目录
1.网页基础
- html:http://www.w3school.com.cn/html/index.asp
- css:http://www.w3school.com.cn/css/index.asp
- js:http://www.w3school.com.cn/js/index.asp
1.1网页结构
网页中所有标签都是节点,他们构成了一个DOM树。(doucument object model)
- 整个文档是一个节点
- 每个HTML元素是元素节点
- HTML内的文本是文本节点
- 每个HTML属性是属性节点
- 注释是注释节点

节点直接通常有层级关系。我们通常用父节点(父)子节点(孩子),兄弟节点(silbing)
2.爬虫的基本原理
获取网页并提取和保存信息的自动化程序
2.1获取页面
获取网页中的源代码
构造一个请求并发送给服务器,然后接收到响应并将其解析出来
ptyhon给我们提供了很多库,例如urllib的,请求
2.2提取信息
提取我们想要的信息
通用的方法是使用正则表达式,还可以根据一些网页节点属性来提取
还有些页面返回的是JSON字符串,爬取更加的方便
只要是基于HTTP或HTTPS协议的都可以爬取。
2.2.1JS渲染的页面
很多时候爬取到的源代码和浏览器中显示的不一样,整个网页都是由js渲染出来的,js会改变html的节点,向其添加内容
可以分析后台的AJAX接口,也可以使用硒,飞溅库来显示JS渲染
2.2.2无状态HTTP
HTTP的一个特点“无状态”:对事物的处理没有记忆功能,也就是所服务器不知道客户端是什么状态
会话和饼干:用于保持HTTP连接状态的技术
会话:指有始有终的一系列动作/消息,在网络中会话对象用来存储用户所需的属性以及配置信息
饼干:网站为了辨别用户身份,进行会话跟踪而存储在用户本地终端的数据。
会话用于网站的服务,Cookie用于客户端器端
有Cookie后,客户端访问会自动附带上他,客户端通过识别来判断是那个用户登录的,然后再对他做出响应
会话维持原理:
第一次请求,服务器会返回一个带有Set-Cookie的字段给客户端,客户端会保存起来
下一次请求,浏览器会把cookies放在亲球头一起提交给服务器,服务器检查cookie来判断会话识别用户
Cookie属性结构:
Applicatin->Storage->Cookie
HTTP:cookie的httponly属性。若此属性为true,则只有HTTP头中会带有此cookie信息,而不能通过doucment.cookie来访问
Secure:Cookie是否仅被使用安全协议传输.安全协议有HTTPS和SSL.默认为false
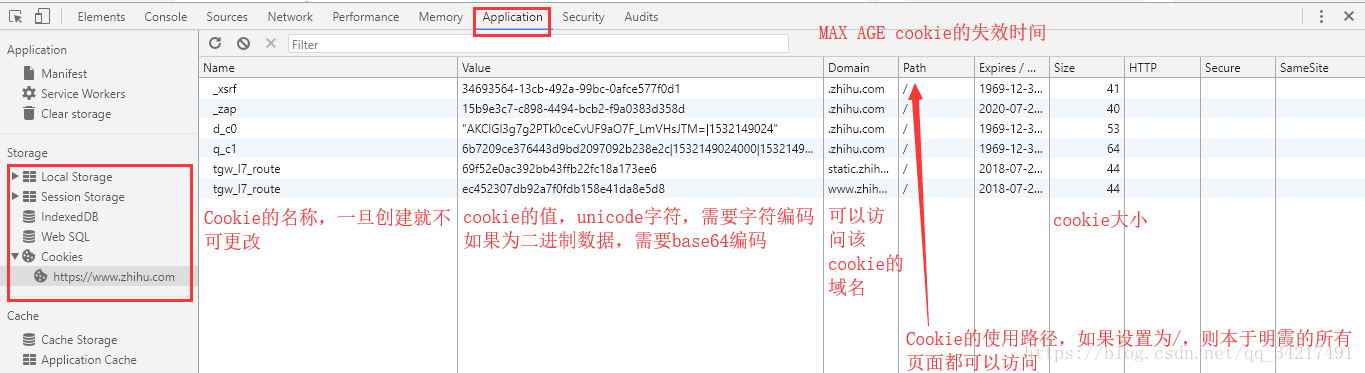
我们可以将cookie保存在硬盘中,在使用某种手段改写浏览器发出的HTTP请求头,把原来的Cookie发给服务器,仍然能找回原来的会话ID
2.3.保存数据
可以保存为text、json格式,也可以存在数据库中和远程服务器
2.4自动化程序
爬虫
3.代理的基本原理
有些网站会使用反爬虫技术,原理是检测IP的访问频率。如果访问频率过高,服务器就会封IP,我们可以通过某种方式来伪装我们的IP,让服务器识别不出
原理:
代理就是代理服务器(proxy server)。功能是代理网络用户去取得网络信息。
我们不在直接向web服务器发送请求,而是向代理服务器发送请求,代理服务器再发给Web服务器,再把web服务器返回的响应转发给客户端。
作用:
突破自身访问限制
访问一些单位或团体内部资源
提高访问速度
隐藏真实ID
代理分类:
FTP代理服务器:访问FTP服务器HTTP代理服务器、
SSL/TLS代理:访问加密网站
telnet代理;远程控制
RTSP代理Real流媒体服务器
POP3、SMTP;收发邮件
SOCKS:单纯传递数据包,不关心具体协议和用法
根据匿名程度区分
高度匿名代理;会将数据包原封不动的转发,而记录的IP为代理服务器的IP
普通匿名代理:会在数据包上做一些改动,服务器有可能发现是一个代理服务器
透明代理:改动数据包,还会告诉服务器真实IP
间谍代理:指组织或个人用于几率用户传输的数据,然后进行研究,监控等目的的代理服务器。
常见的代理设置
免费代理
付费代理
ADSL拨号