在了解B+Tree之前,先简单介绍一下B Tree。
**B Tree:**数据库设计者,把数据存放到节点以树的形式存储,把节点的大小设置为一个页,那读取一个节点就需要一次I/O操作,如果一次检索需要访问四个节点,根节点常驻内存,那么完成这次检索,需要三次io。
那么数据越小,每页存放的数据就越多,树的高度就越小,io就少,检索就快。
索引就利用上面的性质,设计成B+tree。
**B+tree:**非叶子节点只存放key,叶子节点存放data,并且叶子节点存在指向相邻叶子节点的指针
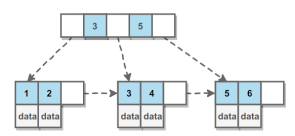
这样一方面非叶子节点可以存放更多的记录,树更矮,io就少,另一方面,可以通过顺序指针提高区间查询的性能。
MySQL中普遍使用B+Tree做索引,但在实现上又根据聚簇索引和非聚簇索引而不同。
-
聚簇索引(主键索引树)
所谓聚簇索引,就是指B+Tree的叶子节点上的data就是数据本身,key为主键,如果是一般索引的话,data便会指向对应的主索引。 -
非聚簇索(非主键索引树)
非聚簇索引就是指B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。
非聚簇索引比聚簇索引多了一次读取数据的IO操作,所以查找性能上会差。
因为主键索引树的叶子节点直接就是我们要查询的整行数据了。而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再进行一次查询,这个过程叫回表。
