2.1 Perceptron Hypothesis set
问题:什么样的机器学习能解决是非问题?
问题:我们的H 到底长什么样子?

通过w来进行加权,然后看是否通过门槛值。红字h被称为'感知器'。perceptron
打个比方:就是数学题,权值是每个题的分数。这样60分就是阈值。
我们想要将threshold也当成一个特殊的W!

这样用两个向量就能很简单的表示出来了。注意w的第0个数字是(-threshold)。x0为正1,这样就在维度上进行了扩充。
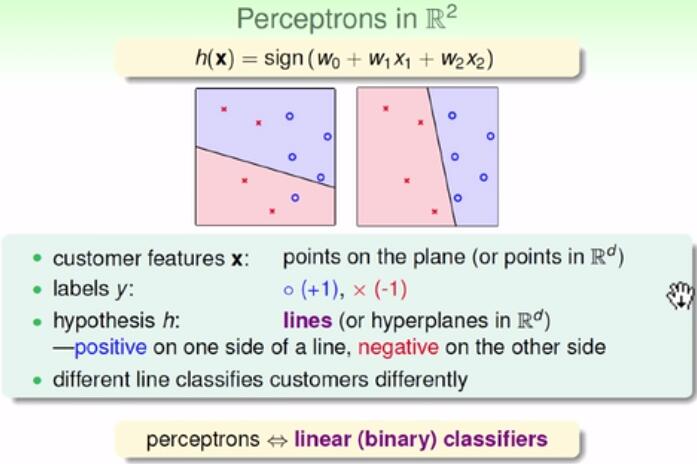
(x1,x2)映射到二维坐标平面,是一个点。而具体的值则表现为是圈圈还是叉叉。h则看sign里面的值为0使我们关心的,故为直线。
“感知器”又被成为线性分类器。
1.2 Perceptron Learning Algorithm
我们如何从这堆线中找到最理想的哪条?线是无线多条线,即H的集合是无限大。我们的想法是做越好,先犯错误,然后修正错误。

其中t表示迭代到第几轮。Wt是直线的权值向量。xn,yn是资料中的某一个点,将这个点带入直线后会出错(①中的不等于) 因为wt与xnt相乘,相当于是两个向量相乘,如果向量的夹角小于90度,则乘积结果为正,否则为负。然后进行修正就好。注意y的值的正负。②是两个向量Wt,Xn(t)的加减!!而ynt就是一个数值{-1,+1}。来通知修正。又被称为PLA(Perceptron Learning Algorithm)!!!
其中一种计算决定是否已经收敛的方法是循环一圈后是否还需要修正?这种检测的方法称为Cyclic PLA!!!
一些问题:1)一定会收敛嘛?2)假设停下来,我们的g 和 f 一不一样呢?

2.3 Guarantee of PLA
问:PLA什么时候会中止下来?答:存在一条线可分,即“线性可分” linear separable
注:wf是最终我们想要的值,而wt则是代表迭代到了第几轮的意思。由上文公式可以看出wt会不断迭代接近wf。因为乘积不断增大,而向量之间的乘积不断增大,意味着cos角度值在不断增大,两个向量越靠近。

yn之所以是灰色,在于其值是{-1,+1},平方后都是+1,因此无关。T代表错误的轮数有T轮。

问:PLA最多需要几次才会出结果?
答:两侧去极限,不等式的左边为1,右边解除T,就是T=1/constant^2
结论,本节证明了:两者不断接近,同时wt在不断增长。故最后一定能停下来,停下来的结果就是wf,我们正确的那条线。
2.4 Non-Separable Data
线性可分好处:快,简单,100维度都是差不多。
坏处:要假设线性可分,否则会停不下来。也不知道多久会停下来的。我们知道多久会听。PLA在真正使用会遇到很多的麻烦、
问:如果真的不是线性可分呢?怎么办?如果数据集中有杂音,怎么办?
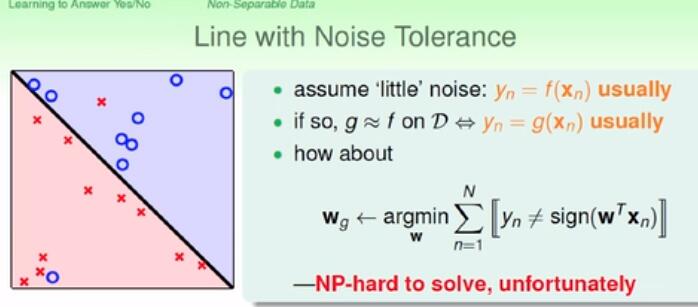
答:我们找一个犯错误的最少的一条直线。从所有的w中选择一条犯错误最少的。可惜这个问题的是NP-hard问题。没有什么很有效率的解法。
解法:我们使用贪心的方法,近似的求解。

类比小孩子采玉米,只看当前的玉米和眼前的玉米那个好,那个好要哪个。直到固定的迭代后就结束了。

Reference Answer:口袋演算法需要检查wt+1和w的好坏,每一轮中都要如此,故会比PLA(PLA不需要和之前的比较)要慢。在线性可分的情况下,两者最后都能达到最优。