chatgpt 是典型的 NLP 类型应用。也就是它主要于语言的处理和输出。因此它的模型设计必然借鉴了深度学习早期在语言翻译方面的算法设计。因此理解 chatgpt 我们就需要理解深度学习算法是如何处理自然语言翻译这个问题,就像学习微积分时,我们需要提前掌握加法和乘法。
语言翻译本质上是将一个输入序列变成另一个输入序列。例如我们在谷歌翻译或百度翻译中输入一个序列序列:how are you,翻译成中文时输出另一个符号序列 :你好阿。因此用术语来说就是 sequence to sequenc, 也就是 seq2seq。从直觉上看,两种语言在表达相同“意思”时,他们的符号表现形式不一样,显然英语和中文对应符号看起来完全不同,但是符号所隐藏的“含义”一样,只要你掌握这两种语言,那么当你看到 “how are you” 和 "你好阿"这两个符号字符串时,你能体会到两个符号串的“本质”是一样的,算法的目的就在于如何从第一个符号串中将其“本质”抽取出来,然后用这个“本质”,根据第二个符号串的语言的组合规则,将第二个符号串生成出来。
因此网络的第一步就是根据第一个符号串去识别其“本质”。显然这个“本质”不能用结构化的数据去描述,因此跟前面描述的一样,我们使用向量去描述,因此网络的第一个功能就是识别输入符号序列,然后输出一个用于表示这个序列“本质”的向量,这部分也叫做 Encoder,它的基本流程如下:
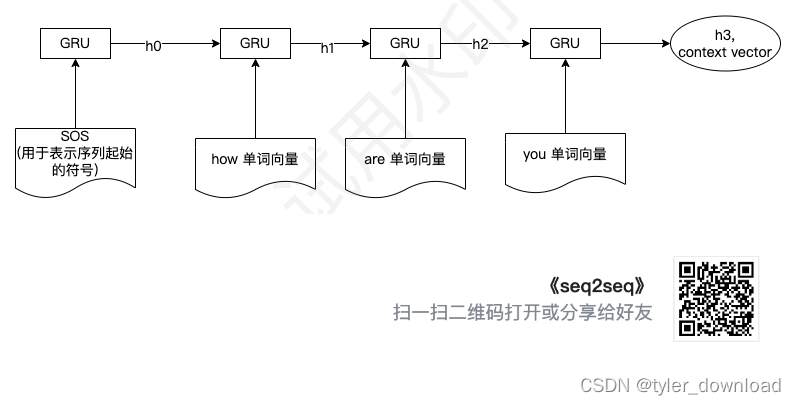
在上图中 GRU 是一个网络组件,说白了就是一个特定函数,它能接收一个或两个输入向量然后输出一个向量。SOS 是一个特定符号,告诉网络这里是输入序列的起始位置。h1表示网络在读到单词 ‘how’时产生的理解,h2 表示网络读到’ how are’两个符号时产生的理解,最后的 h3 表示网络在读取’how are you’后所产生的理解,这里的 h3就用来模拟人在读取字符串’how are you’后所得到的“意义”。
当网络”理解“了语句"how are you"的意义后,也就是得到了向量 h3,它就能使用这个“意义”来生成另一种语言对应该“意义”的字符串表示,这部分网络叫 decoder,他的结构如下:
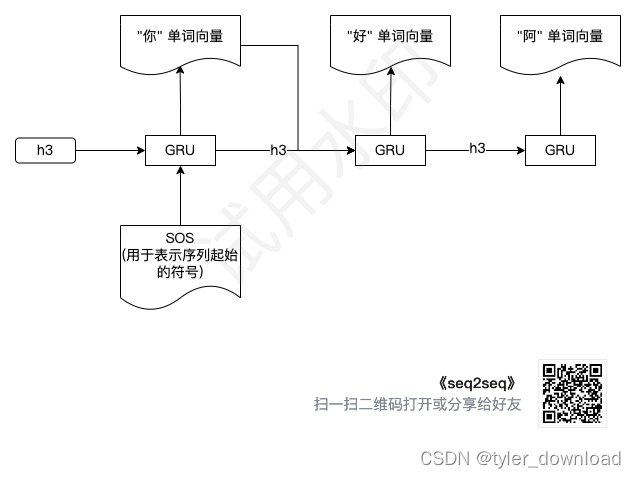
其基本流程是解码器将编码器输出的最终向量也就是 h3 和一个表示起始符号的向量输入 GRU 单元,然后它生成“你”对应向量,下一步就是将 h3 和"你“对应向量输入 GRU 单元得到”好“对应的向量,以此类推。
这里我们需要使用到一个深度学习中,在大语言模型出现前常用的一种 NLP 算法处理单元叫 GRU,它接收两个输入向量 hidden_state, input, hidden_state 是我们前面说过的网络在读入一系列字符串后所获得的认知或知识,input 是当前输入单词对应的向量。GRU的基本工作就是“破旧立新”,所谓破旧指的是破除,删除原来一些”不合时宜“的信息。所谓“原来的信息”就是输入给它的 hidden_state 向量,它会把这个向量里面的一些数据清零。这个过程如下:
首先它包含两个矩阵分别叫 W_hidden_state 和 W_input,让他们分别跟 向量 hidden_state,和 input 做乘积操作,然后将操作后的两个结果向量加总得到结果向量,最后再使用 sigmod 函数作用在这个结果向量上,计算过程如下所示:
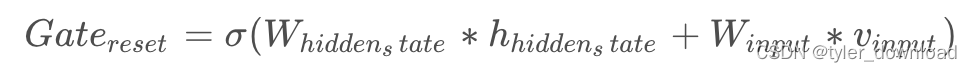
其中 W_hidden_state 和 W_input 是网络用于训练的参数,他们将决定hidden_state 向量中哪些数据需要清除,哪些需要保留,注意 sigmoid计算会把输入向量的每个分量映射到[0,1]之间,哪些数值靠近 0 的分量就对应于要清除的数据。
接着先用一个矩阵 W_h 跟输入的 hidden_state 向量做乘法得到一个结果向量,然后再用这个结果向量跟上面的 Gate_reset 向量做元素对应乘法得到“破旧”向量,同时用另一个矩阵 W_i 跟输入向量 input 做乘法,所得两个向量加总后再做一次 tanh 运算,流程如下:
r = t a n h ( G a t e r e s e t Θ ( W h ∗ h h i d d e n S t a t e ) + W i ∗ v i n p u t ) r = tanh(Gate_{reset} \Theta(W_{h}*h_{hiddenState}) + W_{i}*v_{input}) r=tanh(GateresetΘ(Wh∗hhiddenState)+Wi∗vinput)
注意这里的Theta 操作表示两个向量对应分量相乘,也就是:
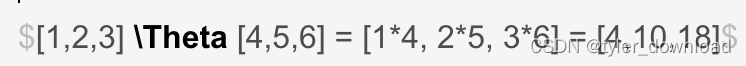
由于 Gate_rese向量中的分量取值在[0,1]之间,于是那些取值靠近 0 的分量就会执行上面操作后就会把对应分量也拉到接近 0,这就相当于进行了“清除”操作。
下面我们再看看如何“立新”。首先 GRU 单元包含了两个特定矩阵分别为 W_input_update, W_hidden_update,这两个矩阵分别跟对应向量做乘法,所得的结果向量加总,最后在此基础上做 sigmoid 操作,步骤如下:
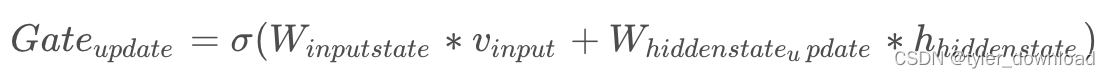

然后将Gate_update 与 hidden_state 向量做 theta 操作:
u = G a t e u p d a t e Θ h h i d d e n s t a t e u = Gate_{update} \Theta h_{hiddenstate} u=GateupdateΘhhiddenstate

最后将 r和 u 作如下运算后,所得结果作为最终输出:
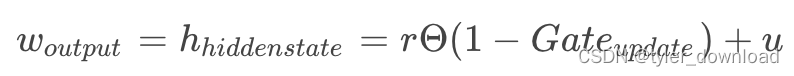
这里的 W_output 对应网络识别当前输入单词后所得的输出,同时 h_hiddenstate 对应网络在识别当前所有单词组成的字符串后所获得的“知识”。
有了上面的基础知识后,我们实现一个基于深度学习的双语翻译系统。我们对系统采用逐级升级的方式,最开始我们使用最简单的 seq2seq 模型看看效果,接着加上 attention 机制,看看改进效果如何,最后使用 transoformer 模型,再对比一下相比于前面模型,它的改进到底有多强烈。
首先我们准备用于训练的数据,在执行下面一系列代码前我们需要安装 torchtext 的 0.6 版本,对应命令如下:
pip install torchtext==0.6
pytorch 框架为翻译提供了含有三种语言的语料,其中包括德语,英语和法语,每种语言中每一句话都一一对应,例如英语中包含一句“你好阿”,那么德语和法语中就包含同样一句话,于是就可以使用网络进行一一对应的翻译训练,加载训练语料的代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.lagecy.dataset import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import random
import math
import time
在上面代码中我们需要针对 torchtex 部分做一下详细说明。在 NLP 的深度学习模型设计上,数据预处理是一件繁琐但不得不做而且必须细心的工作,一旦预处理做不好,输入模型的数据有问题,那么模型就会在错误数据的训练下给出错误结果。前面章节我们看到深度学习网络只能接收向量,由于数据是语言文字,因此我们需要预先将文字符号转换为向量才能输入给网络进行识别或者训练,torchtext 这个框架的主要任务就在于此,我们也可以看到上面代码有 legacy,也就是上面调用的库是老代码,不过在这里我们还可以继续使用。
文字转换为向量需要分几步走,第一步是分词,也就是把句子分成组成他的部分,在英语中句子的组成部分就是单词,而单词间使用空格隔开,因此英语的分词相对简单,但中文分词就很难了,因为中文句子的基本单位是字,而字与字之间没有空格,于是区分哪些字能相互组合成有意义的词是一个比较复杂的问题,例如中文句子“我爱北京天安门",正确的分词就是"我”,“爱”,“北京”,“天安门”,由于我们后面模型主语处理西方语言,因此中文分词我们先忽略。其实英语的分词也不是通过空格这么简单,例如"good morning!“,如果仅仅依靠空格分词就会分成"good”, “morning!”,但感叹号不是单词的一部分,因此正确的分词就需要分成“good", “morning”, "!"三部分,好在有现成代码库我们可以之间调用,因此分词不是难点。
第二步就是将单词转换为数字,这个步骤也叫 build_vocab,他的目标是把一个单词跟一个数字对应起来,例如"good morning!"执行该步骤后会得到一个类似如下的 map 对象:
{
"good"-> 0,
"morning"->1,
}
第三步是将一个句子进行填充,因为输入网络的句子通常要求满足预先规定的长度,如果句子长度不足,那么就需要用特定的字符串或者标签来填充,假设预先指定的句子长度是 4,那么 “good mornong"就会在末尾用两个” <pad> "这样的字符串来填充,于是分词后就变成:“good”,“morning”, " <pad> ", " <pad> "
第四步是设置句子的起始和结束标志,因为在输入网络时,我们需要告诉网络哪里是句子的开头,哪里是句子的结尾,因此需要使用" <sos> " 表示句子开头," <eos> “表示结尾,于是“good morning"分词后就变成” <sos> " “good”,“morning”, " <pad> ", " <pad> “” <eos> ", 当然这些填充的字符串也会在第二步中有对应的数字。
以上这些工作就是上面代码中 Field 类的作用。我们看具体例子。假设我们在本地目录上有一个包含训练数据的test.json 文件,其内容如下:
{
"name": "Jocko",
"quote": "You must own everything in your world. There is no one else to blame.",
"score": 1
}
{
"name": "Bruce",
"quote": "Do not pray for an easy life, pray for the strength to endure a diffcult one.",
"score": 1
}
{
"name": "Random Potato",
"quote": "Stand tall, and rice like a potato!",
"score": 0
}
然后我们使用如下代码读取上面数据:
from torchtext.data import TabularDataset
#分词先使用简单的按照空格分割
tokenizer = lambda x: x.split()
quote = Field(init_token='<sos>',eos_token='<eos>',sequential=True, use_vocab=True, tokenize=tokenizer, lower=True)
#因为 score 只有数字因此不需要进行文字到数字的转换步骤
score = Field(sequential=False, use_vocab=False)
#设定哪些字段需要读取
fields = {
'quote':('q', quote), 'score':('s', score)}
#加载数据文件,由于是测试,我们把训练数据和测试数据都指向同一个文件
train_data, test_data = TabularDataset.splits(path='/content/', train='test.json',
test='test.json',format='json',
fields=fields)
print(train_data[0].__dict__.keys())
print(train_data[0].__dict__.values())
print(train_data[1].__dict__.keys())
print(train_data[1].__dict__.values())
print(train_data[2].__dict__.keys())
print(train_data[2].__dict__.values())
'''
建立单词与编号的关联, max_size 表示编号最大值,min_freq 表示出现过指定次数的单词才能赋予编号
'''
quote.build_vocab(train_data, max_size=10000, min_freq=1)
train_iterator, test_iterator = BucketIterator.splits((train_data, test_data),
batch_size = 2,
)
'''
在上面设置的 batch_size = 2,也就是一个集合有两个句子,但是因为数据有 3 个句子,
因此数据就分成两个集合,其中一个集合包含一个句子,另一个集合包含2 个句子,
因此下面代码打印结果中,其中有一个的向量只包含 1 个元素,另一个包含 2 个元素
'''
for batch in train_iterator:
print(f"batch.q: {
batch.q}")
print(f"batch.s:{
batch.s}")
代码允许后输出结果如下:
dict_keys(['q', 's'])
dict_values([['you', 'must', 'own', 'everything', 'in', 'your', 'world.', 'there', 'is', 'no', 'one', 'else', 'to', 'blame.'], 1])
dict_keys(['q', 's'])
dict_values([['do', 'not', 'pray', 'for', 'an', 'easy', 'life,', 'pray', 'for', 'the', 'strength', 'to', 'endure', 'a', 'diffcult', 'one.'], 1])
dict_keys(['q', 's'])
dict_values([['stand', 'tall,', 'and', 'rice', 'like', 'a', 'potato!'], 0])
batch.q: tensor([[ 2],
[12],
[23],
[ 6],
[ 5],
[ 8],
[13],
[19],
[ 6],
[ 5],
[32],
[30],
[ 7],
[15],
[ 4],
[11],
[25],
[ 3]])
batch.s:tensor([1])
batch.q: tensor([[ 2, 2],
[29, 35],
[31, 21],
[ 9, 26],
[28, 16],
[20, 17],
[ 4, 36],
[27, 34],
[ 3, 33],
[ 1, 18],
[ 1, 22],
[ 1, 24],
[ 1, 14],
[ 1, 7],
[ 1, 10],
[ 1, 3]])
batch.s:tensor([0, 1])
注意在上面输出结果中,我们对句子做分词时仅仅通过空格,因此感叹号才会跟单词 potato合在一起。现在我们改进一下分词方法,首先执行如下两个命令下载分词算法:
#下载英语分词算法
!python -m spacy download en_core_web_sm
#下载德语分词算法
!python -m spacy download de_core_news_sm
然后加载对应分词算法:
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
然后替换掉原来使用空格进行分词的方式:
#分词先使用简单的按照空格分割
#tokenizer = lambda x: x.split()
#使用新加载的分词算法
import spacy
def tokenizer(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
然后再把前面代码运行一次就可以发现感叹号跟 potato 分开了:
dict_keys(['q', 's'])
dict_values([['stand', 'tall', ',', 'and', 'rice', 'like', 'a', 'potato', '!'], 0])
前面我们说过单词会对应为数字编号,我们使用下面代码能查看对应关心:
#单词转换为编号
print(f'the number for word:"You" is {
quote.vocab.stoi["You"]}')
#查看!对应编号
print(f'the number for word:"!" is {
quote.vocab.stoi["!"]}')
#查看起始标志的编号
print(f'the number for word:"<sos>" is {
quote.vocab.stoi["<sos>"]}')
#查看结束标志的编号
print(f'the number for word:"<eos>" is {
quote.vocab.stoi["<eos>"]}')
#查看编号转换为单词
print(f'the word for number:5 is {
quote.vocab.itos[5]}')
print(f'the word for number:6 is {
quote.vocab.itos[6]}')
print(f'the word for number:2 is {
quote.vocab.itos[2]}')
print(f'the word for number:10 is {
quote.vocab.itos[10]}')
上面代码运行后所得结果如下:
the number for word:"You" is 0
the number for word:"!" is 11
the number for word:"<sos>" is 2
the number for word:"<eos>" is 3
the word for number:5 is ,
the word for number:6 is a
the word for number:2 is <sos>
the word for number:10 is to
从输出可以看到,分词后对应标点符号例如’!', ','都有对应编号。最后我们再看看训练数据集 Multi30k,它包含了英语,德语,法语三种语言,每种语言都有一一对应的一句话,也就是有一句英语,那么就有对应的一句德语和法语的翻译,通过这个数据集就能用来训练后面我们要做的翻译系统。
首先我们先设置好英语和德语的分词方法,设置好对应的 Field 对象,代码如下:
def tokenizer_eng(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
def tokenizer_ger(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
#设置英语和德语的两种预处理方式
english = Field(sequential=True, use_vocab=True, tokenize=tokenizer_eng, lower=True)
german = Field(sequential=True, use_vocab=True, tokenize=tokenizer_ger, lower=True)
然后使用下面代码从 Multi30k 数据库中加载德语和英语两种语料:
train_data, validation_data, test_data = Multi30k.splits(exts=('.de', '.en'),
fields=(german, english))
#建立英语与德语单词与数字编号的对应
english.build_vocab(train_data, max_size=10000, min_freq=2)
german.build_vocab(train_data, max_size=10000, min_freq=2)
接着我们为三种数据建立遍历器,同时把读入的数据打印出来看看:
#建立英语与德语单词与数字编号的对应
english.build_vocab(train_data, max_size=10000, min_freq=2)
german.build_vocab(train_data, max_size=10000, min_freq=2)
#建立对应数据集的遍历器
train_iterator, validation_iterator, test_iterator = BucketIterator.splits(
(train_data, validation_data, test_data),
batch_size=64
)
for batch in train_iterator:
print(batch)
在执行上面代码时,运行到Multi30k.splits可能会有 FileNotFound 的错误,这是因为它内部用于下载数据集的链接失效了,所以我们需要自己先下载数据集,数据集下载的链接如下:
https://github.com/neychev/small_DL_repo/tree/master/datasets/Multi30k
我们把里面的training.tar.gz,validation.tar.gz,mmt_task1_test2016.tar.gz下载到本地解压,在对应路径下会看到 train.de, train.en, val.de,val.en,test2016.de,test2016.en 这些文件,接着在代码所在路径创建新的路径./data/multi30k,把前面那些文件全部放入到新建的路径下,如果你是在 colab上测试,那么我们需要在当前路径下创建/data/multi30k 这个路径,然后把前面那些文件全部上传,情况如下所示:
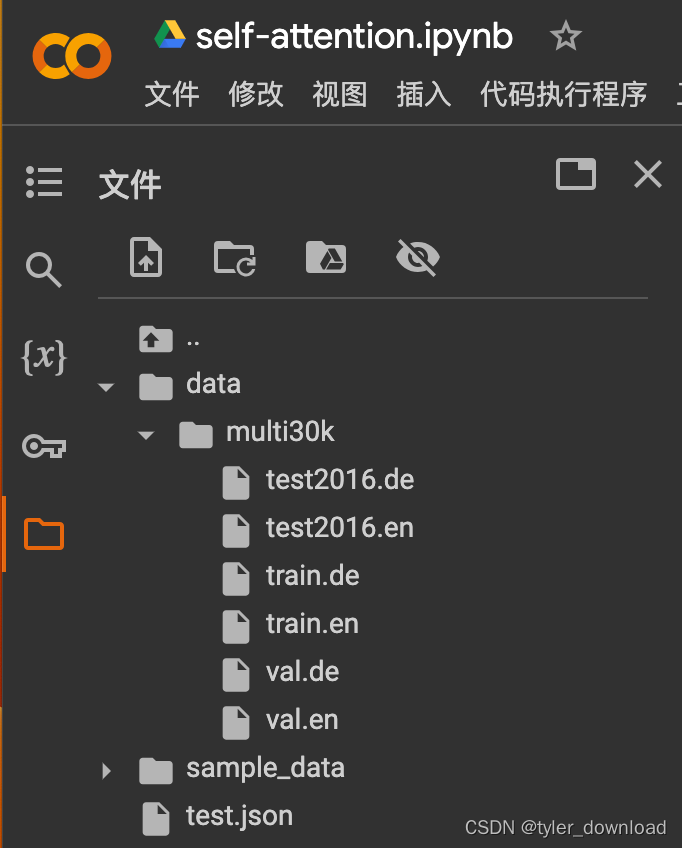
完成数据准备后,执行上面代码所得结果如下:
[torchtext.data.batch.Batch of size 64 from MULTI30K]
[.src]:[torch.LongTensor of size 23x64]
[.trg]:[torch.LongTensor of size 31x64]
[torchtext.data.batch.Batch of size 64 from MULTI30K]
[.src]:[torch.LongTensor of size 24x64]
[.trg]:[torch.LongTensor of size 22x64]
[torchtext.data.batch.Batch of size 64 from MULTI30K]
[.src]:[torch.LongTensor of size 27x64]
[.trg]:[torch.LongTensor of size 28x64]
...
我们看到输出的.src,.trg中都有 64,它表示一个集合中有 64 个句子,前面的数字表示每个句子的长度,当然在一个集合中各个句子的长度必然不同,于是它会选择其中长度最大的为标准,任何短于标准长度的句子都用符号"<pad>"来填充。我们可以用如下代码把这个标志对应的编号打印出来:
print(f"number for word: '<pad>' is : {
english.vocab.stoi['<pad>']}")
上面代码运行后所得结果如下:
number for word: '<pad>' is : 1
也就是说用于填充句子长度的字符串对应编号是 1.
以上就是实现网络模型前的数据准备,下一节我们看看如何设计 seq2seq翻译模型。本节所有代码和数据的下载地址:
https://github.com/wycl16514/seq2seq-gru-data-preprocess.git