概述
朴素贝叶斯法是可以用于分类(二分类,多分类)任务。基于三大公式(条件公式,贝叶斯公式,全概率公式),算法首先学习训练数据集的统计特征,然后该统计特性输出测试样本的分类。
背景知识
- 条件概率公式及理解
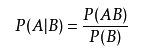
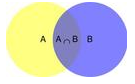
P(AB)为联合概率分布,即A,B同时发生的事件,对应途中的相交部分。P(A|B)表示,在B发生的条件下,A发生的概率,说白了,就是A,B相交的区域占B的多少?
2.全概率公式

其实全概率公式是一个分块的思想。也就是“知因求果,”举个例子:
A=[富,帅],B=好男人。那么一个男生他是好男人的概率P(B)是多少呢?
本例中,决定一个男生是否为好男人的因素有两个:富,帅。P(B|A=富)表示:在男生富的条件下,他是好男人的概率。P(B|A=帅)表示:在帅的条件下,他是好男人的概率。那么,一个男生是好男人的概率就可以拆分为两部分:因为“富”,所以是好男人 +因为“帅”,所以是好男人,两者的概率之和。
- 贝叶斯公式、
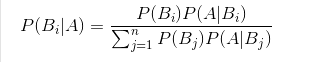
贝叶斯公式与全概率公式正好相反。全概率公式是“知因求果”,贝叶斯公式是“知果求因”,运用上面的例子,就是说 我现在已经知道男生是好男人的,但是他很有钱的概率是多少?这也可以根据条件概率公式跟全概率公式推导出来:
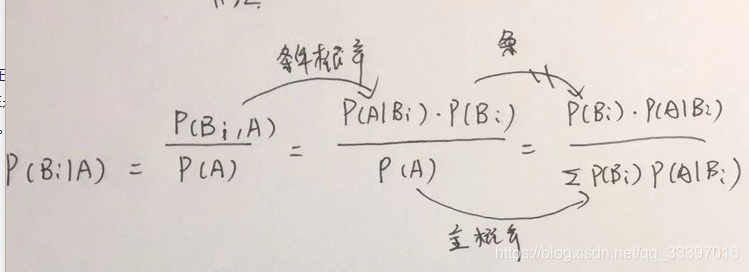
朴素贝叶斯算法
掌握朴素贝叶斯算法需要掌握以下几点:
- 朴素贝叶斯的强假设
- 朴素贝叶斯的思想和原理
- 参数估计方法
- 后验概率最大化的含义
朴素贝叶斯的强假设
朴素贝叶斯算法的理论基础是贝叶斯公式,他有一个强假设,即对条件概率分布坐了独立性的假设。
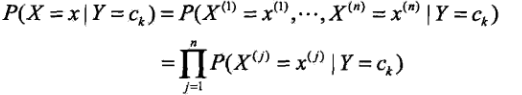
其中,X(i)可以理解为影响结果的每一个因素,条件概率分布独立意思就是每个因素相互独立,例如说 富不会导致你帅。
朴素贝叶斯的思想和原理
朴素贝叶斯的核心就是贝叶斯公式:
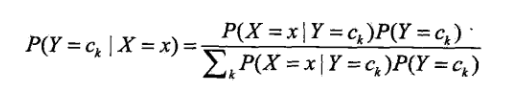
算法的学习过程就是从数据中统计出两个概率分布:
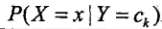
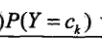
有了这两个分布,就可以通过贝叶斯公式算出
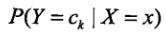
也就是在X是x因素的情况下,Y是ck这个label的概率是多少。最后通过最大化4.7式来确定测试样本点的分类
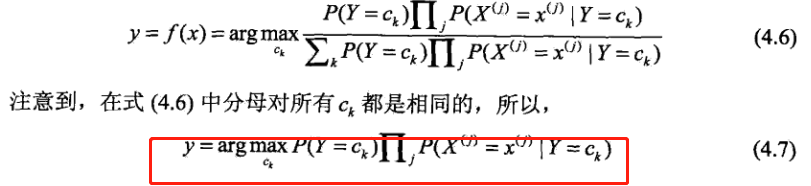
参数估计方法:
- 极大似然法
其实就是算占比 ,例如P(X=1|Y=1),先数Y=1的样本有多少个,在从这些样本中看看X=1的样本点占比是多少。这是最简单的情况,实际中会给出P(X|Y)的概率模型,如高斯等 - 贝叶斯估计
在极大似然法的基础上加上一个常数,防止出现概率为0的情况。
后验概率最大化的含义
为什么要最大化4.7式子?对应的是期望经验风险最小化,具体的推导看书啦,从直观上也很好理解,概率越大,可能性越大嘛。
代码分析

高斯朴素贝叶斯模型,这里算法是的学习过程就是通过训练样本计算出P(xi|yk)。
- 计算方差,标准差,高斯模型概率的函数:
def mean(X):
return sum(X) / float(len(X))
# 标准差(方差)
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
- 处理数据集:
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
注意这里求的是每一个X特征的期望和标准差,也就是一个样本对应一个期望,一个标准差。
- 模型训练:
# 分类别求出数学期望和标准差
def fit(self, X, y):
labels = list(set(y))
data = {label: [] for label in labels}
for f, label in zip(X, y):
data[label].append(f) # 对应的label 加入对象的特征量
self.model = { #整理出期望与方差
label: self.summarize(value)
for label, value in data.items()
}
print(self.model)
return 'gaussianNB train done!'
这里就是算出P(xi|yk)的过程,算完了模型也就是训练好了。
- 计算概率

def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i] #取每个向量,每个向量都有对应的期望和方差
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev)
return probabilities
- 预测分类

就是一个找最大值得过程。
# 类别
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(
self.calculate_probabilities(X_test).items(), #都算,取最大值
key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))
