参考:极客时间:linux性能优化实战
一、平均负载
使用top或者uptime命令来查看系统的负载情况
% uptime 6:55 up 68 days, 14:59, 3 users, load averages: 4.55 2.38 2.01
当前时间 运行时长 用户数 平均负载 1分钟 5分钟 15分钟
可以使用man uptime来查看具体定义:
The uptime utility displays the current time, the length of time the system has been up, the number of users, and the load average of the system over the last 1, 5, and 15 minutes
平均负载并非cpu使用率,它是单位时间内,系统可运行状态和不可中断状态的平均进程数,即平均活跃进程数。(平均活跃进程数)
所谓可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,
处于R状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的
是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk
Sleep)的进程。
假设系统有4个cpu
平均负载为2: 有一半的cpu空闲
平均负载为4: 全部cpu都在使用,效率最高
平均负载为8: 有一半的进程在等待cpu
使用top或者查看/proc/cpuinfo 来确认cpu核数
grep 'model name' /proc/cpuinfo | wc -l
当平均负载高于cpu数量70%时,应该检查负载过高的问题,否则可能会影响进程的响应速度。
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
工具:stress 和 sysstat 工具包(apt install sysstat)
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有CPU的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、 I/O 以及上下文切换等性能指标。
命令:
#模拟一个cpu使用率100% $ stress --cpu 1 --timeout 600 # -d 参数表示高亮显示变化的区域 $ watch -d uptime # -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据 $ mpstat -P ALL 5
procs -----------memory---------- ---swap-- -----io---- -sysem-- ------cpu-----
r b swpd free buf cache si so bi bo in cs us sy id wa s
0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
# 查询具体哪个进程导致cpu使用率过高,间隔5秒后输出一组数据 $ pidstat -u 5 1 #模拟io压力,即不停执行sync $ stress -i 1 --timeout 600 #模拟8个进程 $ stress -c 8 --timeout 600
二、CPU上下文切换
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是CPU在运行任何任务前,必须的依赖环境,因此也叫CPU上下文。
CPU上下文切换即将上一个任务的寄存器和程序计数器保存起来,再加载新任务的程序上下文,跳转到程序计数器所指的新位置,执行任务。
根据任务的不同,CPU的上下文切换也有三种不同场景:进程上下文切换,线程上下文切换,中断上下文切换。
1. 进程上下文切换:
Linux将进程的运行空间分为内核空间和用户空间,分别对应Ring 0 和Ring 3。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内
核中,才能访问这些特权资源。

进程可以在用户空间和内核空间去运行,在用户空间运行时称为进程的用户态,陷入内核空间时称为进程的内核态。
用户态到内核态需要通过系统调用去完成,如查看文件:open()->read()->write->close;
系统调用同样会触发CPU上下文切换,首先会保存用户态的寄存器的用户指令,然后寄存器切换到内核态指令的新位置,然后跳转到内核空间执行任务,执行完毕后将寄存器切换为保存的用户态,再切换到用户态,继续执行进程。所以一次系统调用发生了两次CPU上下文切换。
系统调用并非是进程上下文切换,因为始终是在一个进程内,所以,系统调用过程通常称为特权模式切换,而不是上下文切换。
系统调用和进程切换的区别:
进程包含用户空间的虚拟内存,栈,全局变量等资源,也有内核空间的内核堆栈,寄存器等状态。
因此进程切换比系统调用除了内核空间的资源保存和替换,多了将用户空间的资源保存、替换的步骤。

当CPU频繁的切换上下文时,会消耗大量的时间,真正执行任务的时间就会减少。此外,Linux通过TLB(Translation Lookaside Buffer)管理虚拟内存到物理内存的映射关系,虚拟内存更新后,TLB也会被刷新,内存的访问就会变慢。TLB是处理器共享的,多处理器的系统中同样会影响到其他处理器的进程执行。
触发进程调度的场景:
其一,为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
2. 线程上下文切换
线程是调度的基本单位,进程是资源拥有的基本单位。
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程上下文切换有两种情况:
(1). 两个线程属于不同进程,虚拟内存、变量等都不共享,所以线程切换等同于进程切换。
(2). 两个线程属于同一个进程,虚拟内存,全局变量都共享,因此只需要切换线程的私有数据、寄存器等不共享的数据。
3. 中断上下文切换
为了响应硬件的事件,中断处理会打断现有运行的进程的正常调度和执行,去执行中断程序。在打断正常执行的进程时,会保存进程的当前状态,在中断结束后继续运行当前进程。
中断不涉及到用户空间,因此不需要保存和恢复虚拟内存、全局变量等,只需要内核中断服务所需要的状态,如CPU 寄存器、内核堆栈、硬件中断参数等。
中断比进程有更高的优先级,因此不会出现进程上下文切换和中断上下文切换同时发生。并且中断同样会消耗CPU,如果切换次数过多同样会影响系统性能。
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数.
# 每隔5秒输出1组数据 $ vmsat 5 procs -----------memory---------- ---swap-- -----io---- -sysem-- ------cpu----- r b swpd free buf cache si so bi bo in cs us sy id wa s 0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
pidstat -w 查看进程上下文切换情况
# 每隔5秒输出1组数据 $ pidsat -w 5 Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU) 08:18:26 UID PID cswch/s nvcswch/s Command 08:18:31 0 1 0.20 0.00 sysemd 08:18:31 0 8 5.40 0.00 rcu_sched
cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,
nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数
-
自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
-
非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
sysbench 是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况。
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题 $ sysbench --threads=10 --max-time=300 threads run
三、CPU使用率过高
而我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
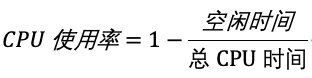
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如3秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

可以通过查看/proc/stat 和 /proc/[pid]/stat
工具:apache bench
apt install sysstat linux-tools-common apache2-utils
perf安装:linux-tools-generic 、linux-cloud-tools-generic
# 并发10个请求测试Nginx性能,总共测试100个请求 ab:apache bench $ ab -c 10 -n 100 http://<IP>:<PORT>/ # -g开启调用关系分析, -p指定进程号 查看某个进程的具体方法调用信息 $ perf top -g -p <PID>
# 使用top 按1查看每个CPU的使用情况
$ top
Requests per second:每秒平均请求数
root@parallels-Parallels-Virtual-Platform:/home/parallels# ab -c 10 -n 1000 http://10.211.55.8:10000/ This is ApacheBench, Version 2.3 <$Revision: 1807734 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 10.211.55.8 (be patient) Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Completed 1000 requests Finished 1000 requests Server Software: nginx/1.15.4 Server Hostname: 10.211.55.8 Server Port: 10000 Document Path: / Document Length: 9 bytes Concurrency Level: 10 Time taken for tests: 39.565 seconds Complete requests: 1000 Failed requests: 0 Total transferred: 172000 bytes HTML transferred: 9000 bytes Requests per second: 25.27 [#/sec] (mean) Time per request: 395.653 [ms] (mean) Time per request: 39.565 [ms] (mean, across all concurrent requests) Transfer rate: 4.25 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.5 0 4 Processing: 110 394 34.9 393 591 Waiting: 110 394 34.9 393 591 Total: 110 394 34.9 393 592 Percentage of the requests served within a certain time (ms) 50% 393 66% 405 75% 412 80% 418 90% 434 95% 449 98% 474 99% 501 100% 592 (longest request) root@parallels-Parallels-Virtual-Platform:/home/parallels#
# 以树形结构展示进程之间的关系 $ pstree | grep xxx # 记录性能事件,等待大约15秒后按 Ctrl+C 退出 $ perf record -g # 查看报告 $ perf report
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有CPU的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、 I/O 以及上下文切换等性能指标。
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据 $ mpsat -P ALL 5 # 间隔5秒后输出一组数据 $ pidsat -u 5 1 # 查看进程的CPU使用状态 $ pidsat -p PID
四、系统中断和僵尸进程
top命令输出的s(status)列表示进程的状态,有如下状态:
- R 是Running或者Runable的缩写,表示在CPU的就绪队列中,正在运行或者等待运行。
- D 是Disk Sleep的缩写,不可中断睡眠状态(Uninterruptible Sleep),一般表示进程正在和硬件交互,并且交互过程不可以被其他进程或者中断打断。
- Z 是Zombie的缩写,表示僵尸进程,也就是进程实际上结束了,但是父进程还没回收它的资源(如进程的描述符,PID等)。
- S 是Interruptible Sleep的缩写,可中断睡眠状态,表示进程因为等待某个事件而被系统挂起,当进程等待的事件发生时,它会被唤醒进入R状态。
- I 是Idle的缩写,空闲状态,用在不可中断睡眠的内核线程上。D表示硬件交互导致的不可中断进程,I表示并没有任何负载。D状态进程会导致平均负载升高,I状态进程不会。
- 第一个是T或者t,是Stopped或者Traced的缩写,表示进程处于暂停或者跟踪状态。
- X 是Dead的缩写,表示进程已经消亡,所以不会在top或者ps中看见。
如果状态是Ss+:后面的s代表这个进程是一个会话的领导进程,+ 表示前台进程组。进程组和会话用来管理一组相互关联的进程。
- 进程组:表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员。
- 会话:指共享同一个控制终端的一个或多个进程组。
如SSH登录server,打开一个控制终端(TTY),控制终端对应一个会话,终端中运行的命令以及他们的子进程,构成了一个个进程组,在后台运行的命令,构成后台进程组;在前台运行的命令,构成了前台进程组。
不可中断状态是为了保证进程数据与硬件状态一致。
如果系统或者硬件出现问题,可能会导致出现大量不可中断进程,需要检查I/O性能问题。
僵尸进程是多进程容易出现的问题,父进程通过系统调用wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程结束后,会向父进程发送SIGCHLD信号,父进程可以注册SIGCHLD的处理函数,异步回收资源。
如果父进程没有这么做,或者子进程执行太快,父进程没来得及处理子进程状态,子进程就退出了,这时子进程就会变成僵尸进程。
父进程回收僵尸进程的资源或者父进程退出后,由init()进程回收后也会消亡。
如果僵尸进程过多会占用PID号,导致新进程不能创建。
-
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
-
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
-
system(通常缩写为sys),代表内核态 CPU 时间。
-
idle(通常缩写为id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
-
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
-
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
-
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
-
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
-
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
-
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
I/O问题:
工具:dstat 检查CPU和IO的工具
# 间隔一秒输出10组数据 $ dstat 1 10
I/O可以通过查看 iowait(wai)和对应的磁盘读(read)写(write)的联系,来判断是读或写出了问题。
# -d展示io统计数据 -p指定pid,间隔一秒输出三组数据 不加-p观察所有进程 $ pidstat -d -p PID 1 3
输出中 kB_rd/s表示每秒读的KB数,kB_wr/s表示每秒写的KB数,iodelay表示I/O的延迟(单位是时钟周期)
strace是最常用的跟踪进程系统调用的工具,在pidstat中拿到PID后使用strace命令,-p参数指定PID号:
strace -p PID
同样可以使用perf top/perf record -g/ perf report来查看进程调用。
直接读写磁盘适用于I/O敏感型应用(如数据库系统),大部分情况下需要通过系统缓存来优化磁盘I/O。
僵尸进程:
首先使用ps找到D状态的进程,使用pstree来查看父进程,检查父进程内子进程结束的处理是否正确,如是否调用wait()或waitpid(),也或是有没有注册SIGCHLD信号处理函数。
# -a 表示输出命令行选项
# p表示PID
# s 表示指定进程的父进程
$ pstree -aps PID
五、Linux软中断
中断其实是一种异步的事件处理机制,可以提高系统的并发能力。
为了减少对正常进程调度的影响,中断处理程序就需要尽可能快的运行。Linux将中断分为两阶段,上半部和下半部。
上半部用来快速处理中断,它在中断模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式来运行。每个CPU都对应一个软中断内核线程,名字为 ksoftirqd/CPU编号,如0号CPU对应的软中断内核线程为 ksoftirqd/0。
# 查看软中断的运行情况 $ cat /proc/softirqs # 查看硬中断的运行情况 $ cat /proc/interrupts


root@parallels-Parallels-Virtual-Platform:/home/parallels# cat /proc/softirqs CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 CPU8 CPU9 CPU10 CPU11 CPU12 CPU13 CPU14 CPU15 CPU16 CPU17 CPU18 CPU19 CPU20 CPU21 CPU22 CPU23 CPU24 CPU25 CPU26 CPU27 CPU28 CPU29 CPU30 CPU31 HI: 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 TIMER: 543452 496180 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 NET_TX: 37 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 NET_RX: 294516 50011 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 BLOCK: 113542 118787 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IRQ_POLL: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 TASKLET: 225 2956 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 SCHED: 393631 390735 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 HRTIMER: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 RCU: 445100 458732 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 root@parallels-Parallels-Virtual-Platform:/home/parallels#
注意点:
1. 中断类型,第一列的内容,软中断包含10个类别,分别对应不同的工作类型。如NEX_RX表示网络接收中断,NET_TX表示网络发送中断。
2. 同一种中断在不同CPU上的分布情况,正常情况分布应该差不多,但TASKLET在不同CPU的分布并不均匀,TASKLET是最常用的软中断实现机制,每个TASKLET只运行一次就结束,并且只在调用它的函数所在CPU上运行。
Linux软中断包括网络收发,定时,调度,RCU锁等。
使用 ps 命令就可以查看软中断内核线程:
root@parallels-Parallels-Virtual-Platform:/home/parallels# ps aux | grep softirq root 7 0.0 0.0 0 0 ? S 02:29 0:00 [ksoftirqd/0] root 16 0.0 0.0 0 0 ? S 02:29 0:00 [ksoftirqd/1] root 12801 0.0 0.1 21536 1040 pts/0 S+ 08:55 0:00 grep --color=auto softirq root@parallels-Parallels-Virtual-Platform:/home/parallels#
线程名字外面有中括号,说明ps无法获取他们的命令行参数(cmline)。一般来说,ps输出中,名字在中括号中的,一般都是内核线程。
软中断导致CPU使用率升高
工具:
sar,hping3,tcpdump
-
sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
-
hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
-
tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
软件:apt-get install sysstat hping3 tcpdump。
使用hping3来模拟客户端,这样可能会导致网络延迟加大,丢包率升高。
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80 # -i u100表示每隔100微秒发送一个网络帧 # 注:如果你在实践过程中现象不明显,可以尝试把100调小,比如调成10甚至1 $ hping3 -S -p 80 -i u100 IPxxxx:xx:xx:xx
# -n DEV 表示显示网络收发的报告,间隔1秒输出一组数据 $ sar -n DEV 1 Linux 4.15.0-96-generic (parallels-Parallels-Virtual-Platform) 04/19/2020 _x86_64_ (2 CPU) 11:21:41 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 11:21:42 AM veth3a80534 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11:21:42 AM enp0s5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11:21:42 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11:21:42 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-
第一列:表示报告的时间。
-
第二列:IFACE 表示网卡。
-
第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
-
第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
通过tcpdump来抓取网络包
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名 # tcp port 80表示只抓取tcp协议并且端口号为80的网络帧 $ tcpdump -i eth0 -n tcp port 80 15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0 ...
总结:
- 首先通过top 命令来分析,查看CPU负载和进程的CPU使用率。
- 通过查看/proc/softirqs 来查看各种软中断的次数,来分析导致的原因(watch -d cat /proc/softirqs)
- 如果怀疑是网络收发问题,通过sar命令来查看网络收发情况,可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的PPS(每秒收发的网络帧数)
- 观察网卡eth0的网络帧数和收发字节数,查看是否每个网络帧很小(BPS*1024/PPS,单位字节),如果很小,则是通常说的网络小包问题。
- 使用tcpdump 抓取eth0上的包,通过端口、网络协议来精确抓包。
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名 # tcp port 80表示只抓取tcp协议并且端口号为80的网络帧 $ tcpdump -i eth0 -n tcp port 80 15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
-
192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
-
Flags [S] 则表示这是一个 SYN 包。
- 加上PPS 数量很大,则说明这是来自192.168.0.2 的SYN FLOOD攻击
-
- SYN FLOOD攻击解决方法:在交换机或者防火墙中封掉来源IP,这样SYN FLOOD就不会发送到服务器上。