论文地址:https://arxiv.org/abs/1905.07799?context=cs.LG
研究的问题:
相对于LSTM来说,Transformer几乎在所有的NLP任务上都能胜出。但是有一点,Transformer的时间复杂度是O(n^2)的,因为对于每一步,它都需要计算该步与之前的所有context的attention信息。但LSTM则是O(n)的复杂度。
这样的性质,使得Transformer在序列长度上很难扩展,基本上1k个token就是上限了。然而对于字符级的语言模型来说,上千个token的输入也是比较常见的。
本文的工作与创新点:
论文提出了一种自适应宽度的方法,显著地扩展了transformer中使用的最大上下文大小。在这种方法下,可以将输入序列扩展到超过8000个token,同时不损失性能也不会增加计算或内存开销。
研究方法:
Motivation:
方法来源于对不同head的观察,在普通的Transformer中,不同的head会学习到不同的部分,它们的宽度并不同,如下图所示:
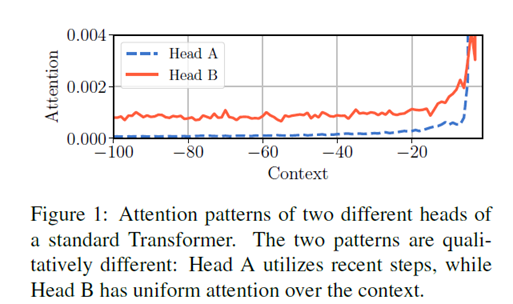
headA关注到的是最近的20个,再往前的80个的权重很低。而HeadB关注到的则是全部的token。
因而,如果能有一种方法,使得我们能自动省略掉headA的不相干的计算,那么,就可以大大减少计算量。
Realization:
它的实现借助了一个mask函数,公式和图像如下图所示:
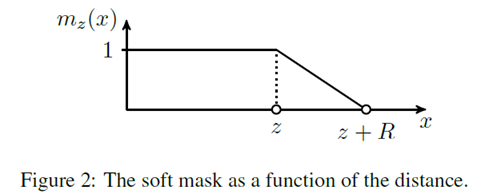
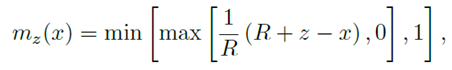
在计算attention的权重的时候,使用context和当前位置的距离来作为mask函数的输入。在学习过程中,z是需要学习的参数,对每个head,z都是不同的。attention权重的计算如下图:
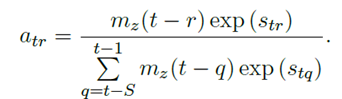
在损失函数中,给z添加一个L1 penalization
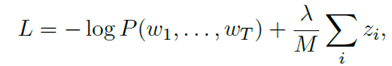
作为扩展,我们也可以用网络的方式来学习z,即z是基于当前输入的一个输出。这种方式被称为动态宽度。

实验部分:
关于结果、参数量和计算量之前的对比:
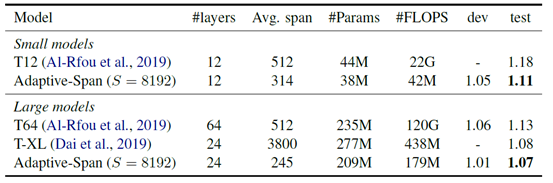
可以看到,相对于普通的Transformer来说,参数量并没有太大的降低,但是计算量却会有三四个数量级的减少。
评价:
对于transformer模型有很多修改,本文是其中之一。通过观察发现大部分层/head的attention集中在局部而对网络进行优化,使用相对低的计算代价建模长程上下文,在字符级语言模型上效果显著优于transformer-xl,不过adaptive的方法通常需要对参数比较敏感,其它任务上的性能有待考证。