我们在执行一个可执行文件时,操作系统便为我们创建了一个进程,而我们今天要讲的是从已创建的进程中再创建一个进程,称为当前进程的子进程。子进程有着和父进程一样的代码,数据也同样写时拷贝了一份。
要想创建一个子进程,我们就要学习 fork()/vfork()两个函数。
认识fork函数
函数原型
#include <unistd.h>
pid_t fork(void);
返回值:子进程中返回0,父进程返回子进程id,出错返回-1先来一段演示代码:
int main()
{
pid_t pid = fork();
if(pid < 0)
{
perror("fork");
return 0;
}
else if(pid == 0)
{
//创建的子进程
printf("I am child! My id is %d\n",getpid());
exit(1);
}
//父进程
printf("I am father! My id is %d\n",getpid());
waitpid(pid,NULL,0);//等待子进程退出,回收子进程资源,在后面的进程等待中有详解
return 0;
} 系统在执行 到fork()时,陷入内核去执行fork()代码,操作系统为子进程分配新的内存块和新的内核数据结构,将父进程的部分数据结构以及部分变量拷贝给子进程,也就是说子进程可以和父进程执行一样的工作,也可以单独执行其他工作。之后操作系统将子进程添加到进程表中,fork()返回时,开始调度器调度。
上述代码的运行结果:
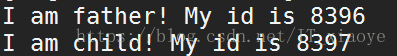
因为子进程是后创建的,所以进程id会小于父进程的进程id。
当我把上面代码中子进程代码部分的exit(1)注释后再编译执行,结果为:

由结果看出,子进程和父进程执行了同样的代码,即I am father!My id is %d这段代码被执行了两次,第二次打印的结果显然是子进程的id,说明子进程和父进程执行同样的工作时,还是具有独立性的。
现在有一个问题,为什么fork()调用成功返回两个值呢?
很好理解,调用fork()函数时,子进程复制了父进程的堆栈段,父进程和子进程此时都停留在fork()处,调用完后,父子进程各收到一个返回值,但是父子进程只共享代码段,数据都是自己独有的,所以其实fork()每次只返回一个值,但因为要返回给两个进程,总体看来就返回了两个值。
fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
认识vfork函数
函数原型
#include <unistd.h>
#include <sys/types.h>
pid_t vfork(void);
返回值:父进程返回子进程id,子进程返回0,出错返回-1看到函数原型是不是觉得它和fork()简直一模一样,既然有了fork(),为什么还要有vfork()呢?
vfork()也是用来创建子进程的,但是vfork()出的子进程和父进程共享一块地址空间,作用上类似于线程,而且vfork()保证子进程先运行,在它调用exec或exit()之后父进程才可能被调度运行。
来一段演示代码:
int count = 100;
int main()
{
pid_t pid = vfork();
if(pid < 0)
{
perror("fork");
return 0;
}
else if(pid == 0)
{
//创建的子进程
count = 200;//修改全局变量
printf("I am child! The count is %d\n",count);
exit(1);
}
//父进程
printf("I am father! The count is %d\n",count);
waitpid(pid,NULL,0);
return 0;
} 运行结果:

可以看到子进程把父进程的数据也修改了,因为子进程和父进程在同一块地址空间内运行,而且保证子进程先运行。