3.1Learnig with Different Output Space
本节介绍了很多的机器学习问题。
是非问题可以用PLA。其实就是二分类的问题(binary classification)。是非题应用十分广泛。

从而引申到多类分类的问题。Multiclass Classification

二分类其实就是多分类时k=2。
回归问题典型,输出是一个实数。

自然语言处理:如果是一个单词,则是多分类问题。但是如果输入是一个句子,那么它是一个结构。可以相成一个很大的多分类问题,内部的结果很复杂。

总结:以上是在各种输出空间上的变化。
3.2 Learning with Different Data Label

监督学习:我们告诉了完整的信息。

分群问题,也成为聚类问题。聚类问题也称为无监督多类别分类。

看起来,我们机器学习的输入,可以不需要提前告诉一些信息,让计算机自己动。
例如density estimation 交通路口的密度分析。outlier detection 网络入侵检测。
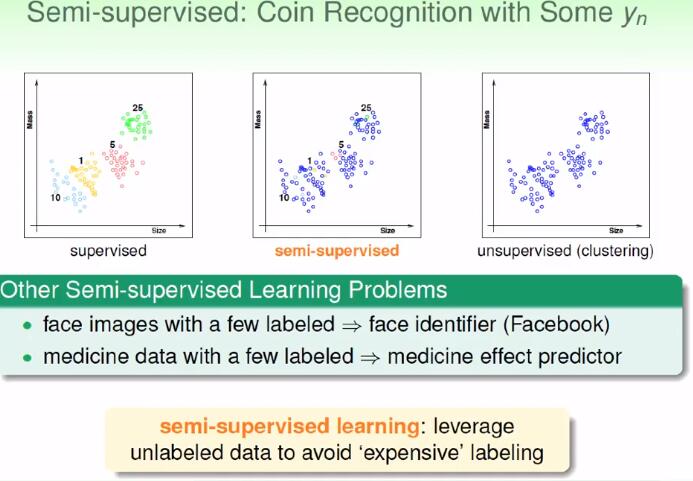
我们还可以给一部分的信息,即半监督式的学习。有时候我们无法知道的全部的label时的学习。

一种跟之上的学习方法不同的学习方法。强化学习。例如教宠物狗,我们不能直接教宠物狗学会“坐下”。但是当我们说“坐下”时,狗叫,则惩罚它;狗坐下,则奖励它。
注意,这里的输出并不是我们真的想要的输出,而是其他的输出。输出往往是序列发生的。
例如顾客的资料为输入,广告的点击为输出,有点击说明好,没有点击说明不好。这样广告就会自己学习到什么广告“好”了。
3.2Learning with Different Protocol
关键词:Batch Learning,最常见的一种与机器的沟通方式,喂给机器一批资料,然后让机器自己学习。


线上学习:资料是一轮一轮的来。而不是一批全给。比如垃圾邮件,不是一次全部收集后学习,而是一封一封的学习。核心是 g 经过每一次后,越变越好。

总结:batch learning 是填鸭式教育。online learning是老师教书一条一条的教。
以上都是被动的学习。学生不能问问题。
主动学习,让机器有问问题的能力。应用场合在获取label比较“贵”的场合,比如药物测试等等。如果能让机器有主动的问问题,能不能减少问问题的次数还能学习的很好呢?这就是主动学习的思想。
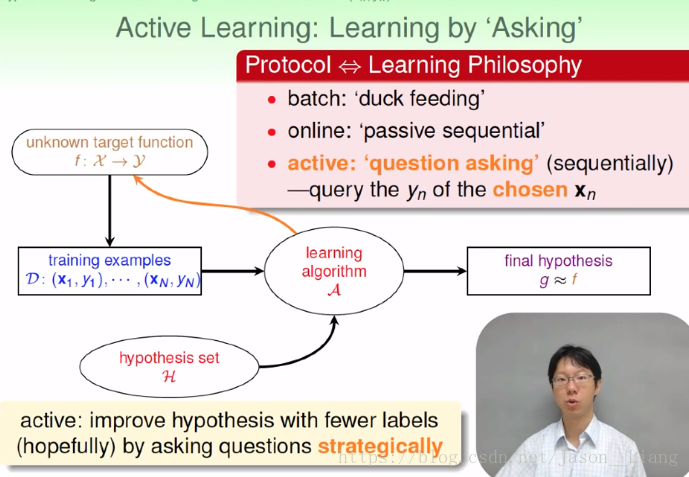
3.4 Learning with Different input space
我们以上的讨论大多与标记(输出)有关。本节讨论输出的问题。
输入又往往被称为features。具体信息是表示了 “富有经验的实际意义”。

人类的知识与经验先对数据进行了预处理,例如(size,mass)等等。使机器学习相对简单、

问题:手写识别输出图片,我们应该给机器什么样的输入信息?(不要直接思维定式,直接给个像素矩阵)

如果真的输入就是RAW FEATURES的话,我们需要“特征工程”,通过人的一些方法,将“生的”输入信息变成“熟的”(concrete)信息。当然如果是机器自己来做,就不叫特征工程了,叫深度学习。

更抽象了:没有或者很少的特征。

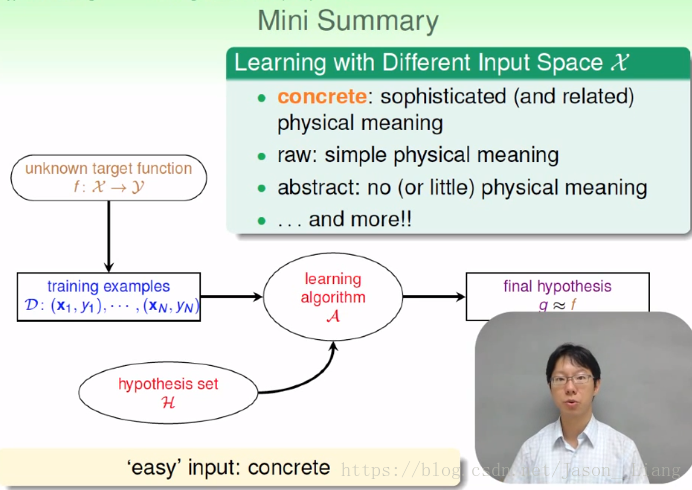
总结:
针对输出空间:分类、回归、结构
针对输入数据标签:有监督、无监督、半监督、强化
针对不同协议:成批,在线,主动
针对输入空间:具体,生的,抽象
