今天我们简单谈下,多项式回归和Pipeline的应用。
之前我们了解了线性回归,线性回归的假设条件是:数据存在线性关系。并不是所有的数据具有线性关系。我们想要使用回归,可以对特征进行升维处理,转化成多项式回归。
一、多项式回归
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。多项式回归是线性回归模型的一种,其回归函数关于回归系数是线性的。其中自变量x和因变量y之间的关系被建模为n次多项式。
二、Pipeline
在使用sklearn建模时,我们可以考虑把简单的数据处理、特征处理、建模做成流水线的形式。此时用到Pipeline功能.
Pipeline就是将这些步骤都放在一起。参数传入一个列表,列表中的每个元素是管道中的一个步骤。每个元素是一个元组,元组的第一个元素是名字(字符串),第二个元素是实例化。
三、代码实现过程
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
poly_reg =Pipeline([('poly',PolynomialFeatures(degree=2)),
('scalar',StandardScaler()),
('lr_reg',LinearRegression())]
)
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
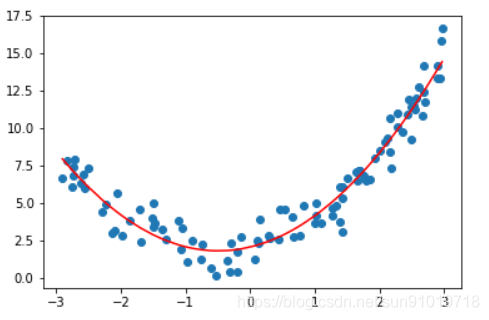
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
四、偏差和方差
模型误差 = 偏差 + 方差 + 不可避免的误差(噪音)。一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小。
偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系。例如某模型的准确度为96%,则说明是低偏差;反之,如果准确度只有70%,则说明是高偏差。
方差(variance):方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。通常在模型训练中,初始阶段模型复杂度不高,为低方差;随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。
偏差和方差的权衡关系:
 偏差和方差是无法完全避免的,只能尽量减少其影响。主要的挑战来自方差,一般处理高方差的方法有:
偏差和方差是无法完全避免的,只能尽量减少其影响。主要的挑战来自方差,一般处理高方差的方法有:
降低模型复杂度
减少数据维度;降噪
增加样本数
使用验证集
正则化
完整代码
参考文章:https://mp.weixin.qq.com/s/KnOZ2mK15G1w9fRZCVHJmQ
https://mp.weixin.qq.com/s/K_4DH7BC7jIF2-ltHBWGmA
