fork函数
首先来看下函数原型:
#include <unistd.h> //头文件 pid_t fork(void);
//返回值:成功时父进程返回子进程的id,子进程返回0;失败时父进程返回-1;先返回谁是不确定的,不同平台不一样我们可以用一段程序来测试fork函数的特点
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{
int count = 1;
pid_t pid ;
pid = fork();
if(pid < 0)
{
perror("fork error:");
return -1;
}
else if(pid == 0)
{
count++;
printf("this is child, pid=%d,count=%d(%p)\n",getpid(),count,&count);
}
else
{
printf("this is father, pid=%d,count=%d(%p)\n",getpid(),count,&count);
}
return 0;
}
运行结果可以看到,父子进程pid是不一样的;count的值也不一样,但是它们的地址却相同。
出现这样的结果是由于fork函数的功能和特性所决定的。
1.因为每个进程创建出来之后都有一个独一无二的编号id来标识这个进程,所以父子进程pid肯定是不一样的。
2.然后在程序中当pid等于0,也就是当运行子进程的时候我们让count++,而父进程不做变化,之后打印出来的两个count值不一样,可以说明父子两个进程是各自拥有自己的数据空间,也就是他们得数据是不共享的。
3. 但是两个count值得地址却相等(这里打印出来地址其实是虚拟地址),原因在于虚拟地址和计算机内存中物理地址之间是通过MMU和页表联系在一块的,(虚拟地址映射到物理地址的方法不一样)虽然虚拟地址一样,他们映射到内存中的物理地址不一样,打印出来的count值也就不一样。
4.还要注意的是:父子进程的调度顺序是由调度器来决定的。
根据上面的结果我们可以总结fork函数的以下特点;
fork函数的特点
- fork函数所创建的子进程是父进程的完整副本,复制了父进程的资源,包括内存的task_struct内容。
- 子进程拥有自己的虚拟地址空间,父子进程数据独有,(写时复制)代码共享。
- fork函数的返回值起到分流的作用,可以用fork的返回值判断哪个是父进程或子进程。
写时复制(copy-on-write)
内核只为新生成的子进程创建虚拟空间结构,它们复制于父进程的虚拟空间结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应的段的行为发生时,再为子进程相应的段分配物理空间。
Linux的fork()使用写时拷贝(copy-on-write)页实现。写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个地址空间,而是让父进程和子进程共享一个拷贝。只有在需要写入的时候,数据才会复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间的页的拷贝被推迟到实际发生写入的时候。
对于上面的代码来说,当没有执行count++操作时,此时父子进程是共享物理页面的,内核只为子进程分配了虚拟地址空间和唯一的进程标识符,而当执行count++操作后,内核才会为子进程分配物理页面,并且复制父进程的数据。所以当一个子进程没有进行写操作的时候,内核是不会分配物理页面给子进程的,从而节省了内存,并且提高了运行效率。
vfork函数
函数原型
#include <sys/types.h> //头文件
#include <unistd.h>
pid_t vfork(void);如果将上述代码fork改为vfork,结果会是怎样?
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<string.h>
4 #include<unistd.h>
5 #include <sys/types.h>
6 int main()
7 {
8 int count = 1;
9 pid_t pid ;
10 pid = vfork();
11 if(pid < 0)
12 {
13 perror("fork error:");
14 return -1;
15 }
16 else if(pid == 0)
17 {
18 count++;
19 printf("this is child, pid=%d,count=%d(%p)\n",getpid(),count,&count);
20 exit(0);
21 }
22 else
23 {
24
25 printf("this is father, pid=%d,count=%d(%p)\n",getpid(),count,&count);
26 }
27 return 0;
28 }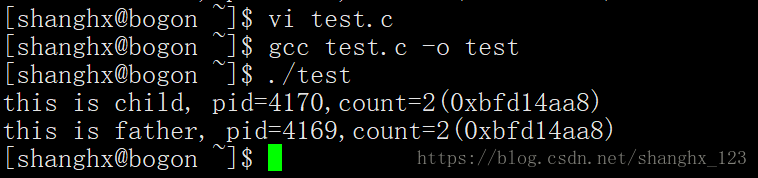
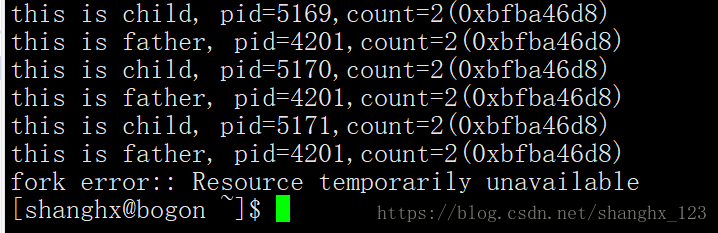
我们可以看到,pid,count值以及它们的虚拟地址都是相同的。因为vfork函数的父子进程是共享虚拟地址空间的,所以count的值肯定是一样的;但是vfork函数的代码里面,子进程最后加了一条语句exit(0);这是因为vfork这个函数在创建了子进程之后,父进程它会一直等待子进程退出,如果子进程没有退出,那么父进程将一直等待,直到子进程退出之后,父进程才会运行;如果不加exit(0)这个函数的话,或者在子进程中用return 0返回的话,那么创建的子进程在返回后,会再次回到vfork函数调用处,从而会再次创建子进程,一直到把系统的pid用完,无法创建,然后报错退出。
vfork函数特点
- vfork函数相比fork函数更加粗暴,内核连子进程的虚拟地址都不创建了,而是直接共享父进程的,从而物理地址也就被理所当然的共享了。
- 父进程会保证子进程先运行,在子进程调用exec(进程替换)或exit后才可能被调度运行。
fork和vfork的区别
两着的区别,可以总结为两点;
- fork函数创建的子进程的虚拟地址空间是复制父进程的,在进行写操作之前,父子的物理页面是共享的,而当要进行写操作时,内核才会给要进行写操作的进程重新分配一个物理页面;而vfork函数的父子进程时共享虚拟地址,从而也共享了物理地址。换句话说,也就是fork函数复制父进程的数据段,代码段;而vfork函数父子进程共享数据段。
- fork函数父子进程执行的次序不确定,它是由调度器来=来决定的;而vfork函数会保证子进程先运行,再被调用exit或exec后父进程才可能会运行。
- vfork 保证子进程先运行,在她调用exec 或exit 之后父进程才可能被调度运行。如果在
调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。