基本原理:
Encoder-decoder框架为文本处理领域的一种非常流行的框架,这项技术突破了传统的输入大小固定的问题,将深度神经网络模型用到了自然语言处理的相关任务之中。其不仅可以用在对话生成任务中,同样应用在自然语言处理的其他领域,如机器翻译、文本摘要、句法分析等任务中。
Seq2seq模型最早在2014年,由Ilya Sutskever等[1]提出。当时主要应用在机器翻译的相关问题中,其可以理解为一个适用于处理由句子(段落)X生成句子(段落)Y的通用模型。对于给定的输入句子X,我们的目标是通过Seq2seq模型生成目标句子Y。X与Y并不限制为同一种语言。将X和Y的单词序列表示如下:
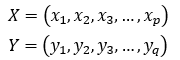
编码器(Encoder)对输入句子 进行建模,通过非线性变换将输入向量转化为中间向量表示h。
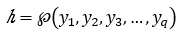
解码器(Decoder)根据编码器生成的中间向量表示 和之前的历史信息 ,生成i时刻的单词 。
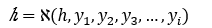
其目标函数表示为:

上述目标函数存在数值下溢(Numerical Underflow)的问题,原因在于 中每一项都小于1,乘起来就会得到很小的数字,因此在实际中往往取其对数进行放缩,训练目标即为最大化下面的目标函数。
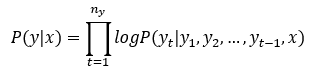
经典改进:
l Teacher foring
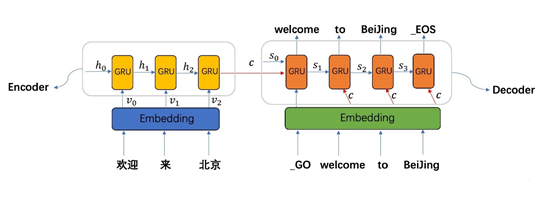
在基础的模型中,Decoder的每一次解码又会作为下一次解码的输入,这样就会导致一个问题就是错误累计,如果其中一个RNN单元解码出现误差了,那么这个误差就会传递到下一个RNN单元,使训练结果误差越来越大。Teacher Forcing[2]在一定程度上解决了这个问题,它的流程如图3所示,在训练过程中,使用要解码的序列作为输入进行训练,但是在inference阶段是不能使用的,因为你不知道要预测的序列是个啥,当然只在训练过程中效果就很不错了,它帮助模型加速收敛。
l Attention
在传统的Seq2seq模型中,编码器将所有长度的原始句子都编码成一个固定维度的向量,若原始句子较长,这个向量往往不能很好地表达原始句子的所有细节,同时,这个向量的表达受最后位置的词的影响更大。Bahdanau[3]和Cho[4]利用注意力改进了Seq2seq模型。在加入了注意力机制的Seq2seq模型中,解码器在每一个位置的生成时,会利用编码器的所有状态加权作为输入,而非仅选取编码器的最后一个状态值。
l Curriculum Learning
在模型的训练中的解码器部分,使用上一个时刻的输出作为下一个时刻的输入。这样会导致训练迭代过程早期的模型的预测能力非常弱,几乎不能给出好的生成结果。如果某一个时刻产生了垃圾结果,必然会影响后面整体的学习,以至于最终结果非常不好也很难溯源到发生错误的源头。我们在训练中使用课程学习(Curriculum Learning)[5]来改进这一问题,通过改变训练过程,以便逐步迫使模型处理它自己的错误,就像它在推断(Inference)过程中必须做的那样。具体地,以概率 去选择使用真实的输出 还是前一个时刻模型生成的输出 作为当前时刻的输入。概率 会随着时间的推移而减小,即使用计划抽样(Scheduled Sampling)的方法产生输入。这样在训练的早期阶段,模型可以获得更多真实的数据,从而加速训练;在训练的后期阶段,模型更多地使用真实输出作为输入,从而学习如何处理错误。
[1] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J]. Advances in NIPS, 2014.
[2] Williams, Ronald J., and David Zipser. "A learning algorithm for continually running fully recurrent neural networks." Neural computation 1.2 (1989): 270-280.
[3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[4] Cho K, Van Merriënboer B, Bahdanau D, et al. On the properties of neural machine translation: Encoder-decoder approaches[J]. arXiv preprint arXiv:1409.1259, 2014.
[5] Bengio Y, Louradour J, Collobert R, et al. Curriculum learning[C]//Proceedings of the 26th annual international conference on machine learning. 2009: 41-48.
最新研究:
[1] Exploring Sequence-to-Sequence Learning in Aspect Term Extraction, acl2019
https://www.aclweb.org/anthology/P19-1344/
[2] Sparse Sequence-to-Sequence Models, acl2019
https://arxiv.org/abs/1905.05702v1
[3] Self-Regulated Interactive Sequence-to-Sequence Learning, acl2019
https://arxiv.org/abs/1907.05190
[4] CNNs found to jump around more skillfully than RNNs: Compositional generalization in seq2seq convolutional networks, acl2019
https://arxiv.org/abs/1905.08527
[5] Automatic Grammatical Error Correction for Sequence-to-sequence Text Generation: An Empirical Study, acl2019
https://www.aclweb.org/anthology/P19-1609/
[6] A Neural, Interactive-predictive System for Multimodal Sequence to Sequence Tasks, acl2019
https://arxiv.org/abs/1905.08181
[7] Sequicity: Simplifying Task-oriented Dialogue Systems with Single Sequence-to-Sequence Architectures, acl2018
https://www.aclweb.org/anthology/P18-1133/
[8] Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning, acl2018
https://www.aclweb.org/anthology/P18-1165/
[9] Sequence-to-sequence Models for Cache Transition Systems, acl2018
https://www.aclweb.org/anthology/P18-1171/
[10] Tailored Sequence to Sequence Models to Different Conversation Scenarios, acl2018
https://www.aclweb.org/anthology/P18-1137/
[11] MASS: Masked Sequence to Sequence Pre-training for Language Generation, icml2019
https://arxiv.org/abs/1905.02450
[12] Minimum Divergence vs. Maximum Margin: An Empirical Comparison on Seq2seq Models, ICLR2019
https://openreview.net/pdf?id=H1xD9sR5Fm
[13] Von Mises-Fisher Loss for Training Sequence to Sequence Models with Continuous Outputs, ICLR2019
https://arxiv.org/abs/1812.04616
[14] Posterior Attention Models for Sequence to Sequence Learning, ICLR2019
https://openreview.net/forum?id=BkltNhC9FX
[15] Detecting Egregious Responses in Neural Sequence-to-sequence Models, ICLR2019
https://openreview.net/forum?id=HyNA5iRcFQ
[16] Improving Sequence-to-Sequence Learning via Optimal Transport, ICLR2019
https://openreview.net/forum?id=S1xtAjR5tX
[17] Sentence-wise Smooth Regularization for Sequence to Sequence Learning,aaai2019
https://arxiv.org/abs/1812.04784v1
[18] Trainable Decoding of Sets of Sequences for Neural Sequence Models,icml2019
http://proceedings.mlr.press/v97/kalyan19a/kalyan19a.pdf
[19] Compositional generalization through meta sequence-to-sequence learning, neurIPS2019