4.1 Feasibility of Learning - Learning is Impossible

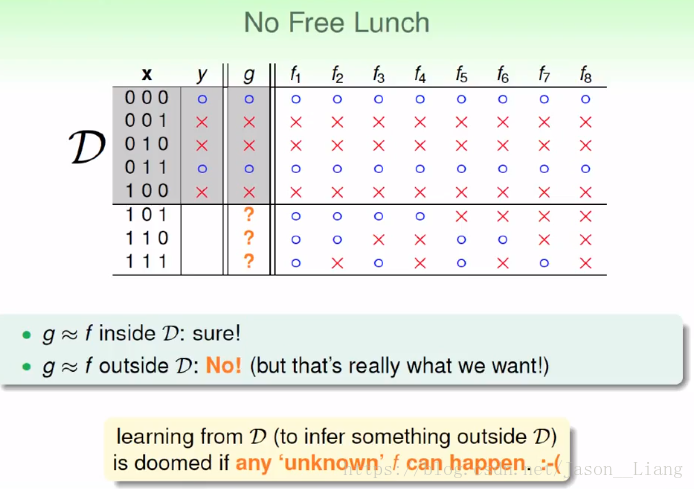
老师提出了一个难以学习的例子。我们无法知道未知的东西,但是我们想要推断未知的东西。
4.2 Feasibility of Learning - Probability to the Rescue
有什么工具对未知的 f 做一些推论???例如对瓶子里的弹珠颜色比例进行推论。
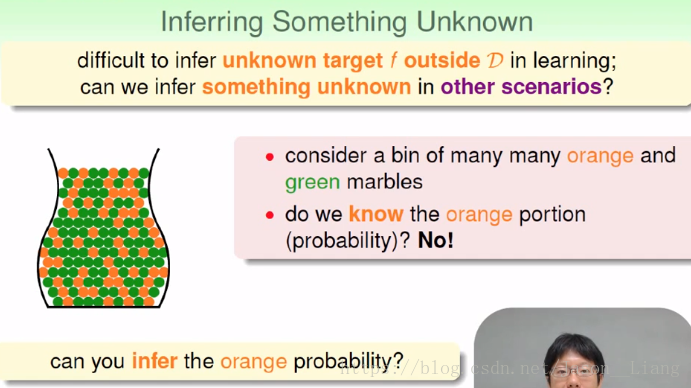
思路是进行抽样。引入了大数定律。证明了抽样是十分可行的一种方案。

probably 大概,approximately 大约。
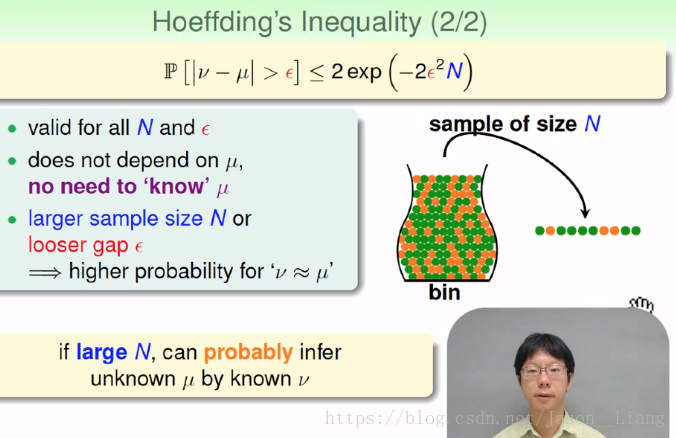
不依赖于初试分布状态 μ。我们本来就不知道。容忍度设的多一些,抽样数多一些,则越接近。

4.3 Feasibility of Learning - Connection to Learning
如下图,我们首先初试了一个 h ,通过抽样判断 h 是不是我们想要的。
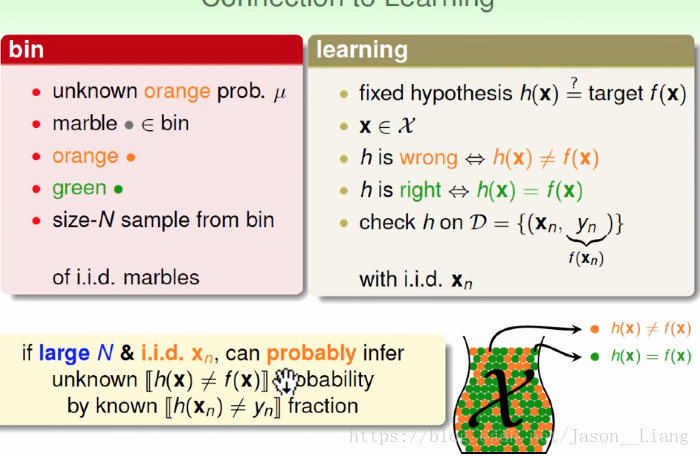

虚线表示我们不知道。我们就用手上抓的弹珠用来判断 h 到底和 f 一不一样?我们就可以用我们知道的东西来推断我们不知道的东西。

我们这种方法只能证明在Ein较小的时候,Eout的可能性也很小,h和f很接近。但是当Ein很大时,我们只能得到f和g很不接近。只能用来排除错误,没有真正的学习!故叫做Verification

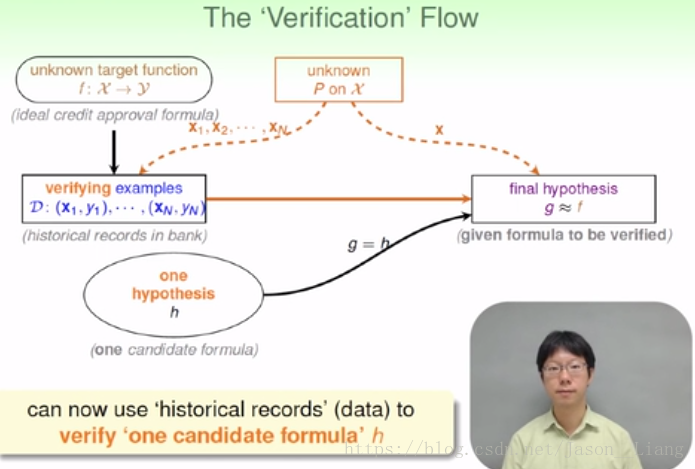
我们可以使用以往的记录来验证一些规则,来检验规则成立的可能性。
例如朋友告诉你了股市规则,你可以用以往的数据来进行验证。
4.4 Feasibility of Learning - Connection to Real Learning
我们又很多h,怎么办?假如有个h在我们的资料上全对,我们要不要选它?
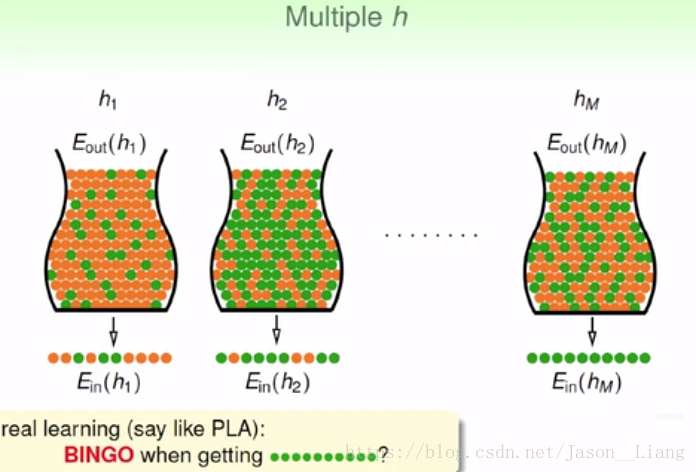
硬币游戏,假如我们的h假设是硬币只能是正面。150个人,有一个人5次全都是上面,我们接不接受正面???
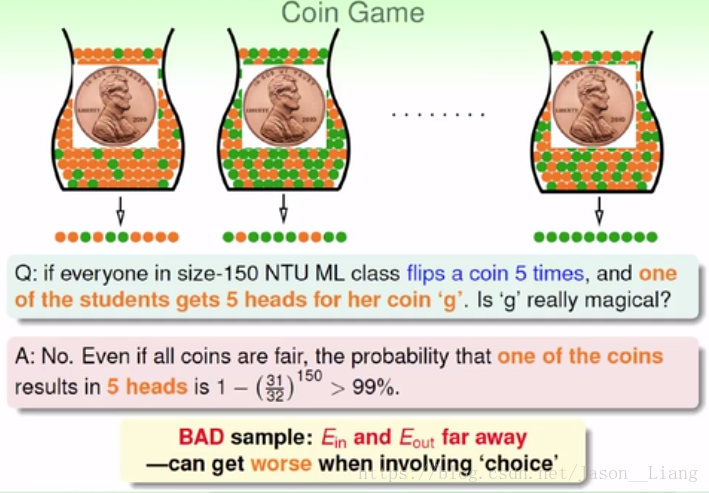
答案是不接受。我们会犯错误,偏见的错误,有选择的时候,不好的那种情形就很容易发生。我们很有可能恰好选择了哪一种极端分布的抽样,从而错误的验证了我们的假设、

我们判断好不好的方法是 Ein 和 Eout 一不一样。比如实际上硬币是均匀分布。但是我们恰好选择了5次全都正面的那个样本来检验我们的假设,往往会产生错误的判断。
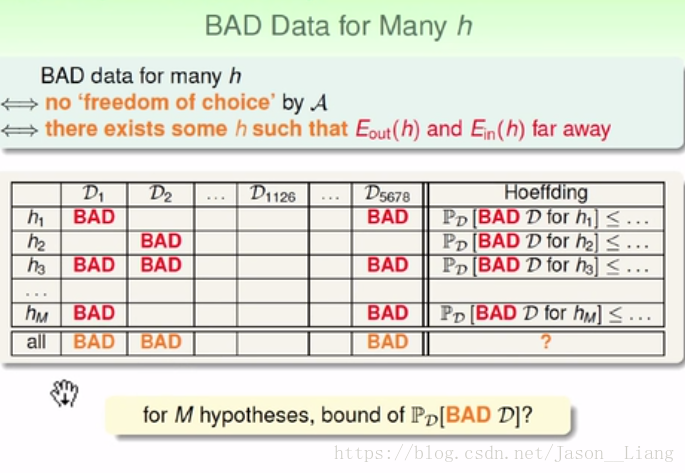
不好的数据《=》不能自由的选择《=》Ein 和 Eout 差很远
横排是各种假设,纵列是数据。bad说明是雷区,有雷区则不能采用这个数据集,因为只要有bad,我们很可能就对那同样一行的hi做出错误判断。

通过计算,我们得到了坏数据集可能的上界。我们最合理的选择是,选择一个 g ,这个g的计算Ein是最小的!
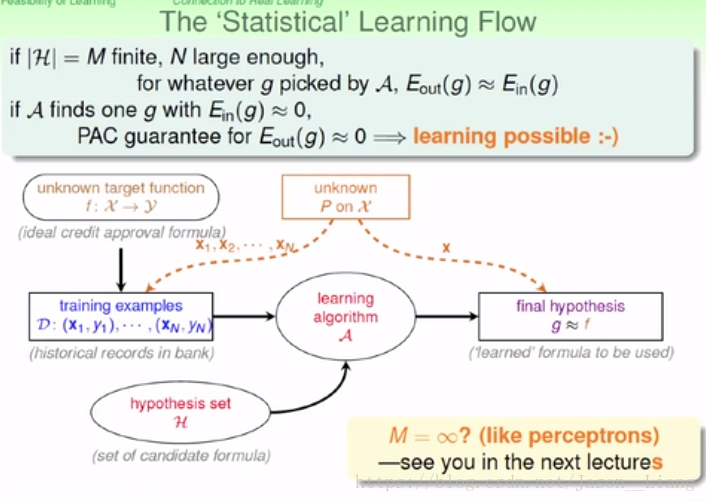
我们证明了在有限的 |H| 中,学习是大概率可行的。如果是无限的 |H|中呢?请看第五章。

机器学习的可行性,但只要加一些假设,比如统计学上的假设,就可以做到了。