,在高峰时段提高了300倍。他们注意到,某些Spark作业可能会变慢或无法完成,但是使用Alluxio,这些作业可以很快完成。在此博客文章中,我们研究了Alluxio如何帮助Spark更加有效。 Alluxio可以提高Spark作业的性能,帮助Spark作业更可预测地执行,并使多个Spark作业可以共享内存中的相同数据。 以前,我们研究了如何将Alluxio用于Spark RDD。在本文中,我们研究了如何在Alluxio中有效SparkDataFrames。
2.Alluxio和Spark训练
在Alluxio内存中存储Spark DataFrame非常简单,只需要将DataFrame作为文件保存到Alluxio。使用Spark DataFrame write API,这非常简单 。DataFrame通常使用编写为镶木地板文件 df.write.parquet()。将实木复合地板写入Alluxio之后,可以使用从内存中读取 sqlContext.read.parquet()。
为了了解将DataFrames保存到Alluxio与使用Spark缓存相比,我们进行了一些简单的实验。我们使用了单个工作服务器Amazon EC2 r3.2xlarge实例,该实例具有61 GB的内存和8个内核。我们使用Spark 2.0.0和Alluxio 1.2.0的默认配置。我们在节点上以独立模式运行了Spark和Alluxio。对于该实验,我们尝试了不同的缓存Spark DataFrame和在Alluxio中保存DataFrame的方法,并测量了各种技术如何影响性能。我们还更改了数据大小,以显示数据大小如何影响性能。
3.保存数据框
可以使用persist() API 在Spark内存中“保存”或“缓存” Spark DataFrame 。该 persist() API允许将DataFrame保存到不同的存储介质。对于实验,使用以下
Spark存储级别:
这是有关如何使用persist() API 缓存DataFrame的示例 :
df.persist(MEMORY_ONLY)
将DataFrame保存到内存的另一种方法是将DataFrame作为文件写入Alluxio。Spark支持将DataFrames写入几种不同的文件格式,但是对于这些实验,我们将DataFrames编写为镶木地板文件。这是一个如何将DataFrame写入Alluxio内存的示例:
df.write.parquet(alluxioFile)
4.在Alluxio中查询“保存的”数据帧
在将DataFrame保存到Spark或Alluxio中之后,应用程序可以将其读取到计算中。在我们的实验中,我们创建了一个带有2个浮点列的示例DataFrame,并且计算是两个列的总和。
当将DataFrame存储在Alluxio中时,在Spark中读取数据就像从Alluxio中读取文件一样简单。这是在Alluxio中读取示例DataFrame的示例。
df = sqlContext.read.parquet(alluxioFile)
df.agg(sum(“s1”), sum(“s2”)).show()
我们从Alluxio Parquet文件以及各种Spark持久存储级别对DataFrame进行了此聚合,并测量了聚合所花费的时间。下图显示了聚合的完成时间。
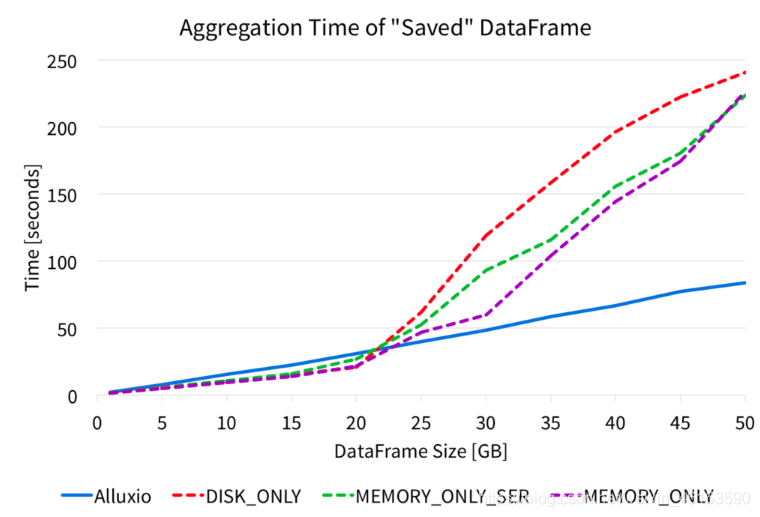
该图显示,对从Alluxio实木复合地板文件读取的DataFrame进行聚合将产生非常可预测和稳定的性能。但是,从Spark缓存读取DataFrame时,对于较小的数据大小,其性能很高,但是较大的数据大小会严重损害性能。对于各种Spark存储级别,大约20GB的输入数据后,聚合速度会减慢并显着增加。
使用Alluxio内存时,对于较小的数据大小,DataFrame聚合性能比Spark内存稍慢,但是随着数据大小的增长,从Alluxio性能中读取数据会更好,因为它随数据大小线性扩展。由于性能是线性扩展的,因此应用程序可以使用Alluxio以内存速度处理更大的数据量。
5. 与Alluxio共享“保存的” DataFrame
即使在不同的Spark作业之间,Alluxio也可以共享内存中的数据。将文件写入Alluxio之后,可以通过Alluxio的内存在不同的作业,上下文甚至框架之间共享同一文件。因此,如果许多应用程序经常访问Alluxio中的DataFrame,则所有应用程序都可以从内存中的Alluxio文件读取数据,而不必重新计算数据或从外部源获取数据。
为了证明Alluxio在内存中的共享优势,我们在如上所述的相同环境中计算了相同的DataFrame聚合。数据大小为50GB时,我们在单独的Spark应用程序中运行了聚合,并测量了执行计算所需的时间。没有Alluxio,Spark应用程序必须从源中读取数据,源是本实验中的本地SSD。但是,当将Spark与Alluxio一起使用时,读取数据意味着从Alluxio内存中读取数据。以下是聚合完成时间的结果。


没有Alluxio,Spark必须再次从源(本地SSD)读取数据。由于从内存中读取数据,因此从Alluxio读取数据的速度更快。使用Alluxio,聚合速度提高了2.5倍以上。
在先前的实验中,数据源是本地SSD。但是,如果DataFrame的来源较慢或难以预测,则Alluxio的好处将更为显着。例如,Amazon S3是用于存储大量数据的流行系统。以下是当DataFrame的来源来自Amazon S3时的结果。
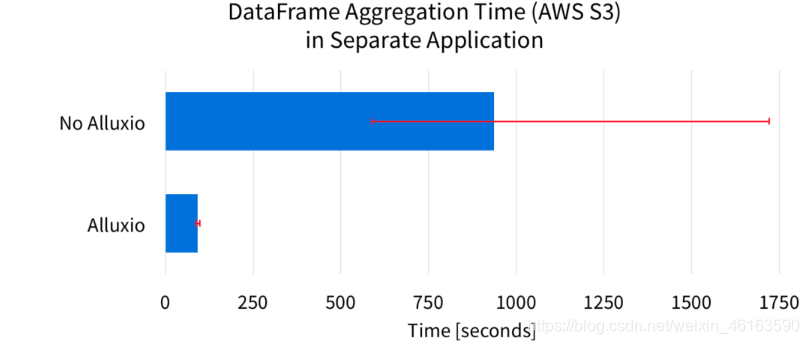
该图显示了7次运行的平均聚合完成时间。图中的误差线表示完成时间的最小和最大范围。这些结果清楚地表明,Alluxio显着提高了计算的平均性能。这是因为使用Alluxio,Spark可以直接从Alluxio内存中读取DataFrame,而无需再次从S3中获取数据。平均而言,Alluxio将DataFrame计算速度提高了10倍以上。
由于数据源是Amazon S3,因此没有Alluxio的Spark必须通过网络获取数据,这可能会导致性能无法预测。从图中的误差条可以明显看出这种不稳定的性能。如果没有Alluxio,Spark作业的完成时间会相差1100多秒。使用Alluxio,完成时间仅相差10秒。Alluxio将不可预测性降低了100倍以上!
由于S3网络的不可预测性,没有Alluxio的最慢Spark运行可能需要长达1700秒以上的时间,几乎是平均速度的两倍。另一方面,Alluxio运行最慢的Spark比平均时间慢约6秒。通过考虑最慢的运行速度,Alluxio将DataFrame聚合速度提高了17倍以上。
6. 结论
Alluxio通过实现以下几项好处来帮助Spark更加有效。该博客演示了如何将Alluxio与Spark DataFrames一起使用,并对性能进行了性能评估。
- Alluxio可以在内存中保留更大的数据大小以加速Spark应用程序
- Alluxio支持在内存中共享数据
- Alluxio提供稳定且可预测的性能
7.心灵寄语: 虽然现在很难,但努力一定没错。