1. SparkSession
需要使用spark SQL之前需要SparkSession类,可以通过 SparkSession.builder来创建一个SparkSession。如果SparkContext已经存在,SparkSession就会重用它;如果不存在,Spark就会创建一个新的SparkContext。在每一个JVM中只能有一个SparkContext,但是在一个Spark程序中可以有多个SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local") \
.appName("dataframe sql example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
其中appName中的参数为工程的名字,config(key=None, value=None, conf=None),设置一个config选项,使用这种方式设置config选项可以自动的同步到sparkconf中和sparkSession自己的配置中。master中的参数默认是“local”,也可以设置成“local[4]”是在本地4核运行,或者是“spark://master:7077”在一个spark上的单独的集群上运行。
如果已经存在了sparkconf, 可以使用以下方式建立SparkSession
from pyspark.conf import SparkConf
SparkSession.builder.config(conf=SparkConf())下面的方式用于获取一个已经存在的sparkSession或者如果已经存在了一个sparkSession在这个sparkSession的设置的基础上建立一个新的sparkSession.
s1 = SparkSession.builder.config("k1", "v1").getOrCreate()
s1.conf.get("k1") == s1.sparkContext.getConf().get("k1") == "v1"
以上代码会返回True
这种方式首先查看是否有一个有效的全局的SparkSession,如果有则返回这个SparkSession。如果没有一个有效的SparkSession存在,这个方法会新创建一个SparkSession作为一个全局的默认的SparkSession
为了保证已经存在的SparkSession被返回,这个config选项将会应用于已经存在的SparkSession上
s2 = SparkSession.builder.config("k2", "v2").getOrCreate()
s1.conf.get("k1") == s2.conf.get("k1")
s1.conf.get("k2") == s2.conf.get("k2")上述代码会返回True
创建dataframe
可以通过以下方式创建一个dataframe
l = [('Alice', 1)]
spark.createDataFrame(l).collect()
spark.createDataFrame(l, ['name', 'age']).collect()d = [{'name':'Alice', 'age':1}]
spark.createDataFrame(d).collect()读取数据
# 读取文件
dpath = '/Users/huoshirui/Desktop/xyworking/pythonData/dataClean/'
df = spark.read.csv(dpath + 'tengxun_data.csv', header=True)
df返回的结果是一个dataframe
展示dataframe
df.show()查看dataframe中字段类型
df.printSchema()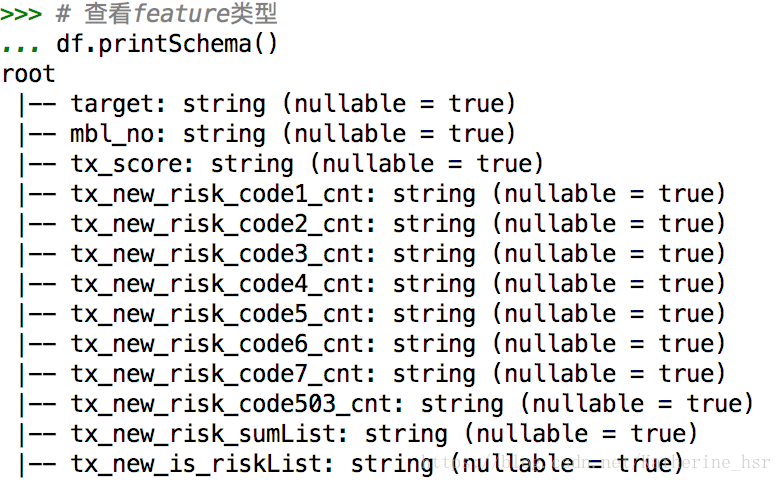
select 操作
df.select(df['target']).show(5)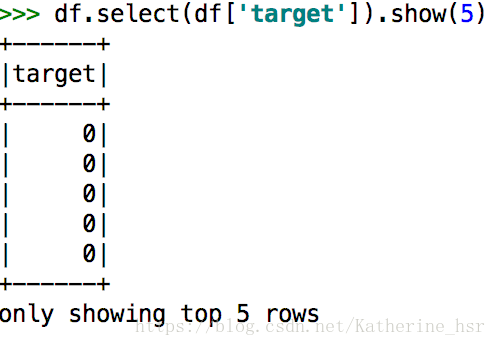
df.select(df['tx_score'], df['target'] + 1).show()
filter操作
df.filter(df['target'] > 0).show(5)groupby操作
df.groupBy(df['target']).count()
创建临时视图
parkSession 的 sql 函数可以让应用程序以编程的方式运行 SQL 查询, 并将结果作为一个 DataFrame 返回
df.createOrReplaceTempView("df")
sqlDF = spark.sql("SELECT target FROM df")
sqlDF.show(5)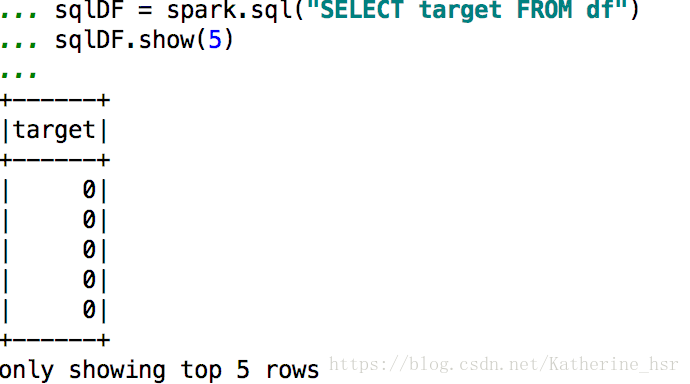
创建全局视图
Spark SQL中的临时视图是session级别的, 也就是会随着session的消失而消失. 如果你想让一个临时视图在所有session中相互传递并且可用,
直到Spark 应用退出, 你可以建立一个全局的临时视图.全局的临时视图存在于系统数据库 global_temp中, 我们必须加上库名去引用它,
比如: SELECT * FROM global_temp.view.
df.createGlobalTempView("df")
sqlGLDF = spark.sql("select target from global_temp.df")
sqlGLDF.show(5)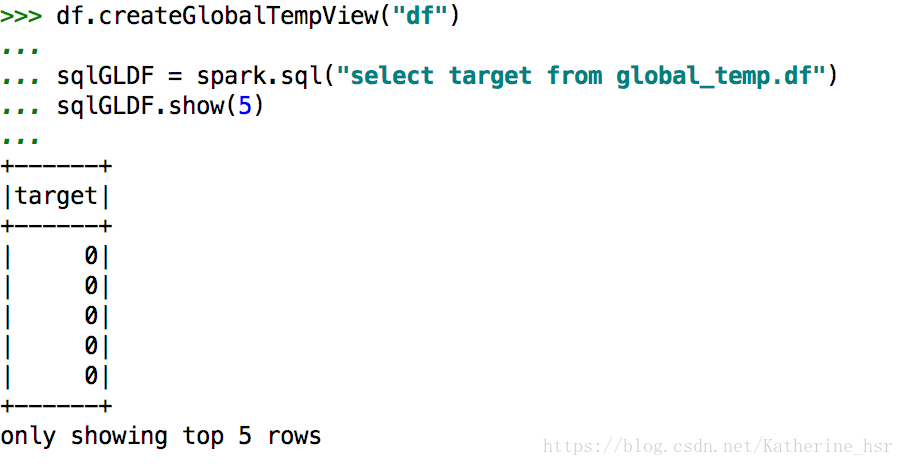
写出文件
df.toPandas().to_csv(path_or_buf = '/Users/huoshirui/Desktop/spark_save_test.csv', index=False)