目标:
爬取以下网页内容,并存取到文件:

实现步骤:

产生步骤
步骤1:建立一个Scrapy工程
新建一个目录D:\pythontest\scrapy\pycodes,进入 目录,然后执行 命令 scrapy startproject python123demo
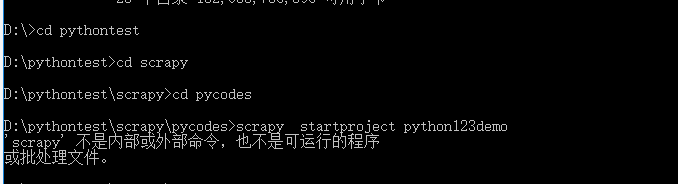
以上检测出并未安装 scrapy框架 :

D:\pythontest\scrapy\pycodes>scrapy startproject python123demo
New Scrapy project 'python123demo', using template directory 'd:\programdata\anaconda3\lib\site-packages\scrapy\templates\project', created in:
D:\pythontest\scrapy\pycodes\python123demo
You can start your first spider with:
cd python123demo
scrapy genspider example example.com
D:\pythontest\scrapy\pycodes>看到目录中生成了项目以及下面的文件:



下面逐一介绍目录文件以及其中包含子目录的作用:


步骤2:
在工程中产生一个Scrapy爬虫:
以下命令作用是生成一个 demo的 spider(爬虫)
D:\pythontest\scrapy\pycodes>cd python123demo
D:\pythontest\scrapy\pycodes\python123demo>scrapy genspider demo python123.io
Created spider 'demo' using template 'basic' in module:
python123demo.spiders.demo
D:\pythontest\scrapy\pycodes\python123demo>
demo.py的内容:
因为我们的spider名字叫 demo,所以这个类也叫demo
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io'] # python123.io 最开始提交给命令行的域名,指的是这个 爬虫在爬取网站的时候只能爬取这个域名以下的链接
start_urls = ['http://python123.io/'] #列表形式包含了一个或多个url,就是scrapy框架所要爬取页面的初始页面
#解析页面的方法(初始化时这里为空)
def parse(self, response):
pass
注意:parse()用于处理响应,解析内容形成字典 ,发现新的URL爬取请求。步骤3:
配置产生的 spider爬虫,需修改demo.py文件
按照我们的要求访问我们的链接对相关内容进行爬取
我们对 链接的解析部分,对于返回的HTML页面存成文件
需访问链接:
http://python123.io/ws/demo.html

然后更改爬取方法的具体功能,具体代码:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io'] 不需要 注释掉
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1] # 提取文件名保存为本地的文件名
with open(fname,'wb') as f: # 返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % name)
步骤4:
运行爬虫获取网页
命令行中进入目录python123demo 执行命令:
scrapy crawl demo # 用crawl命令来执行demo这个爬虫
D:\pythontest\scrapy\pycodes\python123demo>scrapy crawl demo
2019-12-12 02:16:39 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: python123demo)
2019-12-12 02:16:39 [scrapy.utils.log] INFO: Versions: lxml 3.7.3.0, libxml2 2.9.4, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.6.1 |Anaconda 4.4.0 (64-bit)| (default, May 11 2017, 13:25:24) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 17.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.17134-SP0
2019-12-12 02:16:39 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'python123demo', 'NEWSPIDER_MODULE': 'python123demo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['python123demo.spiders']}
2019-12-12 02:16:39 [scrapy.extensions.telnet] INFO: Telnet Password: 34478d1c14145d0f
2019-12-12 02:16:40 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-12-12 02:16:41 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-12-12 02:16:41 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-12-12 02:16:41 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-12-12 02:16:41 [scrapy.core.engine] INFO: Spider opened
2019-12-12 02:16:41 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-12-12 02:16:41 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-12-12 02:16:41 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/robots.txt> from <GET http://python123.io/robots.txt>
2019-12-12 02:16:41 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://python123.io/robots.txt> (referer: None)
2019-12-12 02:16:41 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/ws/demo.html> from <GET http://python123.io/ws/demo.html>
2019-12-12 02:16:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://python123.io/ws/demo.html> (referer: None)
2019-12-12 02:16:41 [scrapy.core.engine] INFO: Closing spider (finished)
2019-12-12 02:16:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 888,
'downloader/request_count': 4,
'downloader/request_method_count/GET': 4,
'downloader/response_bytes': 1901,
'downloader/response_count': 4,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/301': 2,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 0.476027,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 12, 11, 18, 16, 41, 734011),
'log_count/DEBUG': 4,
'log_count/INFO': 10,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2019, 12, 11, 18, 16, 41, 257984)}
2019-12-12 02:16:41 [scrapy.core.engine] INFO: Spider closed (finished)
D:\pythontest\scrapy\pycodes\python123demo>捕获页面存储在demo.html页面中:

HTML内容如下:
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>代码分析:

实际上上面是简化版代码:


完整的demo.py

所有启动url通过列表形式。
