为何使用pyspark dataframe
使用pandas进行数据处理,dataframe常作为主力军出现。基于单机操作的pandas dataframe是一种表格形数据结构,拥有丰富、灵活、操作简单的api,在数据量不大的情况下有较好的效果。
对于大数据量的运算,分布式计算能突破pandas的瓶颈,而Spark则是分布式计算的典型代表。 Spark中有三类数据api,RDD、DataFrame和Datasets(支持多种主流语言操作),在spark2.0中出现Datasets的概念,其中DataFrame也称Datasets[row],python中只有DataFrame的概念。
DataFrame是基于RDD的一种数据类型,具有比RDD节省空间和更高运算效率的优点,对于使用python操作spark且熟悉pandas基本操作的工作者是一个好消息。
pandas dataframe数据结构特性
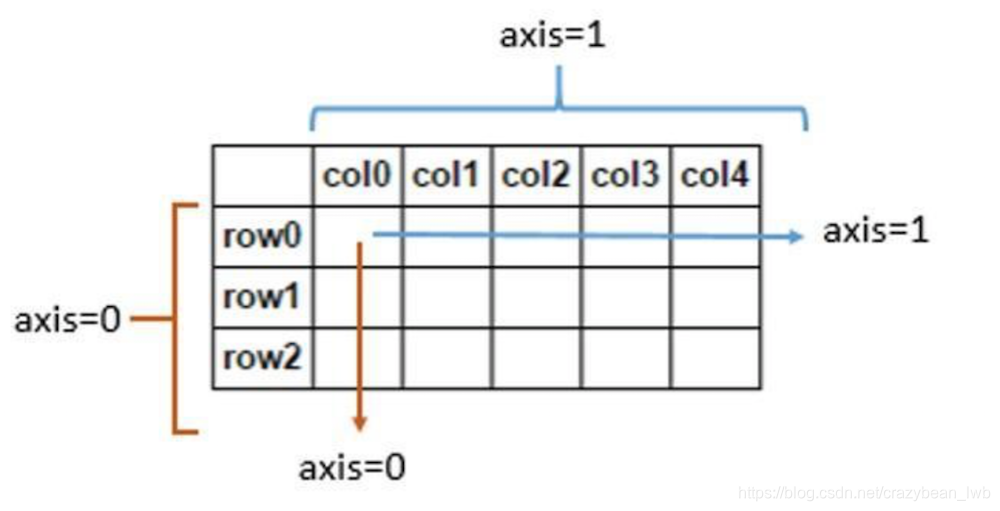
DataFrame是一种表格型数据结构,按照列结构存储,它含有一组有序的列,每列可以是不同的值,但每一列只能有一种数据类型。DataFrame既有行索引,也有列索引,它可以看作是由Series组成的字典,不过这些Series公用一个索引(可以参考下图的数据结构轴线图)。
依赖python这一简洁明了的语言,dataframe操作比较简洁,此外dataframe还拥有比较丰富的操作api接口,能比较容易实现中小型数据集的操作。
spark dataframe结构与存储特性
在Spark中, DataFrame是基于RDD实现的,一个以命名列方式组织的分布式数据集。实际存储与RDD一致,基于行存储,但是Spark框架本身不了解RDD数据的内部结构,而DataFrame却提供了详细的结构信息(Schema),Spark DataFrame将数据以单独表结构,分散在分布式集群的各台机器上,所以spark dataframe是天然的分布式表结构,具体差异可以参考下图。

DataFrame基于RDD的抽象,由于DataFrame具有定义好的结构, Spark可以在作业运行时应用许多性能增强的方法。park对于DataFrame在执行时间和内存使用上相对于RDD有极大的优化。Catalyst优化引擎使执行时间减少75%, Project Tungsten Off-heap 内存管理使内存使用量减少75 +%,无垃圾回收器。使用DataFrame比普通Python RDD实现的快4倍,也达到Scala RDD实现的两倍。经过Catalyst优化后的代码比解释型代码明显快很多。下图给出了DataFrame执行速度和空间上的优势。


spark toPandas详解
Spark DataFrame与Pandas DataFrame结构形式是如此相似,肯定会有使用者思考是否有API能实现二者之间的互相转换。pandas to saprk自不用说,而spark to pandas可以通过toPandas这一api实现。toPandas等效对rdd先做collect然后 to dataframe,是将分布式文件收集导本地的操作,转换后的文件能与pandas一样实现所有操作。使用spark的本意是对海量数据的操作,而转换导本地的pandas操作失去了与其本意相差甚远,所以不建议使用该api。